Updated: Jul 8, 2026
base model

Seedream 4.5 - now with 4k resolution at no extra cost!
Check out the extremely useful Official Guide to prompting Seedream 4.5, from Bytedance!
Details below originally posted to: https://seed.bytedance.com/en/tech/seedream3_0
Technical Innovation
Compared with our previous model Seedream 2.0, we employ several innovative strategies to address existing challenges, including limited image resolutions, complex attributes adherence, fine-grained typography generation, and suboptimal visual aesthetics and fidelity.
This is primarily reflected in the following four aspects:
• At the data tier, the dataset scale was expanded by approximately 100% with a novel dynamic sampling mechanism operating across two orthogonal axes: image cluster distribution and textual semantic coherence.
• In the pretraining stage, we implement several improvements compared to 2.0, resulting in better scalability, generalizability, and visual-language alignment: i) Mixed-resolution Training; ii) Cross-modality RoPE; iii) Representation Alignment Loss; iv) Resolution-aware Timestep Sampling.
• During post-training optimization, we leverage diversified aesthetic caption and VLM-based reward model to further improve model’s comprehensive capabilities.
• In model acceleration, we encourage stable sampling via consistent noise expectation, effectively reducing the number of function evaluations (NFE) during inference.
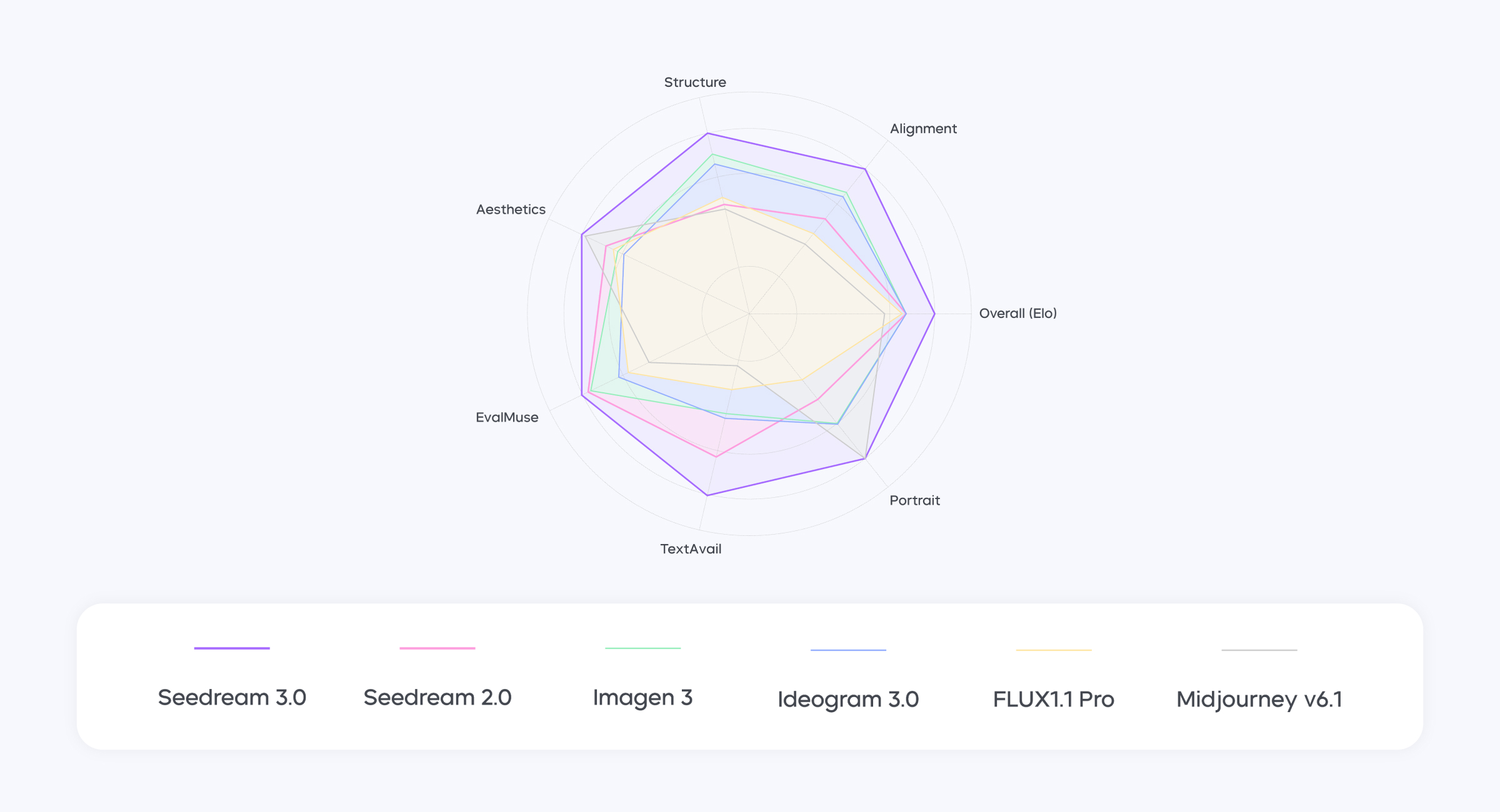
Figure 1 Seedream 3.0 ranks first in the Artificial Analysis Image Arena Leaderboard. Due to missing data, the Portrait result for Imagen 3 and the Overall result for Seedream 2.0 are represented by the average values of other models.
Iterative Model Performance
Compared to Seedream 2.0, Seedream 3.0 achieves significant breakthroughs across multiple dimensions:
• Native High Resolution: Natively supports 2K resolution output without post-processing, while also being compatible with higher resolutions and adaptable to various aspect ratios.
• Comprehensive Capability Enhancements: Demonstrates significant improvements in text-image alignment, compositional structure design, aesthetic quality, and text rendering capabilities.
• Significant Text Rendering Performance Enhancements: Excels in small font generation, Chinese character accuracy, and high-aesthetic long-text layout. The model tackles industry challenges in small-text generation and long-text layout, with graphic design outputs surpassing manually designed templates from platforms like Canva. Leveraging precise and aesthetically refined text generation capabilities, it enables the effortless creation of designer-level posters, seamlessly integrating diverse fonts, styles, and layouts.
• Aesthetic Improvements: Achieves significant enhancements in image aesthetic quality, delivering strong performance in cinematic scene rendering and generating portraits with more realistic textures.
• Lightning-Fast Generation Experience: Through multiple innovative acceleration technologies, inference costs are significantly reduced. End-to-end generation of 1K resolution images now takes only 3.0 seconds.
Figure 2 Human evaluation results.Seedream 3.0 surpasses other models in terms of image-text matching, structure, and aesthetics.