Download
2 variants available
fp16 SafeTensor
indigo_Furrymix_v105_hybrid_fin_fp16.safetensors
Half precision, best balance (pruned) • 1.99 GB
Verified: 3 years ago

6K
17.1K


, (red body_1.1), yellow belly, (standing_1.3), (kemono_1.2), (tavern_1.23), hea.jpeg)
V120_hybrid is gonna be the last model of this series, there will be no more hybrid, anime or realistic models, I will only update the vpred models, Thank you for liking my model and supporting me!!!
I AM A LAZY DOG XD so I am not gonna go deep into model tests like I used to do, and will not write very detailed instructions about versions. Plz understand, read 'about this version' and try them yourself, then decide whether to use them / choose which model to use by your preference.(I mix models for fun, you use them for fun xd)
V90 artist styles here:https://mega.nz/folder/NxJBWKpS#LZFVyOyvgFIAj2307-GDkQ
V105 artist styles here:https://mega.nz/folder/FoQR1RgA#gDLJyJe9-JK2_FDaosgSzg
If you like my work, consider buy me a coffee please <3 (completely voluntary)
声明:我只有在c站,hugging face和被迫在海艺AI上发布了我的模型,本模型完全开源不会收费,第三方网站收费与我无关()(但是欢迎给我打赏 ,完全自愿,不强求QAQ)
Indigo Furry mix (seaart.ai) They have returned the rights to my model to me, now this model is on seaart.ai (forced xd), using this model is completely free but you may need to pay for the third-party generation service.
现在海艺AI上的账号是我了()
As for XL based models, I think I’ll wait for SDXL to become more stable (waiting for fluffyrock xd), just wait a little longer.
请勿对号入座,只是吐槽:(吃瓜区)
(有一些人挺不要脸的,我没技术是吧,瞎混模型是吧,没有强求你用。但在这之前确认一下你没有偷别人的模型还蹭鼻子上脸?本来就是开源分享的东西搞这一天天的,不累吗。)续:hhh笑死我了,某个‘pytouch’大神跑遍了‘CDSN’、github问了上百遍GPT才写出来七八十行的代码,能不能把单词打对?即便你真的参与了stable tuner编写(我不信),难道全部代码都是你写的?还有你到底理解了什么叫开源协议吗?你往一条河里撒尿,然后叫嚣着“啊这条河是我的私人厕所你们都不许用”,不觉得好笑吗?何况我根本没有使用过你的训练脚本,这个模型是混合模型,甚至不存在训练过程,原理是Clip unet融合。综上所述,我很难评。谁更无耻,清者自清。(哦对,最后我的模型就放在这里,开门见山,凭君使用,不像某些人不知道咋回事完全没有成果呢,github和c站抱脸链接都不敢放,他本人说是上传模型 TOO SLOW!然后就放弃了hhhh)好像那个小学生或者初中生,真的是AI福瑞圈狮忆(建议各位老爷尊重祝福远离
以及接下来我都不会理你了,感觉是浪费时间,你就和你的提纯粉丝一起沾沾自喜吧,祝你的奥特曼佛祖模型成功(hhh绷不住了怎么会有那么逆天的名字)
(我是有写在描述里,还有开源协议里,这模型不能商用的吧?但我知道,有些人不听劝阻,至今还在私自出图商用,还是直出,错误都没有修改的那种。)
(并且,对于AI,我个人觉得是好用的工具,AI的功能不止有出图,可以说是万能图片处理程序,把它当成工具用不香吗?但我知道,有些人视AI为洪水猛兽、智械危机,不想学习新兴事物,喜欢云别人的同时,抢占道德高地,乱给别人扣上名为‘优越感’的帽子。我真心为他们觉得不值得,也为我自己觉得不值得。)
------------------------------------------------------------------------------------------------------
YOU WILL SEE THESE IN THIS PAGE:
Male focus, NSFW.
Bara/yaoi/gay content, male dragons/furries content.
(All models can do females, it's just that I didn't specially tweak these models for females)
------------------------------------------------------------------------------------------------------
Anime: v115&v100 / Realistic: v110 v95&v80 / Hybrid: v120 v90&v75 (Recommanded) Extra:SE01_vpred
These three variations are very different, please read the description below and also ‘about this version’, it's not that the higher version number, the better.
Hybrid: (The most versatile model, Best for NSFW) (also SE01 is similar to hybrid models)
V120/V105/V90/V75/V60/V45 can replace V30, don't use V30, V16 is still usable.
Anime: (For fancy anime looking)
V115 is unique, V100 and V85 are basically the same, V70 and V55 are relatively similar. There are 2 versions for v55, you can use one or all of them, v40 is not good enough imo, V25 is usable.
Realistic: (For realistic or photorealistic/3D)
V110/V95/V80&V50 can replace V20, V65/V35 is usable.
(中文:本模型有三个大类,这三个大类的模型侧重点不太一样。请阅读“关于此版本”,里面有版本的中文介绍。可以往下拉用翻译看看"For xx"的版本描述。版本与版本之间并不是简单迭代,而是完全不一样,使用方法也略有不同,无法通用,请注意!)
通用模型:(通用模型,最擅长涩涩)(还有个SE01和通用模型差不多用法)
v120/v105/v90/v75/v60/v45可以平替v30,别用v30,v16还能可以用用。
动漫风:(纯纯为了一眼好看的动漫风)
v115很独特,v100与v85几乎一毛一样,v70和v55比较类似,v55有两个版本可以挑选,v40不是很好个人觉得,v25可以用。
真实风:(为了写实、照片写实和3D)
V110/v95/v80和v50可以平替v20,V65/v35可以用。
(如果你第一次接触AI绘画,我建议你使用v16)
(喜欢哪个模型用哪个)
------------------------------------------------------------------------------------------------------
AND Please add AI tag if you post images on media!
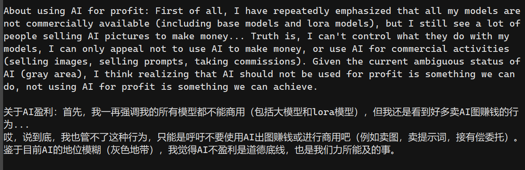
(The images generated by AI are currently in a gray area. Since the training dataset has not been authorized, the dataset is not so clean. These generated images are for personal usage only. Please do not use them for commercial purpose, including merges using this model, thank you!)
(出图切勿商用,包括混入此模型的混模也切勿商用!谢谢!)
------------------------------------------------------------------------------------------------------
Since version v20, models had been renamed to indigo_Furrymix. (This model used to be named indigo_maledoragoon_mix, but they are the same.)
Choose fp16 or fp32 versions by your preferences.
All models are baked with VAE, but you can use your own VAE.
uhralk/Indigo_Furry_mix at main (huggingface.co)
( Hugging Face link here if you need.)
If you have any questions, please comment in the discussion. (ENG or 用中文问我问题)
Because v16 is my personal favorite during the testing, so I will compare many models with v16, please understand xd.
------------------------------------------------------------------------------------------------------
UPDATE:
For v115:
This is an anime model with a little Niji6 style (but it may a failure depends on how you look at it), it's not very niji6, has a weird style (compared with other anime models).
This model has crazy color and contrast (but sometimes it's too yellow xd), but it's not that crisp clear as v100, and tag accuracy/responsiveness will be worse than v100 (for example it may struggle to do white wolves or tends to generate characters with clothes).
Clip skip = 1.
------------------------------------------------------------------------------------------------------
For v110:
This time the version v110 pays more attention to versatility rather than photorealistic style, compared with v80/v95, it is less photorealistic (but in some cases it is possible to do something very photorealistic), will react to artists tags (but it may not be able to completely replicate the artist styles). It's like a realistic version of hybrid models.
May not be as stable as hybrid models, and it's not that versatile as hybrid models.
Clip skip = 1.
------------------------------------------------------------------------------------------------------
For SE01:
This is SE01_vpred, a test v-prediction model, it’s similar to hybrid models but with higher color saturation and contrast, it can do almost pure black images xd. It is also more stable, does better tails than hybrid models(but not always xd). It seems to be more versatile in styles, too.
Personally I think using this model is very weird compared to hybrid models(I'm still not getting used to vpred models xd), and sometimes it has less details than hybrid models, also some people may not like its crazy contrast and high color concentration xd.
Remember to download .yaml config file and place it alongside the model files, rename the config file name to be the same as the model name.
Try not to use boring_e621_fluffyrock_v4 with this model plz bc it may blur the image outputs.
Use CFG rescale extension plz, with a value of 0-0.5(but I think it’s ok to not use it xd)
Clip skip = 1.
------------------------------------------------------------------------------------------------------
For v105:
This is a tweaked model similar to v90, compared with v90, its colors are more vivid, has more details, and the realistic style is better, but it may not be as good as v90 when doing some certain images xd
Hybrid models are basically Fluffyrock models with better details and (often) weaker NSFW abilities compared with original rock models. They are the most versatile models in this series of models, can do most content and styles.
Use e621 tags, use less danbooru tags plz.
When using hybrid models, add artists to prompts plz.
Use embeddings as negative prompt plz, but you don’t need to use a lot of them xd
Clip skip = 1 (try not to use 2 plz).
------------------------------------------------------------------------------------------------------
For v100:
This is v100_anime, a very similar tweaked version of v85, this model is basically v85 with flatter color, this model is as stable/unstable as v85, and the hands are still bad :(
This is another average model xd
Clip skip = 1 or 2.
------------------------------------------------------------------------------------------------------
For v95:
This is a tweaked version of v80 with a little difference. It is similar to v80, with even more fur, brighter colors and lower contrast (so that this model will not look so dark fantasy like v80 xd).
But this version has fewer details, feels less stable than v80, also there may be too much fur that sometimes dragons/aquatics will have fur xd.
Clip skip = 1.
------------------------------------------------------------------------------------------------------
For v90:
Based on v75_extra, v80, v85, and yiffymix34.
This is a test model with traindiff, should be better than v75?
Nothing much to say about hybrid models, they are basically Fluffyrock models with better details and (often) weaker NSFW abilities compared with rock models.
(Recommended) add artists to prompts.
(Optional) you can use WD-KL-F8-Anime2 vae to get more colorful images.
Clip skip = 1.
------------------------------------------------------------------------------------------------------
For v85:
Based on v70, v75 and indigokemonomix beta.
This is an alternative version of v70, it’s like v70_nsfw, which is better at doing nsfw than v70, but losing anime style and may not be that crisp clear as v70.
Could be a little unstable, images may be dim and not very colorful.
Clip skip = 1 or 2.
------------------------------------------------------------------------------------------------------
For v80:
Based on v65, v50, and bm lora.
An improved version of v65, it might be better than v65 imo, (70% outputs are better xd) but may lose some photorealistic style.
This version probably solved the problem that the character's body is not completely covered with fur. (maybe solved, may be not xd), also solved missing tail issue.
------------------------------------------------------------------------------------------------------
For v75:
Based on v65, v70, v45_extra.
This model is probably a combination of v45 and v60.
Note that hybrid models are common models that can do many different styles by artist names, make sure to add artists to prompts.
------------------------------------------------------------------------------------------------------
For v70:
This model is probably a combination of v55_SFW and v55_NSFW, maybe more SFW.
Trained with Nijijourney images, could probably do a lot of NJ anime styles.
Lighting is more natural according to a friend xd. Could handle very dark images. Unstable NSFW, this model is more about looking good xd.
Note that doing NSFW is unstable, can only do humanoid penises, sometimes the shape of characters’ penises will be weird xd.
------------------------------------------------------------------------------------------------------
For v65:
A similar but different model for v35, it’s a model with a strong Midjourney photorealistic style and HDR.
Trained with Midjourney images, could probably do a lot of MJ realistic styles.
Note that this model doesn’t like tails, tends to do ferals, also the character’s body may not be fully covered by fur (or become human xd)
------------------------------------------------------------------------------------------------------
For v60:
Similar model to v45, with different rock version.
------------------------------------------------------------------------------------------------------
For v55:
2 versions, see 'about this version'.
------------------------------------------------------------------------------------------------------
For v50:
A more common model than v35 with weaker style and better compatibility.
No (or less) midjourney style this time (couldn’t find dataset to make loras also it’s damn tiring to merge loras or MBW models I don’t wanna do it again xd).
------------------------------------------------------------------------------------------------------
For v45 hybrid:
This is basically a mix of all my previous models with fluffyrock, it balanced style and stability,should be able to be used as a general model.
It can do both anime and realistic content, but I think it's more realistic.
Note that in some scenarios, there is not as much details in generated images as those specialized anime/realistic models.
Should be ok with all LoRAs.
------------------------------------------------------------------------------------------------------
For v40:
Extremely high LoRA weight, fine with most of LoRAs?
It's been a hard time for me to merge v40, it's not easy to balance the style and NSFW compatibility of models during merging. I may have gone too far for this one in style, and I tried to replicate niji style but kinda fail again :( It's also an 'anime' model though, so I guess not so niji is ok? ahh whatever, here it is:
This model is more 'anime' than 'niji', it's very flat colored without oily glistening most of the time, and its niji style is still way worse than nijijourney (so sad), but i think it's better than v25 xd
Works fine with or without TI embeddings (negative textual inversions), note that some embeddings will affect style significantly, so try not to use too many of them.
The style of v40 is somewhat different from v25, and doing better NSFW than v25.
Artist tags will affect the output in a different way, they will not replicate artist styles.
The contrast of the generated image may be too high sometimes. And personally I think this version gone too far for anime styles in some circumstances.
Sometimes this model generates bad hands.
Still has trouble doing non-humanoid penis.
It tends to generated blue furries idk why xd.
LoRA compatibility still remains a mystery (?), in my tests, some loras are good, some are not.
This version was made in a hurry, If you find other problems please let me know :(
------------------------------------------------------------------------------------------------------
For v35:
Extremely high LoRA weight, worst LoRA compatibility of all.
This is v35 realistic & midjourney, it’s an improved version of v20, and it’s another attempt to replicate the images generated by Midjourney v4. This is just an attempt (it’s like v25, using a lot of LoRAs to finetune base models, I’m still learning), I can’t tell if this model is good or bad, I'll leave it to you guys to judge xd.
The example images are generated with the fp32 model.
Could probably do anything that v20 can do.
Dark themed, high contrast, HDR.
Limited sci-fi content.
Like v25, it generates detailed backgrounds that sometimes need to be stopped.
Better than v20, worse than Midjourney. (I think this model is a lower ranked Midjourney v4 not to mention v5 xd)
Use ‘photorealistic’ to do photorealistic. (Whatever, just pile up a bunch of quality tags xd)
Doing SFW or NSFW equally bad/good in my test.
Unfortunately, this model sometimes looks pale and is not colorful in style, just like the opposite of v20 xd.
------------------------------------------------------------------------------------------------------
For v30_hybrid:
Good compatibility for rock based LoRAs, ok for NAI based LoRAs.
This is v30_hybrid, an alternate version of v16. It’s a highly fluffyrock based model (credit to the author). I was told that v16 was too anime, so I tried to keep the goods of rock without affecting the generation of kemono content, I kinda messed up both sides, but whatever, here it is.
SO:
You need to know how to use fluffyrock.
Thanks to rock, this model can do almost any content.
Could probably do a lot of kinky stuffs.
Doesn't need too many TI embeddings (negative textual inversions). Don't just pile a lot of embeddings in negative prompt, this model doesn't seem to like them together sometimes :( Also they will affect the generation of certain poses.
In my tests, it generalizes better than v16, but is less stable than v16.
There is a higher threshold, not as easy to use as v16.
The outputs of kemono content are sometimes better than v16, sometimes worse than v16.
Mostly use the e621 tags, minimum danbooru tags’ support.
The quality of output images can be varied, so you need to roll for good results. If you are not that familiar with prompting, I suggest you use v16.
------------------------------------------------------------------------------------------------------
For v25_anime_niji:
High LoRA weight, ok for LoRAs.
This is a improved version of v12, a heavily lora weighted model, trying to replicate the images generated by Midjourney Niji 5, and generates kemono anthro furries in a anime style, SFW and NSFW.
This version can generate a style similar to niji 5, not exactly niji 5 style, it also generates anime style. (and you need to write good prompts and roll for a few times xd)
Generates very detailed backgrounds. (almost too detailed sometimes, you need to prevent it from doing that by prompting xd) (Yeah you can do landscapes with this version xd)
Better at doing SFW than NSFW, in my opinion. It’s more unstable to do NSFW in this version, sometimes there are good outputs indeed. If you like the style you can use v25, but if you prefer NSFW or kinks without niji style, just use v16, it’s amazing <3
More annoying to use, better style, more unstable (hands are stable tho). Prompting is more difficult than v16. Accuracy is worse than v16. It needs many quality tags to do niji 5 style, and you need to choose when to use danbooru tags or e621 tags for different content (or use a short sentence or paragraph). Less sensitive to tags, less responsive to artist styles. (Just use v16 it’s amazing <3)
Doing worse sex/duo scenes, good for solo.
Needs higher resolution to get better results.
Some tags seem to be a little overfitting: ‘anthro’, ‘dragon’, ‘wolf’ and ‘muscular’.
Seems to be more stable for females.
Can do ferals but very unstable.
This version is not perfect. Your experience with this version may vary <3
------------------------------------------------------------------------------------------------------
For v20_realistic:
A quick mix, its color may be over-saturated, focuses on ferals and fur, ok for LoRAs.
This is just a improved version of v4.1, if you don't like the style of v20, you can use other versions.
This version is intended to generate very detailed fur textures and ferals in a realistic style.
Usage is similar to v16. (it's like v16 without kemono style)
Doing better ferals than v16. (maybe xd)
The anthro dragons generated in this version will have a bit of feral features.
Like v16, this version can do females.
Can do aquatic furries.
More unstable than v16, and doing worse hands.
------------------------------------------------------------------------------------------------------
For v16_hybrid:
High anime style, good compatibility for NAI based LoRAs, ok for rock based LoRAs.
This is the first hybrid model, use 'kemono/anime' in prompt to generate anime content, 'chibi/cute' to generate cutie/cub kemono and chibi kemono (with danbooru tags), and use 'realistic' to generate realistic content (anime-ish), these are situations without artists tags. This model is best at generating bara/yaoi kemono and NSFW content.
This model is very sensitive to the prompts and artists tags you write. Add artists to prompt can significantly affect the outputs.
Can do proper ferals now. (May not be perfect xd)
Morenon-dragon male furriessupport.It's a furry mix now xd, so it could probably do any content.
More sex/duo content support. (Which had none before xd)
The style is mostly determined by the prompts you wrote.
OK for both danbooru tags and e621 tags.
Can do females.
Still can't do aquatic furries.
Still has no eastern dragons support. (Unable to solve, may have to use lora)
------------------------------------------------------------------------------------------------------
Old versions (not recommended):
Description below is for v4.1 and v12
v8 is trash.
Used to named indigo male_doragoon_mix v12/4.1
For v12_anime/v4.1_realistic:
Hello everyone! These two are merge models of a number of other furry/non furry models, they also have mixed in a lot of my own LoRAs. And they're all about male anthro dragons.
These models are heavily bara oriented, the training dataset is mostly male NSFW, so it's easier for them to generate male nudity, no clothing and NSFW content.
They mainly use e621 tags, but also support danbooru tags, and already baked in vae so you don't have to use any.
Although they are 'doragoon' mix, they can generate other male furries.
They are not specially trained for anthro females. I didn’t try a lot, but I think these models can do females, and they are okay for females.
There are two types of them that are mixed with different models to generate different outputs.
The anime one:
It's used to generate anime style dragons or kemono dragons. It's also good at generating other furry male anthros. Recommended sampler: DPM++ 2M Karras and Euler a.
The realistic one:
It's used to generate realistic or photorealistic style anthro dragon males and other furry males. Recommended sampler: DPM++ SDE Karras and also Euler a.
Example images are slightly curated and they are direct outputs without inpainting.
Known issues:
For both:
Struggling with wings and tails, because they are anatomically complex. May needs a little inpainting.
Inpainting is always good.
Without Hires Fix, both of them tend to generate blurry faces and eyes, so I recommend using Hires Fix for the whole time.
Latent, ESRGAN_4x or Anime6B.
Can not do aquatic anthros.
Getting no better results when using male dragon related LoRAs.
No eastern dragons support yet.
For the anime one:
it has noise offset issue, it generates very bright characters in dark scenes, so useContrastFixto fix it.https://civitai.com/models/8765?modelVersionId=10638SelectSD1.5 version.And I don't think it's 'anime' enough for now. Itsstyle is somewhat fixed, and it's a little overfitting.Can be unstable.
Also anime one is worse at hands.
Can not do ferals.
(Can do a weird type of ferals: anthro feral xd)
For the realistic one:
generated characters' eyes will be blurrier in full body portrait.
Can do just a little bit of ferals.
(The images generated by AI are currently in a gray area. Since the training dataset has not been authorized, the dataset is not so clean. These generated images are for personal usage only. Please do not use them for commercial purpose, including merges using this model, thank you!)
(出图切勿商用,包括混入此模型的混模也切勿商用!谢谢!)
(English is not my native language, please forgive me if I make mistakes. )