Verified: 2 months ago
SafeTensor


The FLUX.1 [dev] Model is licensed by Black Forest Labs. Inc. under the FLUX.1 [dev] Non-Commercial License. Copyright Black Forest Labs. Inc.
IN NO EVENT SHALL BLACK FOREST LABS, INC. BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH USE OF THIS MODEL.
This is an experimental instruction-edit LoRA for Flux.2 Klein intended to improve the visual quality of images that were produced by the Qwen-Image VAE decoder (i.e. any image made with any version of Qwen-Image or Qwen-Image-Edit using the default VAE).
Qwen-Image's VAE produces noticeably washed out details and a checkerboard noise pattern. By leveraging the Flux.2 VAE, which is able to produce higher-fidelity images, these issues can be fixed to some extent.
I would recommend starting with cfg at 1.0 as a baseline. Pushing cfg past 3.0 seems to result in an increasing amount of artifacts.
❗ This is not intended to be a general purpose detailer. It expects input images with typical Qwen-Image VAE artifacts and may produce poor results on other images. This includes images generated with Qwen-Image models using e.g. the Wan2.1 upscale2x VAE instead of the default VAE. ❗
Training
The LoRA was trained on a selection of 1024x1024 photos before and after being encoded and decoded with the Qwen-Image VAE with no changes made to the latent as illustrated in this workflow:
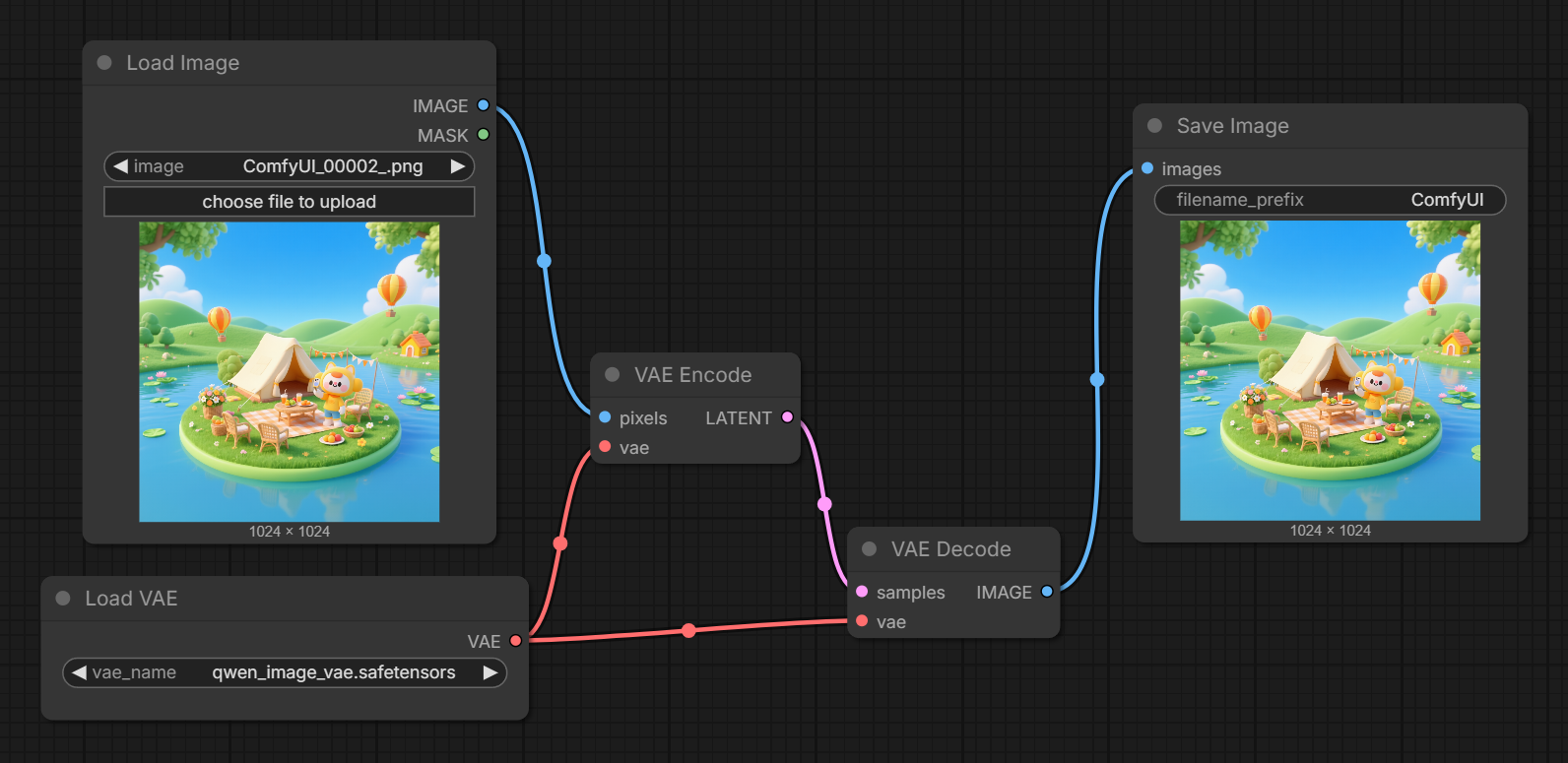
Version 1.0 was trained on a dataset of 23 image pairs, mostly focused on skin, faces/hair, and vegetation. There is likely room for improvement with a more diverse dataset, but it's hard to say how much.