

Qwen Image Edit ComfyUI Workflow: Basic Description
This workflow demonstrates how to use ComfyUI for image editing with the Qwen model, focusing on style transformation and conditioning via text prompts. Below you'll find a structured overview of the process: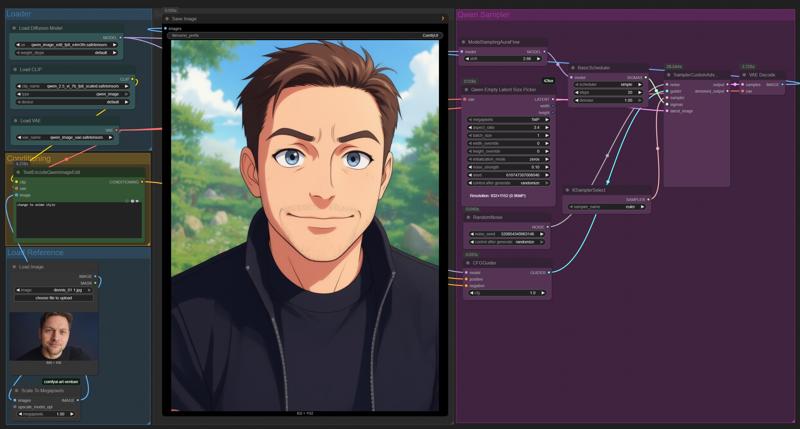
1. Loader Section
Load Diffusion Model: Select and load a Qwen image edit diffusion model from the available options. This model is responsible for generating and editing images based on provided instructions.
Load CLIP: Load the CLIP model, which is needed for image-text conditioning. It links your text prompt to specific visual features in the image.
Load VAE: Load the Variational Autoencoder (VAE) model to decode latent image representations back into viewable images.
2. Conditioning Section
Text Conditioning: Use the
TextEncodeQwenImageEditnode to input your prompt (e.g., "Change to anime style"). This allows the workflow to modify the image according to the textual description you provide.Image Reference: Load the original image to be edited. You can optionally provide a mask for targeted editing.
3. Preprocessing
Scale to Megapixels: Scale the reference image to a target megapixel size to ensure the output resolution matches your requirements.
4. Sampler Section
Latent Size Picker: Define the output size (resolution) and other sampling parameters such as strength and seed, which influence randomness and consistency.
Scheduler and Sampler Selection: Configure the scheduler and sampler. Common settings include:
Scheduler: Controls the number of steps and strength of denoising.
Sampler: Select a suitable algorithm (e.g., Euler) for the sampling process.
5. Generation Nodes
Random Noise: Initialize the process with random noise, consistent with the chosen seed.
CFG Guider: Guide the process toward the target image based on the CLIP conditioning and prompt.
6. Decoding & Output
Sampler & Decoder: The generated latent image is decoded by the VAE, transforming it into a final visual output.
Save/Export: Save the resulting image for further use or sharing.
This workflow enables flexible image editing by leveraging diffusion models conditioned on text prompts within an easy-to-follow, node-based interface. The modular structure allows customization at each step for a wide range of creative and technical applications.