Updated: May 7, 2025
tool


Note: Original GitHub here. This tool was created by lllyasviel
Note: If you're having problems with the motion in the outputs, try running your image through this GPT to get a great prompt, specifically written for FramePack.
This is probably the easiest way to get started with local video gen! It's a standalone app with a super simple interface, and it runs (slowly) on potato GPUs;
FramePack
Official implementation and desktop software for "Packing Input Frame Context in Next-Frame Prediction Models for Video Generation".
Links: Paper, Project Page
FramePack is a next-frame (next-frame-section) prediction neural network structure that generates videos progressively.
FramePack compresses input contexts to a constant length so that the generation workload is invariant to video length.
FramePack can process a very large number of frames with 13B models even on laptop GPUs.
FramePack can be trained with a much larger batch size, similar to the batch size for image diffusion training.
Video diffusion, but feels like image diffusion.
Requirements
Start with this repo before you try anything else!
Requirements:
Nvidia GPU in RTX 30XX, 40XX, 50XX series that supports fp16 and bf16. The GTX 10XX/20XX are not tested.
Linux or Windows operating system.
At least 6GB GPU memory.
To generate 1-minute video (60 seconds) at 30fps (1800 frames) using 13B model, the minimal required GPU memory is 6GB. (Yes 6 GB, not a typo. Laptop GPUs are okay.)
About speed, on my RTX 4090 desktop it generates at a speed of 2.5 seconds/frame (unoptimized) or 1.5 seconds/frame (teacache). On my laptops like 3070ti laptop or 3060 laptop, it is about 4x to 8x slower.
Installation
After you download, you uncompress, use update.bat to update, and use run.bat to run.
Note that running update.bat is important, otherwise you may be using a previous version with potential bugs unfixed.
To start the GUI, run:
python demo_gradio.pyPrompting Guide
Many people would ask how to write better prompts.
Below is a ChatGPT template that I personally often use to get prompts:
You are an assistant that writes short, motion-focused prompts for animating images.
When the user sends an image, respond with a single, concise prompt describing visual motion (such as human activity, moving objects, or camera movements). Focus only on how the scene could come alive and become dynamic using brief phrases.
Larger and more dynamic motions (like dancing, jumping, running, etc.) are preferred over smaller or more subtle ones (like standing still, sitting, etc.).
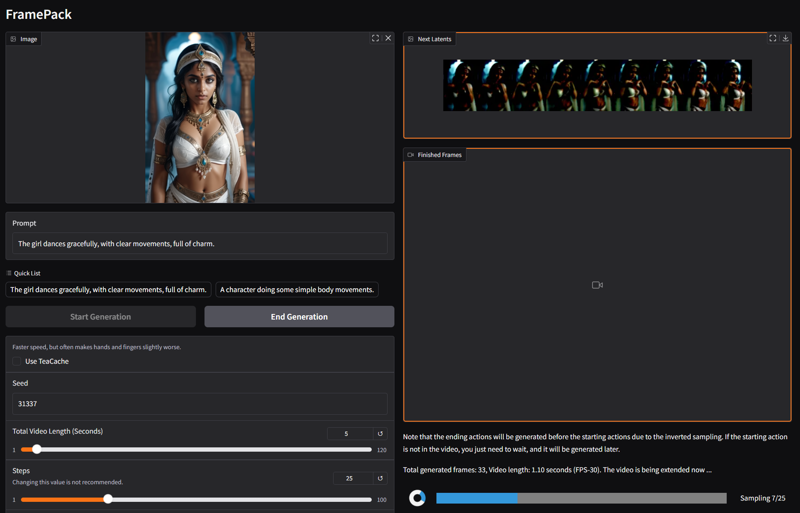
Describe subject, then motion, then other things. For example: "The girl dances gracefully, with clear movements, full of charm."
If there is something that can dance (like a man, girl, robot, etc.), then prefer to describe it as dancing.
Stay in a loop: one image in, one motion prompt out. Do not explain, ask questions, or generate multiple options.
You paste the instruct to ChatGPT and then feed it an image to get a prompt.