Type | |
Stats | 146 233 125 |
Reviews | (15) |
Published | Oct 1, 2024 |
Base Model | |
Hash | AutoV2 E9B5F0CE0F |


注意:本模型未经许可严禁转移至其他平台(liblib已进驻:https://www.liblib.art/userpage/a68d8219ddf245ecbd3e1da465409eaa/publish ),若发现会立刻联系平台相关方进行下架处理。
Notice: Unauthorized transfer of this model to other platforms is strictly prohibited (liblib has been authorized: https://www.liblib.art/userpage/a68d8219ddf245ecbd3e1da465409eaa/publish). If discovered, the relevant platform will be contacted immediately for removal.
免责声明:本模型的使用者需严格遵守所在地的法律法规,合法合规地使用ai技术。若使用者因违反所在地法律法规等原因所造成的各类不良后果本人概不负责。
Disclaimer: Users of this model must strictly comply with the laws and regulations of their respective locations and use AI technology in a lawful and compliant manner. The creator shall not be held responsible for any adverse consequences arising from users' violation of local laws and regulations or other reasons.
关于Noobvpredv10\epsv11 v1.1版本
For Noobvpredv10\epsv11 v1.1
此版本(v1.1)重新调整了训练集,从而获得了对各时期画风更高的拟合度。
This version (v1.1) has readjusted the training set, resulting in a higher fit to the art styles of each period.
1:本模型是基于NoobXL vpred V1.0底膜训练的sdxl Lokr模型,使用sdxl_vae作为vae。
1:This model is a sdxl-lora based on NoobXL vpred V1.0 .Using sdxl_vae as a vae.
ATTENTION !As a kind of Lycoris model, most of times its usages are as same as the sdxl lora. However, lokr CANNOT be used on some batch nodes on Comfy UI (e: Lora stack). You can use the XYZ PLOT on Web UI to achieve similar functionality !!!
注意!作为Lycoris模型系列下的Lokr模型,虽然在大部分情况下使用方法与普通lora无异,但部分ComfyUI 测试功能如(Lora堆节点(lora stack)等)是用不了的!建议使用Web UI的xyz图表功能来完成同类操作!!!
加注:本模型展示图仅通过文生图(1024x1536)与高清放大(2048x3072)生成。
Tips: Pictures showed on the screen were only generated by t2i (1024x1536) and hire-fix (2048x3072).
加注2:你可能已经注意到了展示图像中的相当一部分图像呈现出与仅经过普通的文生图与图生图放大略有不同的效果,它们的线条更加圆润、细节更加合理、对画风与角色的拟合度也相对更高一些。属于是单独使用eps预测模型或v预测模型的情况下很难实现的效果(?)
Note 2: You may have noticed that a significant portion of the displayed images exhibit effects that are slightly different from those achieved through ordinary text-to-image or image-to-image upscaling. Their lines are more rounded, details more reasonable, and the fit to the artistic style and characters is relatively higher. These are effects that are difficult to achieve when using only the eps prediction model or the v prediction model (?).
 首先,这是在同参数下全程使用eps扩散生成的最终图像。
首先,这是在同参数下全程使用eps扩散生成的最终图像。
First, this is the final image generated using the eps diffusion process throughout with the same parameters.
 而这张是其他参数不变的情况下采用下面讲述方法的结果。
而这张是其他参数不变的情况下采用下面讲述方法的结果。
And this one is the result obtained by employing the method described below while keeping all other parameters unchanged.
在讲述这个区别之前,我想先阐述一个有关于noobxl预测方法的猜想。首先,在DDPM(去噪扩散模型)中共有4种原生的预测方法,它们分别是eps(噪声)、v(速度)、x(最终图像)和score(分数)预测。这四种预测方法在数学上应该是等价,且与unet里的知识无关的。因此理论上,一个模型甚至可以共存四种预测。且并不存在重新训练新预测方法(重映射)后原先已经习得的预测方法(先前已经建立的映射)就会被完全遗忘的情况。它仅仅只是没有对齐而已,模型本身并没有忘记这个东西!!!
而与之相对应的是,在noobxl的eps v1.1版本推出时,与其同一系列的的v预测模型也已经发布。因此我假设noobxl的eps v1.1版本是同时具备eps与v预测两种预测能力的!虽然模型主要适用于eps预测,但其也能够通过v预测的方式来解码图像,但能力并没有其它专用于v预测的模型那么出色而已。因此我做了下图的尝试:
Before delving into the differences, I would like to present a conjecture regarding the noobxl prediction method. Firstly, there are four native prediction methods in DDPM (Denoising Diffusion Probabilistic Models), namely eps (noise), v (velocity), x (final image), and score prediction. These four prediction methods should be mathematically equivalent and independent of the knowledge within the unet. Therefore, in theory, a model could potentially accommodate all four prediction methods simultaneously. Moreover, it is not the case that once a new prediction method is retrained (remapped), the previously learned prediction method (the previously established mapping) is entirely forgotten. It is merely a matter of misalignment; the model itself has not forgotten this capability!!!
Correspondingly, when the noobxl eps v1.1 version was released, the v prediction model from the same series had also been published. Hence, I hypothesize that the noobxl eps v1.1 version possesses both eps and v prediction capabilities! Although the model is primarily suited for eps prediction, it can also decode images through v prediction, albeit not as proficiently as other models dedicated to v prediction. Consequently, I conducted the following experiment:

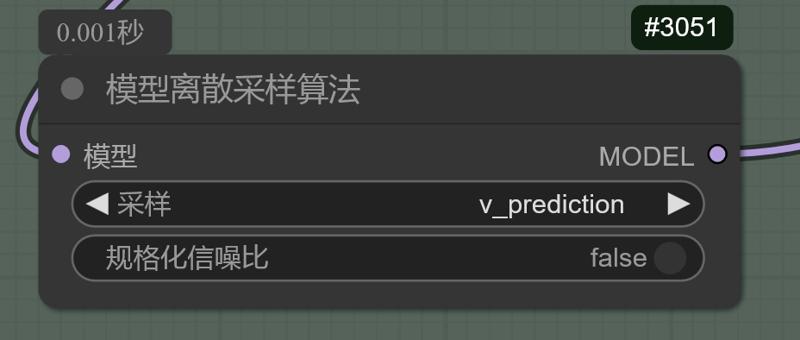 在后期模型放大后扩散模型图生图放大的过程中使用noob的epsv1.1模型,但在模型离采样算法节点中选择了v预测进行图像解码去噪。(降噪幅度(重绘幅度)经测试在0.4以上才有较为明显的效果,常用0.4\0.5)
在后期模型放大后扩散模型图生图放大的过程中使用noob的epsv1.1模型,但在模型离采样算法节点中选择了v预测进行图像解码去噪。(降噪幅度(重绘幅度)经测试在0.4以上才有较为明显的效果,常用0.4\0.5)
During the process of image-to-image upscaling with the diffusion model after the later-stage model upscaling, the noob eps v1.1 model was employed, but the v prediction was selected for image decoding and denoising at the model's sampling algorithm node. (The denoising strength (redraw strength) has been tested to show a more noticeable effect above 0.4, commonly used at 0.4\0.5).
 当然,由于epsv1.1版本并没有对v预测方式进行特化,因此其最开始生成的图片会具有出色温偏暖,颜色对比度与饱和度下降的问题,而有关这一问题,我认为可以通过Layerstyle节点包中诸如色温、自动调色v2与阴影与高光等一系列调节节点来自动调节画面参数,从而大幅缓解这一问题。(此处参数仅供参考,我也正在尝试有无其他更好效果的参数)
当然,由于epsv1.1版本并没有对v预测方式进行特化,因此其最开始生成的图片会具有出色温偏暖,颜色对比度与饱和度下降的问题,而有关这一问题,我认为可以通过Layerstyle节点包中诸如色温、自动调色v2与阴影与高光等一系列调节节点来自动调节画面参数,从而大幅缓解这一问题。(此处参数仅供参考,我也正在尝试有无其他更好效果的参数)
Certainly, since the eps v1.1 version is not specialized for v prediction, the initially generated images may exhibit issues such as a warm color bias, reduced color contrast, and saturation. Regarding this issue, I believe that a series of adjustment nodes in the Layerstyle node package, such as color temperature, auto color v2, and shadows and highlights, can be utilized to automatically adjust the image parameters, thereby significantly alleviating this problem. (The parameters provided here are for reference only, and I am also exploring whether there are other parameters that could yield better results.)
3:Rules of trigger word: 模型触发词使用规则
(1):画风触发词格式与分类:misaki_kurehito_xxx
<1>早期(early)(2006-2014):misaki kurehito 1
<2>中期(mid)(2015-2018) :misaki kurehito 2
<3>晚期(latest)(2018-2024):misaki kurehito 3
example: <1girl/1boy/1other/...>,
<character>, <series>, misaki_kurehito_xxx,
<general tags>,
masterpiece,best quality,absurdres,highres,sensitive,newest,
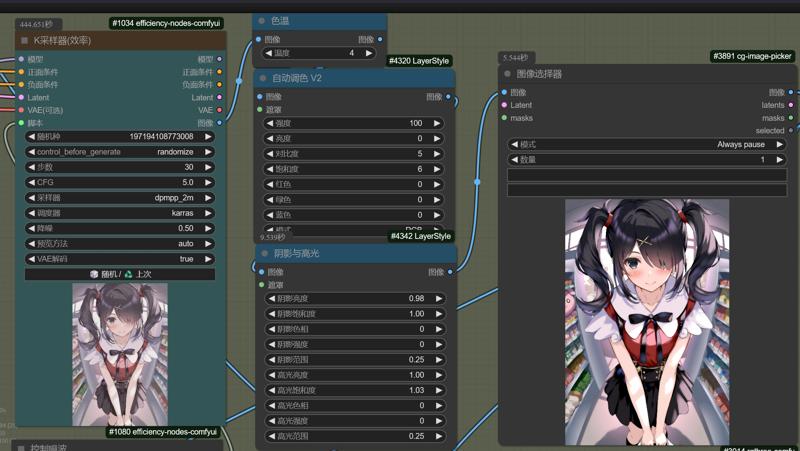
4:generation data(example)(Comfy UI): 生成参数(Comfyui)
lora weight: 1
Using Efficiency nodes (restore Web UI usage)(使用效率节点还原Web UI参数,Web UI可无视)
Using PAG Node(default) 使用PAG节点(默认参数)
steps: 30\28
CFG: 5\4
sampler: dpmpp_2m (Web UI: dpm2p_m karras?)
scheduler: karras
For SanaeXL Lokr v1.0 早苗底膜v1.0 Lokr模型
1:This model is a sdxl-lora based on SanaeXL anime V1.0.Using sdxl_vae as a vae.
1:本模型是基于SanaeXL anime V1.0底膜训练的sdxl Lokr模型,使用sdxl_vae作为vae。
ATTENTION !As a kind of Lycoris model, most of times its usages are as same as the sdxl lora. However, lokr CANNOT be used on some batch nodes on Comfy UI (e: Lora stack). You can use the XYZ PLOT on Web UI to achieve similar functionality !!!
注意!作为Lycoris模型系列下的Lokr模型,虽然在大部分情况下使用方法与普通lora无异,但部分ComfyUI 测试功能如(Lora堆节点(lora stack)等)是用不了的!建议使用Web UI的xyz图表功能来完成同类操作!!!
加注:本模型展示图仅通过文生图(1024x1024)与高清放大(2048x20248)生成。
Tips: Pictures showed on the screen were only generated by t2i (1024x1024) and hire-fix (2048x2048).
2: Sanae's tag rule 早苗底膜tag排布规则:
推荐设置/Recommended settings
prompt:
<1girl/1boy/1other/...>,
<character>, <series>, <artists>,
<general tags>,
masterpiece,best quality,absurdres,highres,sensitive,newest,
negative prompt (short) :
lowres,low quality, worst quality, normal quality, text, signature, jpeg artifacts, bad anatomy, old, early, multiple views, copyright name, watermark, artist name, signature
negative prompt (long) :
lowres,bad anatomy,blurry,(worst quality:1.8),low quality,hands bad,(normal quality:1.3),bad hands,mutated hands and fingers,extra legs,extra arms,duplicate,cropped,jpeg,artifacts,blurry,multiple view,reference sheet,long body,multiple breasts,mutated,bad anatomy,disfigured,bad proportions,bad feet,ugly,text font ui,missing limb,monochrome,bad anatomy,blurry,(worst quality:1.8),low quality,hands bad,face bad,(normal quality:1.3),bad hands,mutated hands and fingers,extra legs,extra arms,duplicate,cropped,jpeg,artifacts,blurry,multiple view,long body,multiple breasts,mutated,disfigured,bad proportions,duplicate,bad feet,ugly,missing limb,
负面提示词必须包含: lowres (由于使用了大量低分辨率图片进行训练)。worst quality 和 low quality 可根据个人需求选择是否添加。也可以使用例图里的负面提示词(long),这串提示词是内部成员测试时使用的的,它非常的“屎山”,我们也无法确认其效果如何,但”it just work.”。
Negative prompts must include: lowres (due to the use of a large number of low-resolution images for training). "worst quality" and "low quality" can be added based on personal preference. You can also use the negative prompts (long) shown in the example images. This string of prompts was used by internal members during testing. It is quite "shitty", and we cannot confirm its effectiveness, but "it just works."
3:Rules of trigger word: 模型触发词使用规则
(1):画风触发词格式与分类:misaki_kurehito_xxx
<1>早期(early)(2006-2014):misaki kurehito 1
<2>中期(mid)(2015-2018) :misaki kurehito 2
<3>晚期(latest)(2018-2024):misaki kurehito 3
example: <1girl/1boy/1other/...>,
<character>, <series>, misaki_kurehito_xxx,
<general tags>,
masterpiece,best quality,absurdres,highres,sensitive,newest,
4:generation data(example)(Comfy UI): 生成参数(Comfyui)
lora weight: 1
Using Efficiency nodes (restore Web UI usage)(使用效率节点还原Web UI参数,Web UI可无视)
Using PAG Node(default) 使用PAG节点(默认参数)
steps: 30
CFG: 7
sampler: dpmpp_2m (Web UI: dpm2p_m karras?)
scheduler: karras