
Script↓
SDXL LoRA train(8GB) and Checkpoint finetune(16GB) - v1.0 | Stable Diffusion Other | Civitai
Looooong time no see!
I——bdsqlsz,i had made DAdaptation V2、V3、prodigy implement in kohya's sd-scripts.
Of course this is only some minor work, so here is the first thanks to the authors of these optimizers, without whose papers and algorithm it would be impossible to implement them into lora training.
You should have heard of DAdaptation long ago, and someone has written a tutorial on Lazy training with DAdaptation.
Civitai | LoRA Lazy DAdaptation Guide
BUT...The situation has changed! The new optimizer puts an end to everything.
That is Prodigy!
What is it?
Well, let's start at the beginning.
Back in early May, I tried to use dadapataion to train dylora, but since the two adaptive algorithm apparently conflict, it rightfully failed.
Support for Dylora · Issue #24 · facebookresearch/dadaptation (github.com)
But the authors of dadapataion adefazio and konstmish fixd it!A new optimizer has been developed:
Prodigy:An Expeditiously Adaptive Parameter-Free Learner
ok,my issue has completely solved.

As you can see, unlike DAdaptation, Prodigy automatically adjusts the learning rate after each gradient accumulation backpropagation. .
Simply put, it is adaptive auto-learning throughout.
You no longer need to try to adjust redundant hyperparameters, that's what makes Prodigy so great.
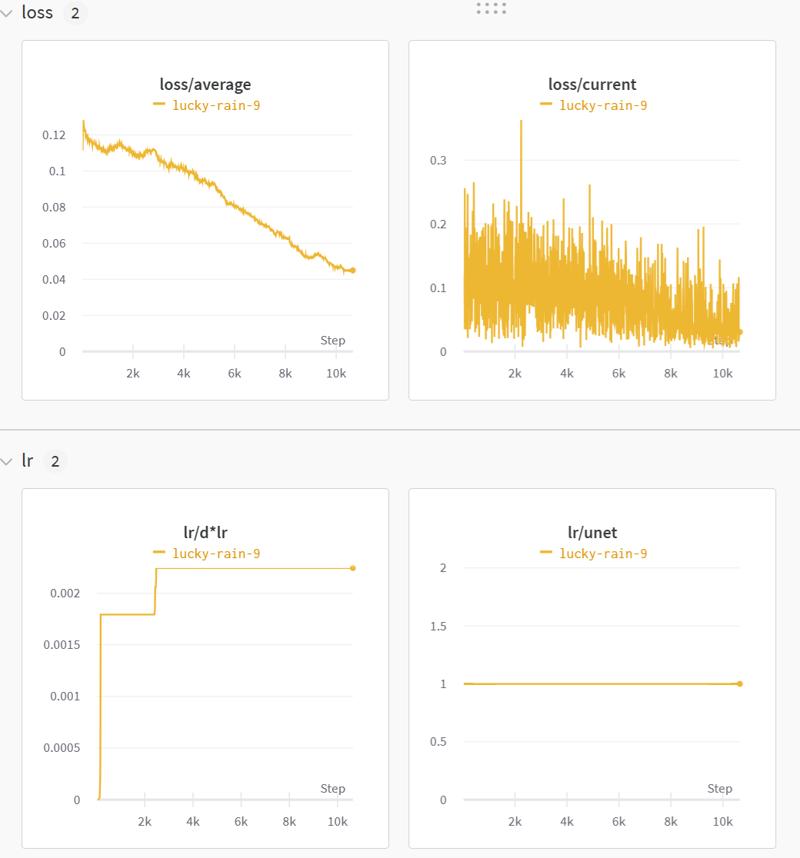
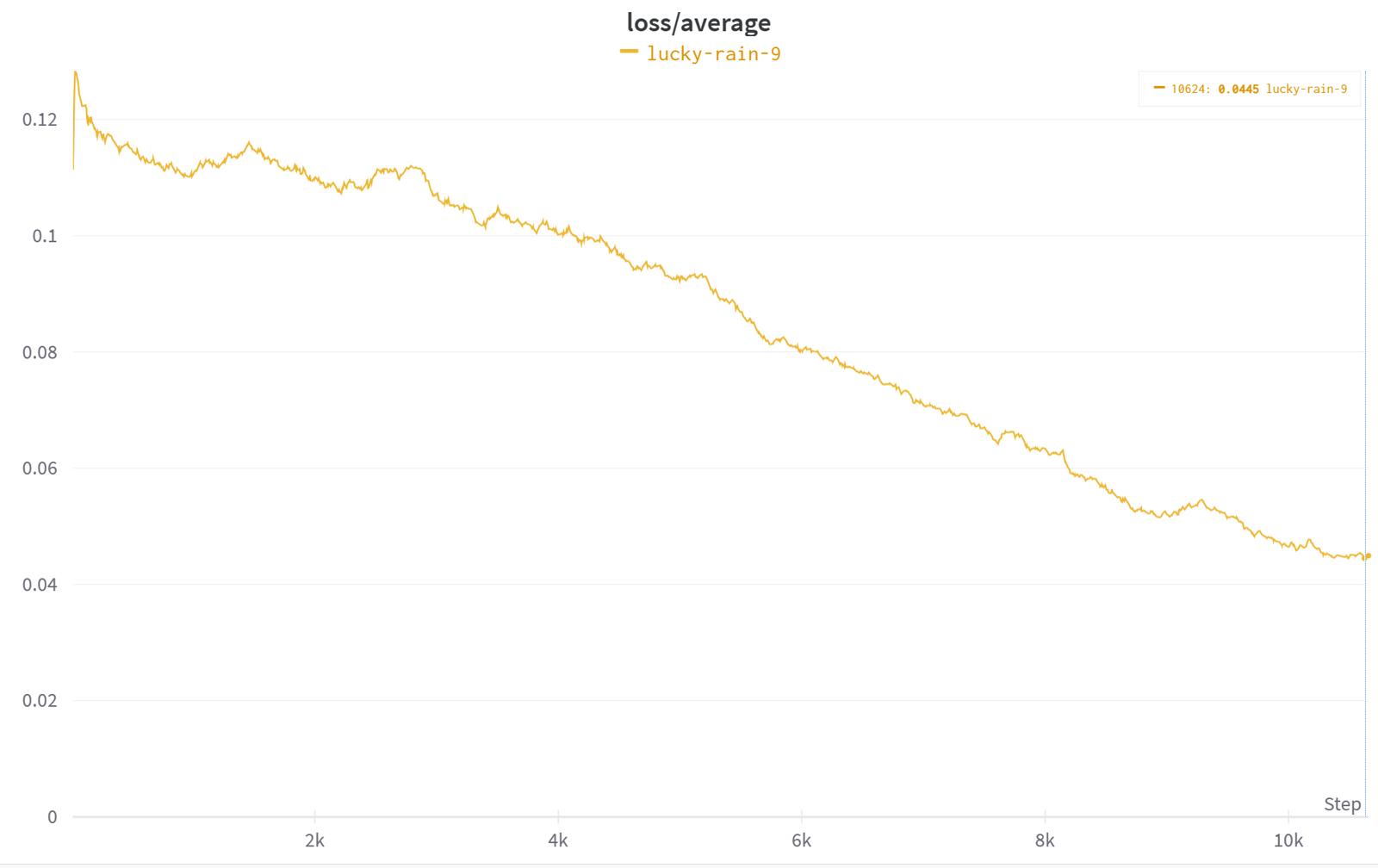
↑This is SDXL training,I dare say this is the best loss chart I have ever seen.
So the question arises,
How best to use Prodigy?
What many people don't know is that optimizers also have their own unique parameters, and like Prodigy at least a few fixed parameters have to be turned on to get the best results.
I generally use my own script written to train lora, so it's completely different from the GUI version. Here I share the custom parameters I use.
--optimizer_type=Prodigy--optimizer_argsweight_decay=0.01decouple=Trueuse_bias_correction=Trued_coef=$d_coef if($lr_warmup_steps){ [void]$ext_args.Add("safeguard_warmup=True") } if($d0){ [void]$ext_args.Add("d0=$d0") } $lr = "1" $unet_lr = $lr $text_encoder_lr = $lrMany of the parameters you may have seen in using dadaptation, so I won't explain them again.
If you haven't seen it, please see the tutorial at the top about dadaptation related.
Briefly, a few new parameters.
d_coef, the recommended range of 0.5 to 2. The coefficient used to adjust the D value, but of course I prefer to use 2 by default.
safeguard_warmup=True
If you use constant or warmup, you need to turn it on.
d0, the learning rate starting value. Some special lycoris types have larger initial learning rate requirements, such as IA3, Lokr, Dylora, and SDXL's lora
So if you use these special types above, you need to set a relatively high initial value to make Prodigy start faster.
The last is to make the three learning rates forced equal, otherwise dadaptation and prodigy will go wrong, my own test regardless of the learning rate of the final adaptive effect is exactly the same, so as long as the setting is 1 can be.
This is result for SDXL Lora Training↓

I use
Res 1024X1024
Dim 128
ConvDim 8
Batch Size 4
VRAM spends 77G
Oh I almost forgot to mention that I am using H10080G, the best graphics card in the world.
and 4090 can use same setting but Batch size =1
it almost spends 13G
if you use gradient_checkpointing and cache_text_encoder_outputs may costs less VRAM
Last Tips:
Dont use dropout and max normal regulation with Prodigy
Two adaptive algorithm apparently conflict to get worse result.
If you are interested in the training script (command line tool) that I wrote myself, you can leave a comment here. If more people are interested, I will consider translating it into English.