New V2.1, for LTXV 13B 0.9.7 Distilled!
I updated this to work with 0.9.7. I also added all the optimization nodes that help it go faster. I fixed the Add Details, and added an extend section and cleaned a lot up. Also added a MMAudio group to generate sounds based on the video. All have easy toggle switches and lots of notes.
I've played around with some samplers and schedulers.
I found a combination of these tend to work well:
STG Advanced presets: Custom
Samplers: Euler, Euler_a, LCM
Schedulers: Beta, Simple
I recently noticed the Simple scheduler smoothed out jumpiness a lot
Note: On the upscale, you kind of need to play with the sigmas manually. Because they stay high most of the time with 8 steps, taking the last 3 doesn't work well. You need to pick 3 values between 0.90 and 0.75 to get it working well.
Please add comments if you find really good combinations.
V1
Someone shared this on reddit:
https://civitai.com/articles/13699/ltxvideo-096-distilled-workflow-with-llm-prompt
And I looked at it and liked most of it, but it wasn't using the latest nodes for some things and there were some LLM issues. So I cleaned it up and added a captioner. Then I added some super easy toggles to you can disable anything you don't want to use and go strictly with T2V with or without a LLM or even just the captioned text of another image. Or full I2V and passing the image caption to the LLM, or just I2V with no caption or LLM.
It uses florence-2 for captioning with this fine tune I found that is very good at captioning NSFW: https://huggingface.co/MiaoshouAI/Florence-2-large-PromptGen-v2.0
I just added TeaCache too. It doesn't seem to make much of a difference on the Distilled model with 9 steps, but it saved about 40% or more on the base model at 30 steps.
There's also notes on what Scheduler/Sampler settings to change if you want to use the distilled or base model, it's set up for base model by default.
I also found that the T5xxl FP8 works fine, I ran some comparisons between the FP16 and FP8 and I preferred the FP8 actually.
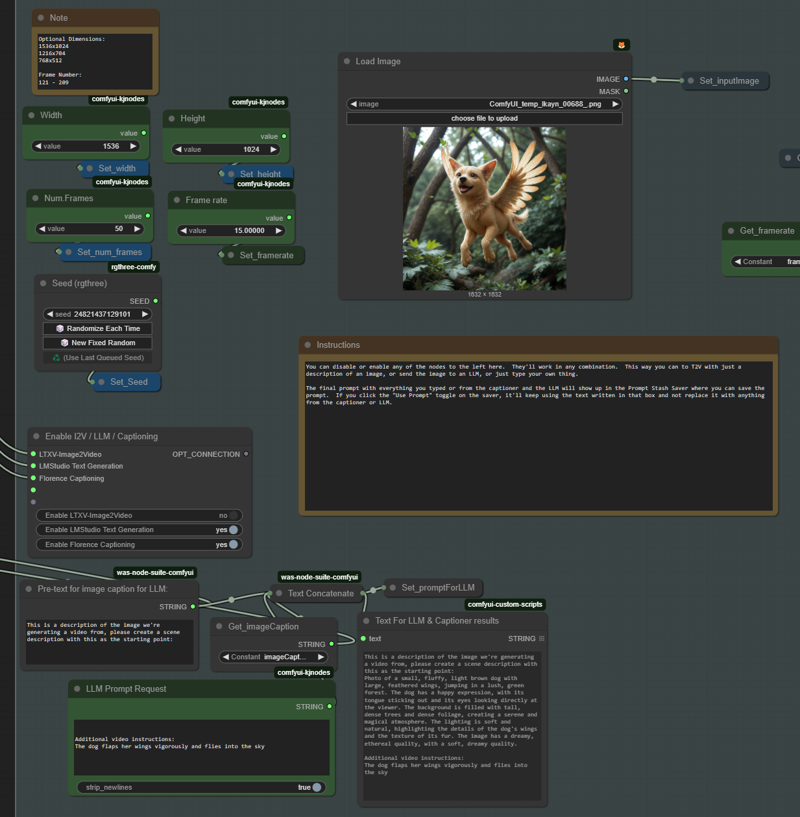
No clue why it didn't wrap the text on the export screen capture?: