Create
86
2.3k
72
0
Updated: Oct 3, 2025
Download
1 variant available
Archive Other
InfiniteTalk_Single_Speaker_TK.zip
11.21 KB
Verified: 10 months ago
Download (11.21 KB)
1,5030 1 2 3 4 5 6 7 8 9,0 1 2 3 4 5 6 7 8 90 1 2 3 4 5 6 7 8 90 1 2 3 4 5 6 7 8 9
(52)
Sep 27, 2025
Wan Video 14B i2v 720p
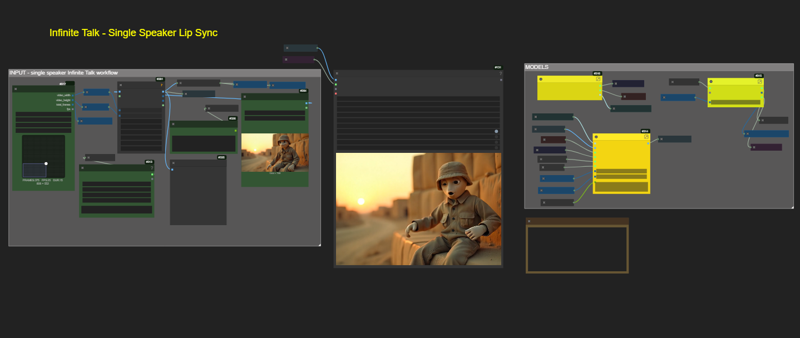
Major change over to use Infinity Talk. Workflow has been completely revamped, based on Kijai workflow.
1200 1 2 3 4 5 6 7 8 90 1 2 3 4 5 6 7 8 90 1 2 3 4 5 6 7 8 9
2510 1 2 3 4 5 6 7 8 90 1 2 3 4 5 6 7 8 90 1 2 3 4 5 6 7 8 9
trashkollector175
Joined Feb 6, 2025
License:
👍
110 1 2 3 4 5 6 7 8 90 1 2 3 4 5 6 7 8 9
❤️
40 1 2 3 4 5 6 7 8 9
00 1 2 3 4 5 6 7 8 9
Switched over to InfiniteTalk model
Please note : this version uses subgraphs, please update your UI if necessary.
No spaghetti nightmare -- like some workflows.