


有问题/错误请及时联系 千秋九yuno779 修改,谢谢。
前言
介绍说明
Stable Diffusion (稳定扩散) 是一个扩散模型,2022年8月由德国CompVis协同Stability AI和Runway发表论文,并且推出相关程序。
Stable Diffusion WebUI能够支持多系统使用,无论是Linux/Windows还是MacOS,现在都已支持使用。Stable Diffusion WebUI有着极为广泛的插件生态,能够实现远超Midjoruney/NovelAI的自由度和实用价值。
AUTOMATIC1111所开发的Stable Diffusion WebUI是目前使用最为广泛的AI图像生成开源软件,本文章将围绕Stable Diffusion WebUI展开相关内容的说明。
特别致谢
【AI绘画lora交流群】群友帮忙完善了LoRA训练相关的内容
【XDiffusion AI绘画研究交流】帮忙挑刺,找出了一部分文章的错误内容
【元素法典组】
【秋叶的甜品店】
【幻想魔法书—旧日黎明】帮忙制作了文章框架,补充了部分内容
【珊瑚宫︱数字生命研究所】
避坑指南
①任何在x宝、x鱼等平台售卖AI整合包的,全部都是坑钱的
②任何AI绘画相关课程都是大冤种课程,也都是坑钱的
③任何收费出售AI模型、LoRA、付费生成的AI绘画相关内容,都是坑人的
④任何平台的:例如“我的二次元形象”“无尽三月七”等活动,在一般的SD中只需要一个LoRA就可以轻松解决
⑤国内所有的AI绘画APP都不要使用、大概率也是坑你钱的
⑥国内绝大部分模型站都最好不要使用(出现过很多离谱操作),如有需要请使用civitai和huggingface(civitai大家一般都简称C站,C站可能会上不去,huggingface简称抱脸,很多时候国内的交流群都比较喜欢用简称来称呼这两个网站)
一些链接:
1. 潜工具书
新人最推荐查看的AI绘画最全工具书
2. 新手入门
推荐关注up:秋葉aaaki 入门可以去看其专栏和视频
3. 提示词
提示词全解:
元素法典:1和1.5卷因为部分问题不做推荐,新人也不建议查看
一些玄学的东西的纠错与解释
4. 模型站
[Blocked Link]
5. 本文参考/借用内容的链接
Stable Diffusion WebUI使用手冊(简体中文)
[調査] Smile Test: Elysium_Anime_V3 問題を調べる #3|bbcmc (note.com)
THE OTHER LoRA TRAINING RENTRY
Home · AUTOMATIC1111/stable-diffusion-webui Wiki (github.com)
如何识别AI图片:
目前由 AI 绘制的插图完成度已经逼近甚至超越了真人画师,所以粗略查看是无法区分是否由 AI 绘制。
1. 误区
a. AI图并非画不好手,也并非是那种油腻的“AI风格”
b. 网上的各种分辨网站/软件,经实测识别成功率最高的仅有40%的置信度,所以仅看个乐就行
c. 对于经常玩AI绘画的人来说,AI图基本可以做到一眼分辨
2. 分辨方法
通过模型分辨
部分热度较高的模型都有对应相对固定的风格,能够识别这些风格就能做到接近70%以上的置信率
【例如:AOM模型】
橘子系列模型的具体效果是人物身体的表面有一种油光
(这也是前段时间被圈外人所常说的AI味)
这种模型特征其实非常多,玩的多了就可以很轻易的查看
扩散生成痕迹
AI生成图片并非是理解了图片画什么怎么画,而是通过反向扩散的方法直接生成图片,这种生成痕迹会有一些较为明显的特征
这种痕迹是绝大部分模型都无法避免的,具体来说就是:包括但不限于衣服褶皱、皮肤褶皱、头发效果上出现莫名其妙不合逻辑的纹路、以及部分不应该出现的噪点。其次还有,部分AI图也存在本来不应该在同一位置的物品相连接或者相融合的情况。

图像细节问题
这个方法是最后的方法,再上面两种一眼丁真的方法都不起作用的时候再来用这个。
例如AI会在左右眼形状和高光的一致性、服装对称性、重复形状一致性、几何图形的正确与否等方面出现问题。
SD部署和使用,神奇的AI绘画在这里
1. 部署stable diffusion webui
首先你得有Stable Diffusion WebUI框架和模型,没有部署SD,玩个P的AI绘画。
硬件需求
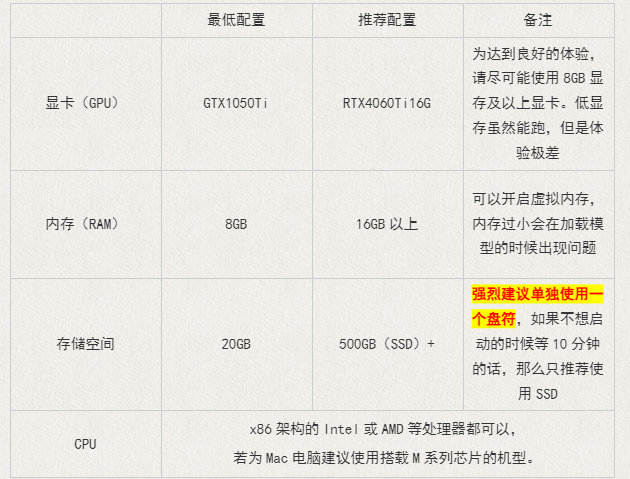
显卡VRAM在4GB以下的会很容易遇到显存不足的问题,即使使用放大插件也就非常慢(以时间换显存)
可以开启CPU模式,但是速度依旧是非常慢。你不希望一个小时一张图的话那就别想着用CPU跑图

操作系统需求
Linux:Debian11(这个我在用)
(除此之外我并不知道那些版本可以正常使用,如有需要可以先下载贴吧整合包测试)
Windows:最低要求为Windows 10 64比特,请确保系统已更新至最新版本。
windows7就不要想了,建议直接升级到win10/win11
macOS:最低要求为macOS Monterey (12.5),如果可以的话请使用最新版macOS。
建议使用搭载Apple Silicon M芯片 (M1、M2) 的Mac机型。
旧款Mac需配备AMD独立显卡,只有Intel核显的不能使用。
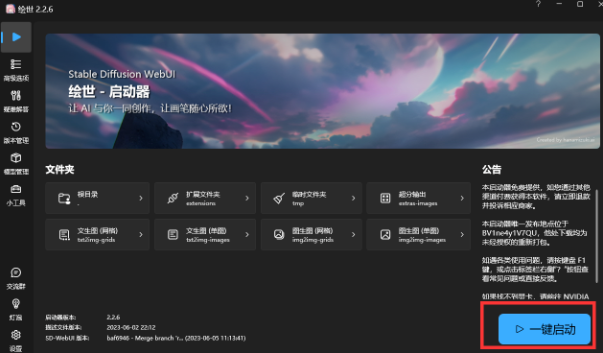
整合包部署
如果你是从零开始,这里推荐秋葉aaaki一键包和启动器。
【AI绘画】Stable Diffusion整合包v4.2发布!全新加速 解压即用 防爆显存 三分钟入门AI绘画 ☆可更新 ☆训练 ☆汉化_哔哩哔哩_bilibili
如果你是A卡或者I卡,那么秋叶整合包将无法使用,推荐使用贴吧整合包
2. 添加ckp大模型NovelAI 和Anything分别是什么?
NovelAI是一个二次元AI生成图片的网站。因为泄漏事件,NAI 使用数千万 Danbooru(图站)图片训练的模型被泄漏了两次。
事件报告
泄露 Part 1 —— 包含生产模型,程序 —— 53.66 GB,其中相关模型有 7GB 和 4GB 两种。
泄露 Part 2 —— 包含历史测试代码和模型,程序 —— 124.54 GB,其中相关模型与 Part1 相同。
Anything是由元素法典组的千秋九(也就是我)制作的一个融合模型。因为其效果在当时来看较好,并且受到众多营销号的吹捧而广为人知。
如何添加ckp大模型
部署完成后,将下载的模型放到WEBUI根目录中的model/Stable-diffusion文件夹中。ckp大模型的大小一般为1.6G及以上,后缀为.safetensors。
当然了有的整合包自带有ckp大模型,当你看到WEBUI根目录中的model/Stable-diffusion里面有模型文件的时候,那么可以暂时跳过这个步骤,直接使用整合包自带的模型。
注意:
①除非你完全可以信任这个模型,那么请尽量避免使用.ckpt后缀的模型。
②请不要听从其他人的任何建议,关闭模型检查。请及时拉黑让你开启允许加载不安全模型这个选项的人。

3. 运行WebUI实例
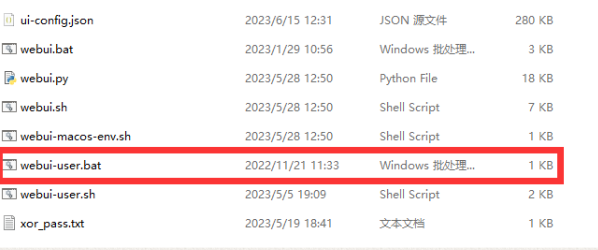
点击启动器上的启动按钮以启动你的webui实例,没有启动器的整合包请按照视频说明启动。如果不使用启动器和整合包,则点击webui-user.bat
4. 常见问题
一般而言,遇到的问题可以根据启动器所提示的内容解决。启动器无法识别的报错可以尝试复制到翻译软件简单翻译一下,若不知道如何解决,则可以到对应的交流讨论区询问。
注意:没人愿意只凭借一个不正常退出的提示截图就给你解决问题,请上传完整的报错截图。没有错误日志就诊断问题无异于闭眼开车。

5. 基础参数说明
以一个普通的WebUI界面为例。如果你的界面色彩不同或选项更少或更多,不用奇怪,这是正常的。笔者下载了一些插件,仅此而已。只需要看看该界面那些参数、选项有什么作用,效果就达到了。
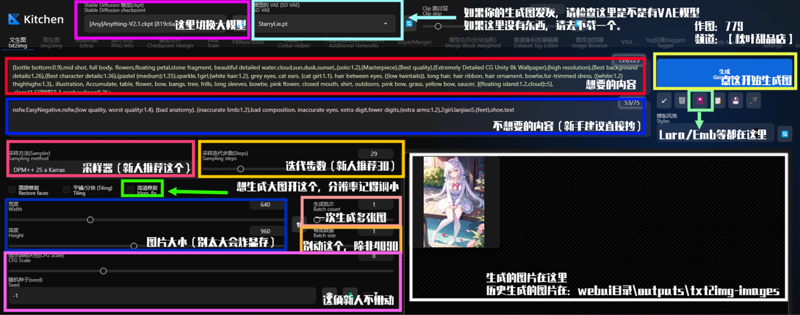
高清大图:https://postimg.cc/PLt8bmBH
一般而言只需要记住这张图就好了,详细的说明在下面
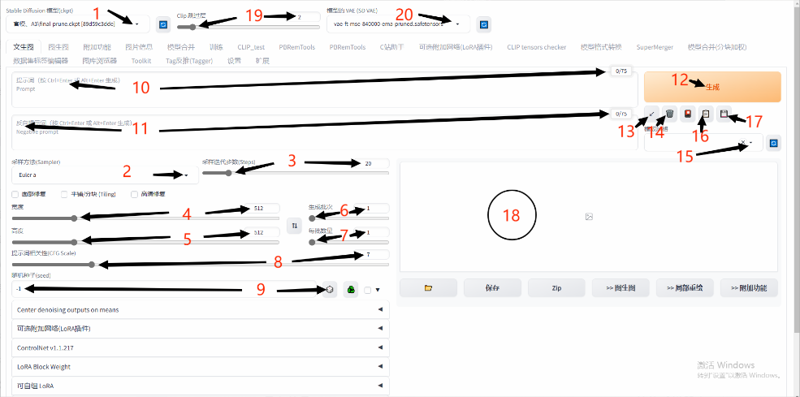
大模型:不管你的模型是ckpt格式,还是safetensors格式,这里可以选择你的模型,或调换模型。右箭头指向的小三角形,点开就可切换模型。关于模型的作用和推荐,后文讲解。
采样方法:也称采样器。最古老的好像是Euler和Euler a,DDIM曾经相当火。当下用的最多的是DPM++ 2S a Karras、DPM++ 2M Karras、DPM++ SDE Karras,其他采样器也可以尝试,有时会有出色的表现。采样器会影响出图速度,DPM++ 2M Karras、DDIM、UniPC等几个采样器生成速度快,但太低步数图片会崩坏,建议不用高清修复时不低于20步,用高清修复不低于10步。(并非绝对)
采样迭代步数:一般称步数。并非越高越好。不开高修约30至50步够用,开高修15至25步够用。当你已经很熟练,可以无视此条。
图片宽度:简称宽。必须为8的倍数。太小的图不好看,图越大越模型会不知道生成什么导致糟糕的输出。如果没有固定的要求,请按显卡能力和需求适当调整。如果爆显存了,那就调小一些。
图片高度:简称高。必须为8的倍数。太小的图不好看,图越大越吃显存。如果没有固定的要求,请按显卡能力和需求适当调整。如果爆显存了,那就调小一些。
生成批次:批量生产图片时调整这个。
每批数量:很多新手批量生产图片喜欢点这个,这是错误的。它很考验你的显卡,图越大越要慎选。一般默认的1就可以。
提示词相关性(CFG):数值越大tag越精准,数值越小想象越丰富同时越不听话,不建议开启太高的CFG。但如果开启较大CFG出现了糟糕的图片,请改用CFG修复插件:mcmonkeyprojects/sd-dynamic-thresholding: Dynamic Thresholding (CFG Scale Fix) for SD Auto WebUI (github.com)
随机种子:简称种子。一般为-1(随机生成),当需要锁种子调参数做对比,复制生成图的种子填进这里即可。同种子同参数同模型同tag,生成的图片一定是几乎看不出差别的。(因不同显卡不同环境会出现有些微影响,但是并不严重)
正面提示词:一般称tag,或称正面tag、正面。新手建议抄正面tag进行尝试,并在抄来的基础上进行改动,请勿徒手乱捏。很复杂,这里只做简单的解释,详情见提示词教程。
负面提示词:一般称负面tag,或负面。新手建议不要深入研究,用抄来的就好。一般越短的负面越听话,越长的越不听话。同时,负面tag的权重也有影响,过高或者过低都有不利影响。
生成:点击生成前请确认tag是否准备完毕,参数是否在合理的数值,确认无误,即可开启奇妙之旅。
自动填充提示词和参数:很少用。如果你关闭界面时忘了保存,再次生成时想要找到上一次的提示词和参数,点这个是最快捷的方法。
清空提示词:当你要把正面和负面全部删除,点这个是最快捷的方法。
模板风格:非常好用的功能,你可以从中选择想要的已储存的提示词,迅速加载。配合16和17使用。
将已选择的模板风格写入当前提示词:要先选择15模板风格才能生效。
将当前的提示词保存为模板风格:对于经常使用的提示词,在此保存一下,想用的时候14清空提示词,15选择模板风格,16写入提示词,其他只剩调参数。
图片展示区域:你生成的图片在此会展示出来。生成图片的过程中有进度条的,跑到100%就生成完毕了。如果图片不见了,可能是爆显存,请查看该区域下方的提示栏。
Clip跳过层:简称Clip。默认为2,新手请勿调整。
模型的VAE:简称VAE。这里是外挂VAE的地方。
6. 高清修复说明
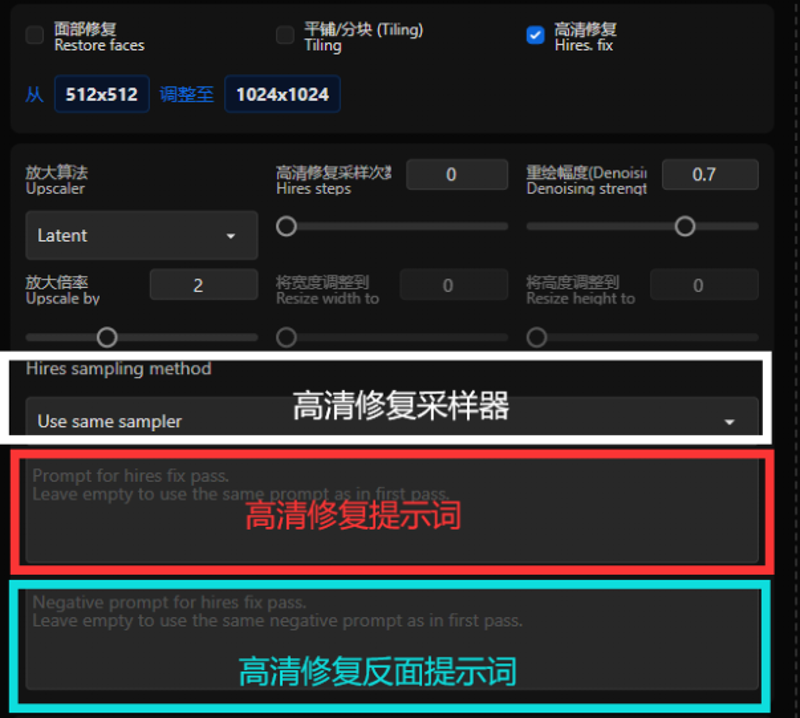
高清修复Hires.fix是用来生成较大图片防止AI模型乱画的一个功能。一般而言需要配合分块VAE插件使用防止爆显存
一般而言,二次元图片使用R-ESRGAN 4x+ Anime6B采样器。除此之外,放大的倍率也不能开太大,不然极其容易出现古神图等情况。
另外,没必要一直开启高清修复。看到了自己想要的构图/大致效果后再开启高清修复可以极大的节省抽卡生成的时间。
你热爱的,就是你的parameters
自从AI绘画出现以来,各种参数的讨论就从未停止过。
1. “我会画画了!”生成你的第一张AI图
在对应的提示词框,然后点击生成就可以生成你的第一张AI图了

提示词:
cute little girl,,solo,wind,pale-blonde hair, blue eyes,very long twintails,white hat,blue sky,laugh,double tooth,,lens flare,dramatic, coastal,
flying petal, flowery field, sky, sun,field, sunflower, masterpiece, best quality,反向提示词
(mutated hands and fingers:1.5 ),(mutation, poorly drawn :1.2),(long body :1.3),(mutation, poorly drawn :1.2),liquid body,text font ui,long neck,uncoordinated body,fused ears,(ugly:1.4),one hand with more than 5 fingers,one hand with less than 5 fingers,如果是使用的二次元模型,那么上面的提示词大体效果是这样的↓

如果你想要达到更好的效果,那么修改相关的参数就是必不可少的。下面呢就是有关生成个提示词相关参数的部分介绍。
当然了,如果不满足于文章中给的这些内容,你也可以去参考更为详细的元素同典:具体链接在本模块的最下面。
2. 提示词的范例
当然了,新人想要得到比较好的AI生成图可以看以下几个提示词合集。
但是需要知道的一点是:推荐参数绝非必须的数值,这些仅供新人参考,入门后其实是不需要任何推荐参数的。
下面的内容,就是写详细的讲解“魔法师”是如何写出这些“咒语”来的:
3. 书写你的第一段“咒语”
咒语是什么?
在AI绘画中,我们使用一段 prompt 来引导U-net对随机种子生成的噪点图进行“降噪”,从而生成我们想要的东西。
Prompt (提示词,又译为关键词)通常由英文构成,主要内容为以逗号隔开的单词/词组/短句。prompt 也可以包括其它语言的文字,但效果往往不佳。prompt 还可以识别一些特殊符号。
AI 会通过寻找符合关键词描述的噪点图进行有明确指向的去噪点(diffuse)。同样,如果包含 Negative Prompt(负面关键词),AI 就会尽可能避免含有负面相关要素的去噪点方式。换句话说,prompt 就像是哈利波特里面的咒语,它直接决定了最终我们会得到什么。
简而言之就是你想要什么那就写道正面提示词里,你不想要什么,那就写到负面提示词里。比如我想要“一个穿着白色裙子带着白色帽子的女孩站在花丛里”那么我们可以写以下提示词:
1girl,white dress,white hat,stand,flowers
这时候点击生成,就会出现左边这样的生成图。
如果理解了这以方面,那么恭喜你,你已经学会了基本简单的提示词写法了。你可以尝试一下自己喜欢的内容,多生成几张AI图尝试尝试这个过程
如果对生成图片的质量不满意,那么怎么办呢?接下来只需要根据图片生成的结果,逐步细化提示词,并且添加质量词和负面提示词就可以了。
比如左边那张图看到天空比较空,那么就可以加上:cloud,sun等这种描述天空效果的提示词。当然如果英语水平限制了你的发挥,那么你也可以使用翻译软件来“施法”。
当然了,你也可以拿着这把“全村最好的剑”:
4. 学徒级语法【三段式】&如何写提示词三段式与基本提示词写法
简而言之,三段式就是把质量词、主体、背景三者的描述分开进行。很多人在写提示词的时候会受到英语水平的限制,于是就提出了三段式语法,其目的是在较多提示词的时候能够一目了然的分辨内容,方便删减提示词和调整提示词的权重。这在当时元素法典时期使得大家能够快速的分享自己的提示词或者使用其他人的提示词。
质量词和效果词放最前面,人物与人物特征放在中间,背景和光效放以及功能性tag最后面,这是三段式的基础用法。
8k Wallpaper,grand,(((masterpiece))), (((best quality))), ((ultra-detailed)), (illustration), ((an extremely delicate and beautiful)),dynamic angle,rainbow hair,detailed cute anime face,((loli)),(((masterpiece))),an extremely delicate and beautiful girl,flower,cry,water,corrugated,flowers tire,broken glass,(broken screen),transparent glass.前缀(质量词+画风词+整体效果)
质量词用于提升生成质量:
例如:masterpiece、best quality等
画风词用于凸显图片的画风:
例如:
冰箱贴前缀:
[(flat color,vector graphics,outline):1.35),(paper cutting:1.2)::0.6],
立绘法的前缀:
official art,1girl, simple background,[(white background:1.5)::0.2],open-mouth,(white background:1.2)
当然了,这些符号的意义将在后面详细讲解,现在看不懂也没关系
效果词为整体画面效果的提示词
例如:炫光lensflare、景深Depthoffield、 角色焦点character focus、从下面看from below等等
注意:部分固定(例如白背景立绘)这种属于风格类提示词,建议放到前缀里而非最后的背景
主体(画面中的主体部分)
主体为图画想要凸显的主体,可以是人物,建筑,景物等,主体部分要进行丰富的描述才能获得细节丰富的图像。
对于角色来说,通常包括了面部,头发,身体,衣着,姿态等描写。
没有角色时,可以将场景中的重要点即高耸如云的城堡,绽放的花朵,破碎的钟表等,想要位于画面中心的物体进行描述。
描述的顺序大致为由主到次,即你想要生成图中占据大部分画面的元素放到最前面。除此之外你想要生成违反生活常识经验/常见创作的元素的图你需要更为详细的描写或者更高的权重。
当 1 girl 和 earring 简单结合时,无论两者谁先谁后,最后都会变成“一个二次元美少女带着耳环”的样子,不会在简短描述下就轻易地出现诸如“美少女向前抬手捧着耳环、耳环在镜头前是一个特写、美少女的身体被景深虚化”的情况。因为在我们的生活常识中,大多数这两个“物”结合的情况都是前者,后者在作品描绘里出现的情况极少,因而这两者即使是顺序调换也只是让美少女是否摆出展示耳环的姿势,无法轻易地切换主次
继续深讲就到训练集的部分了,虽然它的本质是训练集与 LatentDiffusion 对于自然语言的处理,但考虑到大多数组成训练集的作品都取自于生活经验 / 常见创作想象,且自然语言处理本就是努力拟合生活经验的过程,所以实际上并无明显不同。
场景(背景,环境)
场景是主体存在的周围场景,没有场景描述时容易生成纯色背景或者是效果tag相关的背景,且主体会显得很大。部分主体会自带场景内容,例如建筑,景物。
例如:繁花草甸flowerymeadow,羽毛feather,阳光sunlight,河流river,碎玻璃Brokenglass等
此外,元素法典后期的提示词实际上并没有严格遵循三段式,具体原因是大家都开始研究分步语法,分步语法会将背景和主题放到同一模块,成为“两段式”,而非上面所说的三段式。
当然了有关分步渲染的相关内容,在下面【7.WebUI基本进阶用法】会有详细的讲解,现在看不懂也是没有关系的。
(((masterpiece))),(((crystals texture Hair))),(((((extremely detailed CG))))),((8k_wallpaper)), (1 girls:1.5),big top sleeves, floating,beautiful detailed eyes, overexposure,light shafts, soft focus,side blunt bangs, buttons, bare shoulders,(loli), character focus,wings,(((Transparent wings))),
[[((Wings made of golden lines,angel wing,gold halo around girl,many golden ribbon,Aureate headgear,gold magic circle in sky,ight, black sky):0.7):((galaxy background, snowflakes, night sky, black pupils, starts sky background, stars behind girl, view on sky,standing):0.8)],Elegant hair,Long hair,The flying golden lines,Messy golden lines,halo,hairs between eyes,Small breasts,ribbons, bowties,red eyes, golden pupil, white hair,flowing hair,disheveled hair,lowing long hair):(Delicate arms and hands):0.9]隔离元素污染
如果你在别人的提示词中看到了BREAK这个词,或者是看到了++++////\\\\这种毫无意义的符号,无需感到疑惑,这只是占位词。Stable Diffusion模型仅限在提示词中使用75个token,所以超过75个token的提示词就使用了clip拼接的方法,让我们能够正常使用。
BREAK这个词会直接占满当前剩下的token,后面的提示词将在第二段clip中处理。而早期++++////\\\\这些符号,大都是因为不知道BREAK这个词而添加上用于占token的。
输入BREAK之后你可以看到直接占满了剩下的token


为什么要使用占位词/BREAK呢?
AI在生成图像的时候会将一些提示词的特征放到其他的物品上,例如我在提示词中写了white clothes和Flower background,那么很有可能在衣服上出现花的装饰。如果我们不想在衣服上出现花的装饰,那么比较简单的方法就是把这两个词放到两段clip中处理。
自然语言“咏唱法”
自然语言的效果实际上在Stable diffusion上效果是更好的,但是由于novelai模型的训练方法和一部分LoRA/大模型训练的时候Happy lazy训练集的标注以tag为主,所以可能tag的表现更好一些。但既然是Stable diffusion模型,那么使用自然语言本身就没有什么问题,甚至于说部分时候效果还更好。例如下面提示词就混合了自然语言和tag,大家也可以自己尝试一下自然语言去写提示词。
flat design,
(official art:1.2)
(white background:1.2),
depth of field, double exposure,
(There is a big world tree with magic:1.2),
(She is inside the world tree:1.2),
1girl,solo,fullbody,
(She is a angel with beautiful detailed eyes with crystal textured hair with beautiful detailed face with (clothes)+(beautiful transparent wing)),
(She is a angel with red eyes with white hair with (clothes)+(light wings)),
(She is a girl with long flowing hair with the hair between the eyes),
(She with white dress with detached Sleeve with off_shoulder clothes),
(She with symmetrical wings with transparent wings with mechanical wings),
(She is a sitting girl with small breasts with (wariza:1.2)),
(She is far away form viewers and looking at viewers with (from side:0.5)),
(She is beside the floating cubes:1.4),
(super fucking cool golden light:1.2),
(white background:1.2),
irradiance particles, ray tracing,(The broken floor:1.3),
depth of field, tyndall effect, double exposure,
visual impact,((Ink mist,Coloured lead painting,[[Gouache painting]]):1.5)
(Glitch Art:1.414)请不要使用shit山负面
大量的负面提示词会对生成的图片产生灾难性的影响。新的tag串在编写的时候负面提示词是需要放到最后再添加的,因为无论如何负面提示词都会对画面产生一定的影响,并且很多影响是不可预见。这将会导致很多想要达到的效果无论如何也无法实现。实际上《元素法典》研究提示词的时候一般的操作是当生成图出现自己不想要的东西的时候再作为补充。
负面embedding也不是越多越好,负面embedding对构图会有影响,很多人以为越多越好从而叠一堆负面embedding,其实不用也一样能出好图。甚至好的手也不依赖负面embedding,有的时候手崩了即使用了负面embedding也不会很好的修复。

放这么多的负面embedding堆在一起,不但会严重影响提示词的准确性,还会严重影响生成图效果和模型的泛化,甚至于说能把大部分模型干成同一种风格。
前者未使用负面embedding,后者为使用embedding。可以明显的看到,使用embedding生成的图已经明显失去原本风格

5. 选择你的捍卫者“采样器”
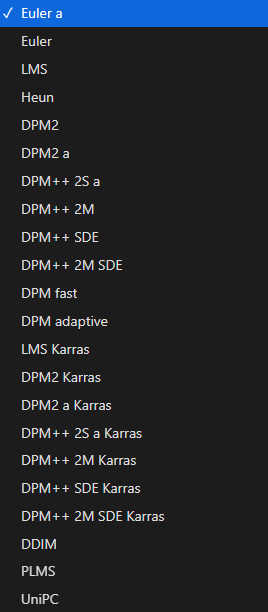
采样器sampler就是去噪的方法,WebUI中内置了很多采样器,你也可以自己装载其中没有的其他采样器。包括一般使用的Euler A和UniPC,以及很多人都喜欢使用的DPM系列。
对于初学者来说,更推荐使用Euler A或者Unipc等生成图像较快的采样方法。
采样方法组成了图片生成的第一大要素,它决定同样的 prompt 下AI会选择以何种方式去噪点化以得到最终图片。同时,它还会决定运算速度。
采样方法组成了图片生成的第一大要素,它决定同样的 prompt 下 AI 会选择以何种方式去噪点化以得到最终图片。同时,它还会决定运算速度。
通常来讲,Euler A 是兼顾速度和质量的最优之选。而 DDIM 和 Euler 则在运气较好的情况下尤其以细腻的画风见长。DPM系列则是各有优劣,部分在低steps下有着极其良好的表现(DPM三兄弟在15~20步就差不多了)
当你审美疲劳时,也可以尝试更换方法也许可以带来新的风格。
6. 迭代步数(steps)
不同采样需要的采样steps不同。
例如Euler A/DPM A等都是非线性采样,结果并非随着采样步数的增加而增加质量。恰恰相反在大于一定采样步数只会质量会快速下降。对于此类采样器推荐的最大steps一般为50左右。(不绝对)
而Euler/DDIM等线性采样随着迭代步数的增加质量会增加。当然在早期“修手”的尝试中发现,这类采样器的steps数存在边际效应的问题,大于一定数值之后,增加steps带来的收益也不会很明显。
6. 迭代步数(steps)
不同采样需要的采样steps不同。
例如Euler A/DPM A等都是非线性采样,结果并非随着采样步数的增加而增加质量。恰恰相反在大于一定采样步数只会质量会快速下降。对于此类采样器推荐的最大steps一般为50左右。(不绝对)
而Euler/DDIM等线性采样随着迭代步数的增加质量会增加。当然在早期“修手”的尝试中发现,这类采样器的steps数存在边际效应的问题,大于一定数值之后,增加steps带来的收益也不会很明显。
很多图直至steps500才会有明显的提升,而一般显卡拉500steps需要的耗时太长了,所以并不建议拉太高的steps。

7. WebUI基本进阶用法
①渲染句式
在webui中,有几种非常好用的句式可以使用:
[A:B:X]代表执行A效果到X的进度(如0.4到40%的总步数),B从X的进度开始
[A:0.5]这样写的含义是从50%开始渲染A
[A::X]渲染到X的进度的时候停止A的渲染
[A|B]交替渲染A/B
②种子融合
用于轻微调整生成图
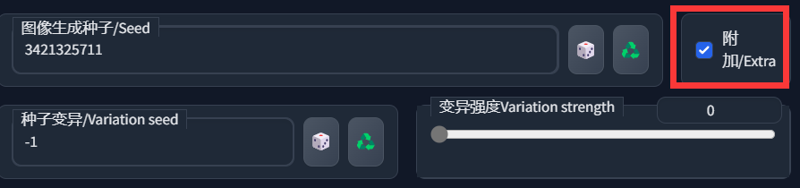
大致的效果如图所示:随机差异种子可以选择其他种子,也可以随机抽取(-1),效果图是固定了差异种子

好了,你已经学会基本用法了,尝试分析一下下面这串tag的分步吧((((
[[([(Delicate eyes,glowing eyes,red eyes, black pupil,(beautiful eyes:1.2),(serious),(gradient eyes)):[((messy_hair),(Long hair:1.2),(lightning),Lots of lightning,([white hair|Lavender hair]:1.3)):((Flowing hair:1.2),Long flowing hair,beautiful hair):0.6]:0.7],(Delicate face:1.2),(shoulder cutout),(Gorgeous clothes:1.3),(beautiful arms:1.2),(Characters stay away:1.4),(Small breasts:1.2),[[:((Scepter weapon,The thunder wand,Crystal texture of the hair):1.4):0.5]::0.9],[((lightning),many glowing ribbon,Shine tire,glowing magic circle in sky,(glowing halo around girl:1.3)):((exquisite Magic Circle:1.7),(Many purple flashes:1.4)):0.5],(Gorgeous accessories:1.2),(Gorgeous special effects:1.3),(highres:1.3),(magic:1.3),(glowing light:1.3),(exquisite magic array:1.2),(Strong vision),(Magic in hand:1.3),(starry sky:1.3),(huge Brilliant magic),(glowing light:1.2),(Dimensional space is broken),(lightning:1.3),god rays,night, black pupils,(clock method array:1.2),standing,Hair and lightning blend together,(Lightning ribbon:1.2)):(lightning:1.2):0.8]:(Delicate arms and hands):0.9]]8. 我的“法术”不听话了?增加减少权重
有的时候,提示词会出现不听话/失效的现象。
当提示词失效的时候,不妨多增加权重
例如(1girl:1.2)、(1girl)注意:这里的任何权重等的调整只能使用英文符号,使用全角/中文符号将不会起任何作用
一对小括号()意味着把括起来的 prompt 权重 * 1.1,中括号[]则是 / 1.1,大括号{}在 WEB-UI 中无调整权重作用,且会被作为文本而解析。
如果因为某些需求而要大量抬升权重,可以对 prompt 进行多次括号,比如((((prompt)))),这意味着将它的权重 * 1.1 四次,也就是 1.4641。但这个写法太吓人了,数括号也很浪费时间,所以应该直接为一个 prompt 赋予权重:
(prompt:权重乘数)外层一定是小括号而非其它括号。比如 (red hair:1.5) 将直接给 red hair 赋予 1.5 权重,(red hair:0.8)将直接给red hair赋予 0.8权重,清晰简洁,便于自己回顾和他人理解,强烈推荐。
而除了整词权重之外,也可以进行部分权重,比如如下例子:
1 girl, white long (messy:1.2) hair, red eyes将专门对 messy 部分赋予 * 1.2 权重,其它部分不受影响
高权重的元素会在画面中有着更大的占比或更强烈的存在感或更多的数量,是能可观地影响构图的原因之一。如果出现了(xxx:1.7)还无法正确的表达需要的效果时,那么大概率为模型无法识别这个提示词,或者模型本身的问题。
模型本身问题
例如模型的clip偏移:(这里要用到一个叫做CLIP tensors checker的插件)
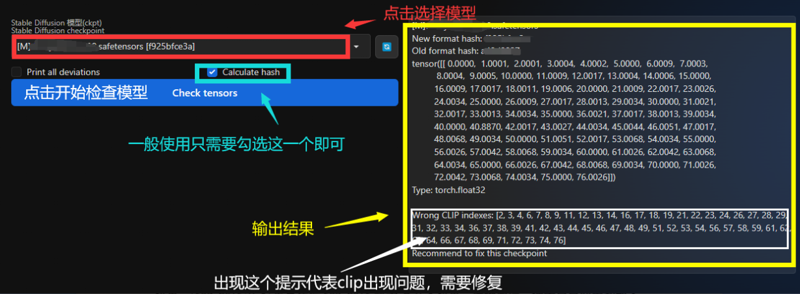
clip偏移会影响模型对于对应位置的token语义的理解,有的时候就会造成你的提示词识别出现问题,详情可以查看早期“微笑测试”实验(下面的链接)
[調査] Smile Test: Elysium_Anime_V3 問題を調べる #3|bbcmc
模型过拟合了
部分模型训练的时候出现的过拟合也会导致提示词出现不听话的情况。
许多 tag 有着逻辑上合理的“前置”关系,比如存在 sword 这个 tag 的作品往往还存在 weapon 这个 tag、存在 sleeves past finger 这个 tag 的作品往往还存在 sleeve past wrists 这个 tag。
这样在训练集中往往共存且有强关联的 tag,最终会让模型处理包含它的咒语时产生一层联想关系。
不过上述联想关系似乎不够令人感兴趣,毕竟这些联想的双方都是同一类型,哪怕 sword 联想了 weapon 也只是无伤大雅。那么是否存在不同类型的联想呢?
答案是存在的:
masterpiece, 1 girl, blue eyes, white hair, white dress, dynamic, full body, simple background
masterpiece, 1 girl, blue eyes, white hair, white dress, (flat chest), dynamic, full body, simple background
不难发现 flat chest 除了影响人物的胸部大小之外还影响了人物的头身比,让人物的身高看上去如同儿童身高一般,如果调整画布为长画布还会更明显。因此称 flat chest 与 child 有着联想关系。人物胸部大小和身高是不同的两个类型,两个看似类型完全不同的词也可以产生联想关系。对 flat chest 加大权重,会让这种联想关系会表现地更为突出。
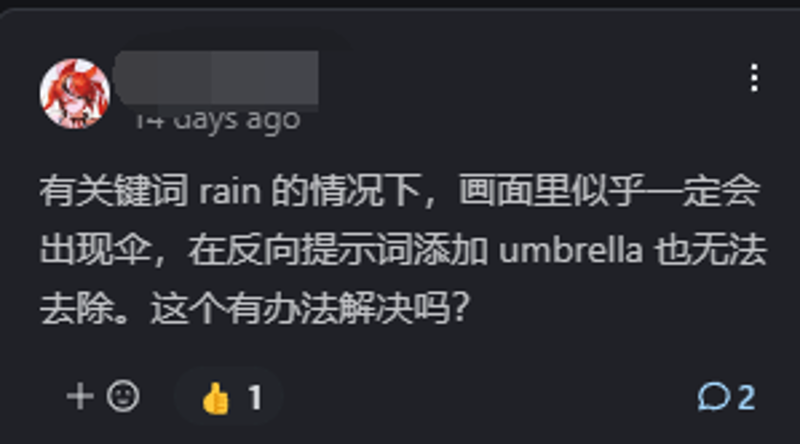
它的原理和上述同类型的联想一样,都是训练来源导致的。平胸美少女和儿童身高在同一个作品内出现的概率非常大,所以 AI 逐渐对这两个词产生了联想关系,还是强联想关系。这种联想关系在社区中曾被称为“零级污染”。
这种0级污染在不同的模型中的表现是不同的:
例如:在cf3模型中,出现了又rain的情况下一定会存在雨伞的关联现象。rain和unbrella产生了联想关系。
9. 如何使用LoRA
①首先,把你的LoRA模型放到指定文件夹(你的webui根目录\models\Lora)里面文件夹和我的不一样没关系,只要把模型放到这里就行了。如果下载了太多的LoRA模型不好找,那么就可以像我一样加入文件夹分类
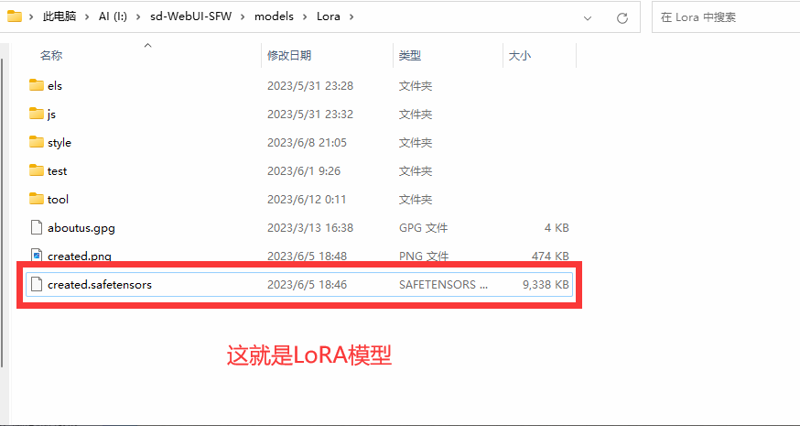
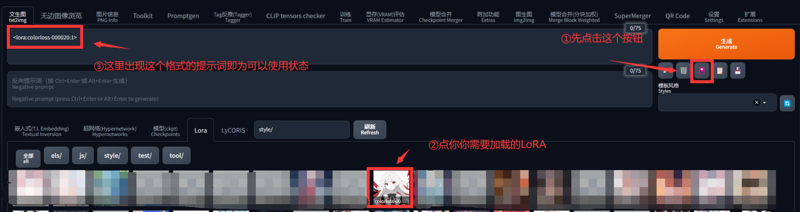
②安装图片提升,以此点击LoRA列表按钮——想要使用的LoRA,在正面提示词栏里出现 这种格式的提示词即为下一次生成所要加载的LoRA。
③如果你使用的包带有Kitchen主题,那么你的LoRA在这里
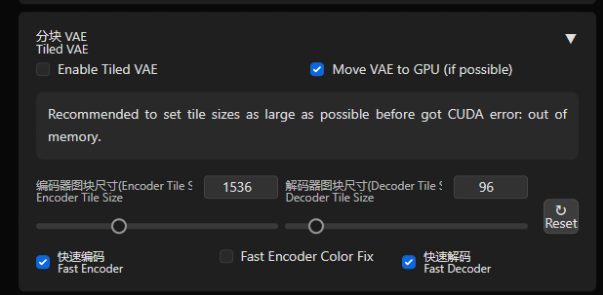
10. 画大大大大大大的图Tiled VAE
扩展插件: https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
Tiled VAE能让你几乎无成本的降低显存使用
● 您可能不再需要 --lowvram 或 --medvram。
● 以 highres.fix 为例,如果您之前只能进行 1.5 倍的放大,则现在可以使用 2.0 倍的放大。
使用方法:
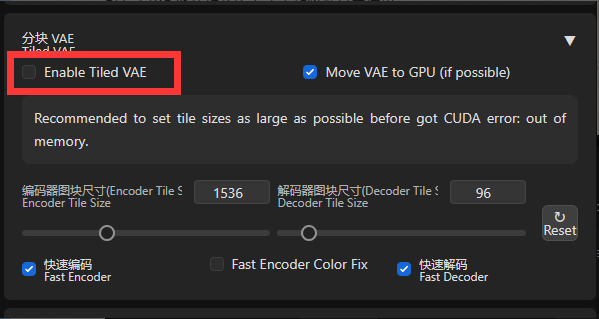
勾选红框所示的勾选框以启动Tiled VAE
在第一次使用时,脚本会为您推荐设置。
因此,通常情况下,您不需要更改默认参数。
只有在以下情况下才需要更改参数:当生成之前或之后看到CUDA内存不足错误时,请降低 tile 大小
当您使用的 tile 太小且图片变得灰暗和不清晰时,请启用编码器颜色修复。
stableSR
扩展插件:https://github.com/pkuliyi2015/sd-webui-stablesr
功能:更强大的图片放大
扩展详细用法请看以下链接:https://github.com/pkuliyi2015/sd-webui-stablesr/blob/master/README_CN.md
我们保留了一点点Junk Data:请选择你的模型
1. Stable Diffusion的工作原理
这一方面看不懂可以直接跳过,不了解并不影响实际使用

①首先我们输入的提示词(prompt)会首先进入TE(TextEncoder),而clip就是stable diffusion所使用的TE。TE这部分的作用就是把tag转化成U-net网络能理解的embedding形式,当然了,我们平时用的emb模型,就是一种自然语言很难表达的promot。(简单的说就是将“人话”转换成AI能够理解的语言)
②将“人话”转换成AI能够理解的语言之后,U-net会对随机种子生成的噪声图进行引导,来指导去噪的方向,找出需要改变的地方并给出改变的数据。我们之前所设置的steps数值就是去噪的次数,所选择的采样器、CFG等参数也是在这个阶段起作用的。(简单的说就是U-net死盯着乱码图片,看他像什么,并给出更改的建议,使得图像更加想这个东西)
③一张图片中包含的信息是非常多的,直接计算会消耗巨量的资源,所以从一开始上面的这些计算都是在一个比较小的潜空间进行的。而在潜空间的数据并不是人能够正常看到的图片。这个时候就需要VAE用来将潜空间“翻译”成人能够正常看到的图片的(简单的说就是把AI输出翻译成人能看到的图片)
经过以上三个步骤,就实现了“提示词→图片”的转化,也就是AI画出了我们想要的图片。这三个步骤也就对应了模型的三个组成部分:clip、unet、VAE
2. 好模型在哪里?
同时满足:提示词准确、少乱加细节、生成图好看、模型本身没有问题的模型,我们就能称之为好模型。
提示词准确:顾名思义,就是tag提示词的辨别能力越高越好。提示词辨别能力差,那么我们就难以达到想要的效果。
少乱加细节:指的是产生提示词中并不包含的细节,这会影响提示词对于生成图的控制能力。放在模型训练上就是在训练集中大量使用强关联性质tag的图片造成了过拟合。例如在nai模型中flat chest会强制带有child的效果/在Counterfeit-V3.0中rain提示词会强制带有Umbrella,这也是之前所说的“0级污染”。乱加细节不能彻底避免,只能是越少越好。
生成图好看:这没什么好说的,生成图无论如何都是炸的话,那这个模型也就没有存在的必要了。
模型本身没有问题:一般而言是指不含有Junk data和VAE没有问题的模型
3. 讨厌的junk data
junk data就是指垃圾数据,这些数据除了占用宝贵的硬盘空间外毫无作用。一个模型里只有固定的那些内容才能够被加载,多出的全是垃圾数据。一般而言一个6.5Gb的模型,实际生成图片所用到的只有3.98Gb。模型并不是越大越好
这些东西大部分都是EMA,模型在Merge后EMA将不再准确反映UNET,这种情况下EMA不止没啥用,还会影响模型的训练。所以在尝试融合模型时期,请先使用工具删除模型EMA权重(后面讲模型融合的时候会提到)
4. 你的AI浓度超标了!
近一段时间大家的模型同质化都是比较严重的,按照出图效果分类可以将这一部分融合模型模型分为:橘子、蜡笔、Anything、cf等多种系列,每一种系列中的不同模型实际上都效果相差不大,完全没有必要去下载全部的模型。
之前不了解AI的人所说的“AI浓度超标”“AI味”,其实指的是橘子(AOM)这一系列模型的风格,具体效果是人物身体的表面有一种油光,多了解之后你就会发现,类似这种一整个系列都会有相似的风格。
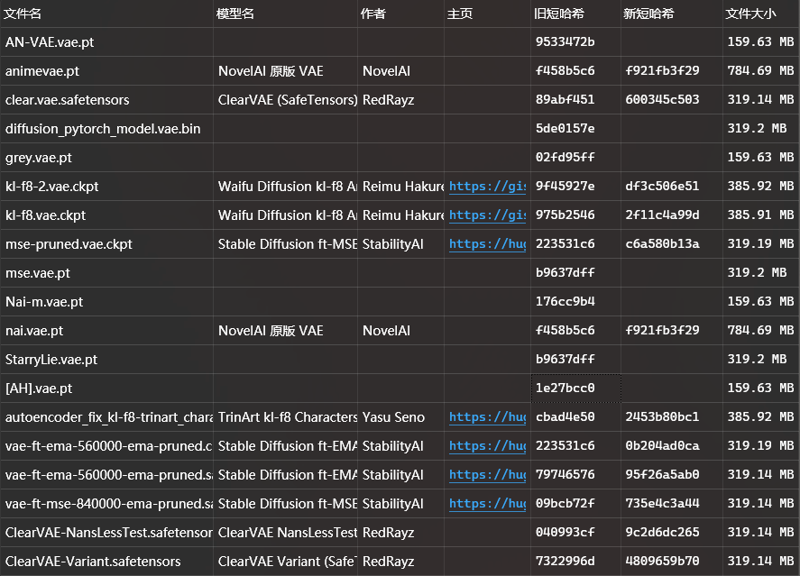
5. 你的VAE?不,是你的VAE!
VAE重复问题是比较严重的,例如Anything V4.5 VAE,实际上和novelai的VAE是完全相同的,有不少模型自带的VAE是使用了其他的VAE并且只是更改了文件名称而已,实际上这些VAE的哈希值都是完全相同的。相同的VAE无需重复下载,这些完全重复的VAE除了占用宝贵的硬盘空间外毫无作用。
下面是笔者这里所有的VAE的哈希对照:(当然并不是全部,肯定还有其他的)
掌控全局:ControlNet控制网
ControlNet是stable diffusion的一个插件,它可以通过添加条件图片的形式来自定义很多内容达到自己想要的效果
扩展插件: https://github.com/Mikubill/sd-webui-controlnet
ControlNet的保存库: https://github.com/lllyasviel/ControlNet
1. ControlNet基本功能
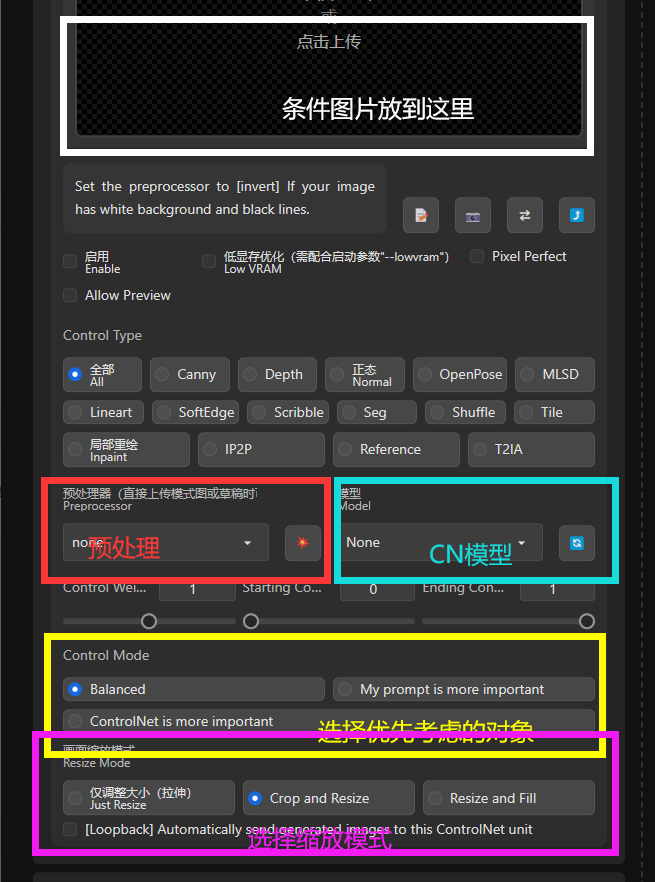
想要使用控制网,首先需要点击Enable不然再怎么调整都是没有任何效果的
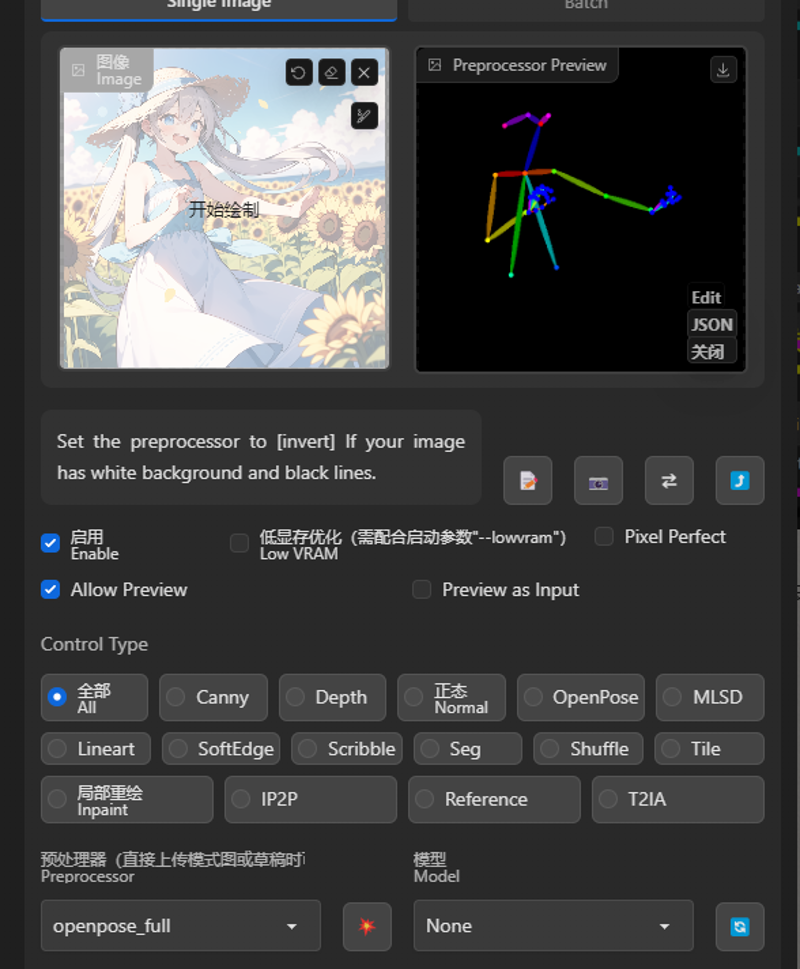
图片位置:你可以选择需要使用的图片导入至此,用以制作模板
预处理:指你想要如何处理上传的模板图片。对应的控制网模型需要与之相对应的模板。点击红色按钮即可先行对于模板图预处理
CN模型:选择你要使用的模型,例如人物姿态控制就需要使用openpose,想要切换图片的白天黑夜状态就需要使用shuffle,不同的模型对应不同的功能
选择优先考虑对象:给提示词更好的表现还是给控制网更好的表现
选择缩放模型:你可以类比为windows系统的壁纸,可以调整生成图和模板分辨率不同的时候如何处理。
Control Type:图上没标注,为不同模型的预设设置,很方便。

另外还有这三个选项并不是很常用:从左到右的顺序是控制网权重、控制网介入时机、控制网引导退出时机。实际效果顾名思义即可。
2. 推荐教程
我这里不可能讲解的面面俱到,而且很多内容仅停留在会用上,你可以查看一些up的视频来学习
ControlNet1.1场景氛围转换_哔哩哔哩_bilibili
3. 基本的控制网工作流举例
AI立绘图片生成
parameters:生成信息
非lora立绘法起手式:(注意这里请不要使用立绘lora)
official art,1girl, simple background,[(white background:1.5)::0.2],open-mouth,(white background:1.2)+具体人设tag
想加的可以加一个加个(实际上加不加都行)这个lora,在秋叶视频有这个lora的分享
————————————
其次是对应的contronet设置,具体参数如下图所示,预处理选无,模型使用openpose,模板图在最下面,分三种体型
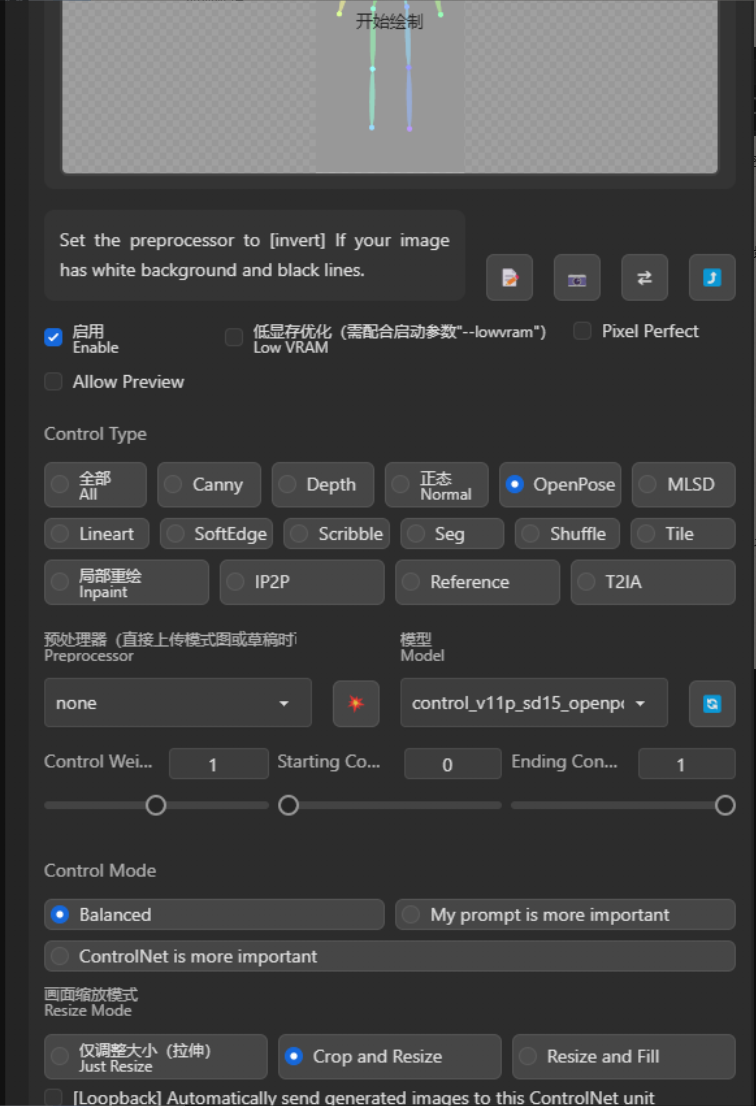
最后是其他设置:
采样方式随意,Euler和DPM、UniPC均可
开启高清修复,放大倍率为2
输出图尺寸推荐512*1280
————————————
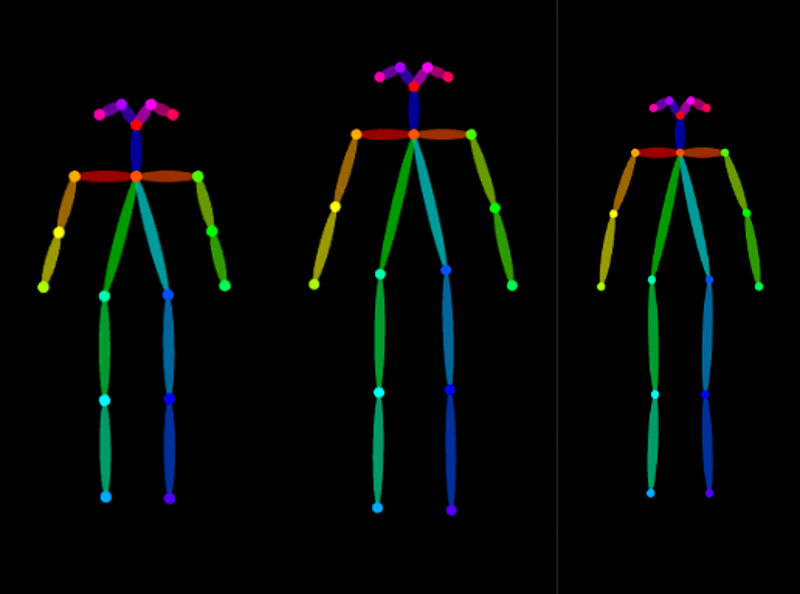
附不同体型Openpores模板图:萝莉/少女(少年)/成女(成男)
我们可以炼丹了,你不觉得这很酷吗?(lora)
1. 没有脚本,炼个P
这里推荐使用秋叶的LoRA模型训练包
也可以使用Kohya的训练脚本
或者是HCP-diffusion-Webui
不推荐使用任何一键炼丹炉
2. 开始训练的准备工作
①首先你需要一个6GB以上显存的NVIDIA显卡,如果没有,可以尝试云端炼丹
②你需要一个祖宗级基础模型sd1.5 2.0等,不推荐使用任何融合模型。
③如果使用非秋叶包,那么你还需要在webui上使用tagger插件
④准备训练集:
训练集打标可以使用秋叶整合包中的tagger模块,也可以使用webui中的tagger插件。但是需要注意:任何AI打标都不可能100%准确,有条件尽可能人工筛查一遍,剔除错误标注
一般而言需要准备一个训练集文件夹,然后文件夹中套概念文件夹
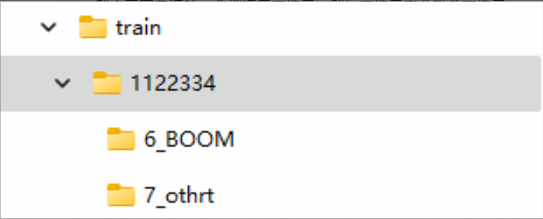
命名格式为:x_概念tag
x为文件夹中图片的重复次数(repeat)
【这个参数不在训练UI里调节,而是直接在文件夹名称上调节】
注意:训练集是LoRA训练的重中之重,训练集直接决定了LoRA模型的性能
3. 你所热爱的,就是你的参数①学习率设置
UNet和TE的学习率通常是不同的,因为学习难度不同,通常UNet的学习率会比TE高 。
我们希望UNet和TE都处于一个恰好的位置,但是这个值我们不知道。
如果你的模型看起来过度拟合,它可能训练Unet过头了,你可以降低学习率或更少的步数来解决这个问题。如果你的模型生成噪点图/混乱难以理解的图片,那至少需要在学习率的小数点后面加个0再进行测试。
如果模型不能复刻细节,生成图一点都不像,那么就是学习率太低了,尝试增加学习率
降低TE学习率似乎对分离对象有好处。如果你在生成图片过程中发现了多余的物品,那么就需要降低TE学习率
如果您很难在不对提示进行大量权重的情况下使内容出现,那么你就需要提高TE学习率。
更好的方法是先使用默认参数训练测试,然后再根据测试的结果来调整对应的参数。(秋叶训练包里的默认参数都是自带的)
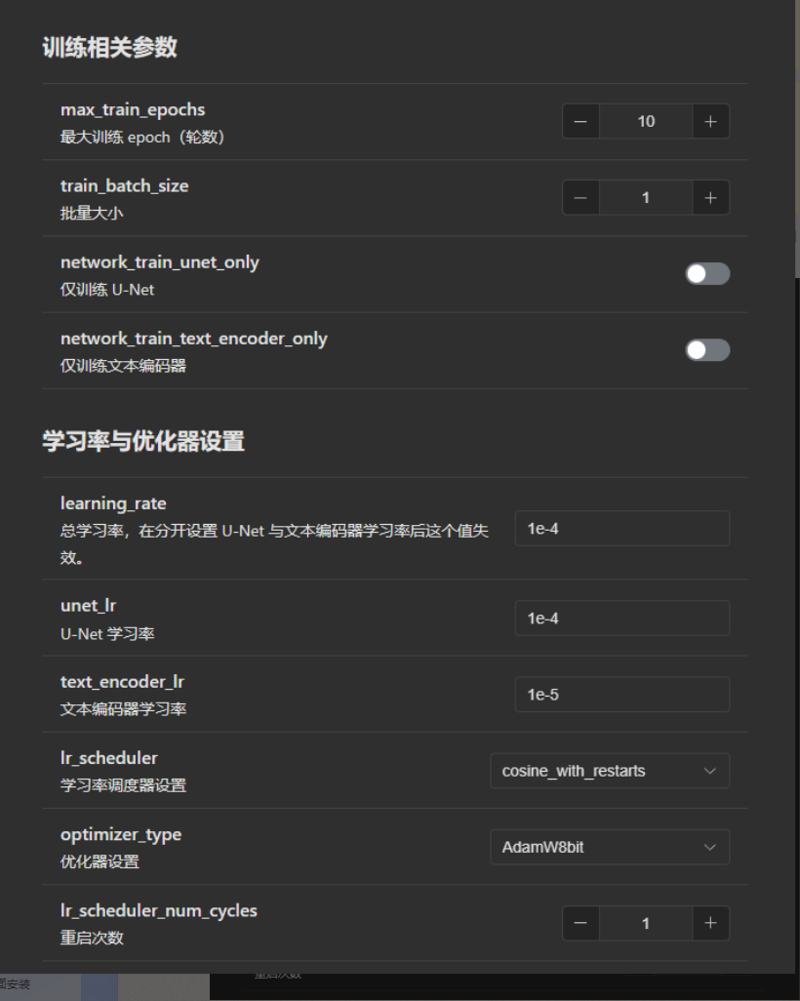
②优化器
AdamW8bit:默认优化器,一般而言不了解/不知道测试结果的直接使用这个优化器即可
AdamW:占用显存更高,但是比8bit效果更好一点
DAdaptation:自适应调整学习率,显存占用极高。有不少人使用这个优化器来摸最开始使用的学习率
SGDNesterov8bit:极慢,不推荐使用
SGDNesterov:极慢,不推荐使用
AdaFactor:(笔者没用过)似乎效果比DAdaptation好很多
Lion:占用显存较高,效果极好,但是比较难以控制,需要bs或者等效bs大于64才能达到极佳的效果。
Lion8bit:占用显存可能更低
③调度器设置
linear:不断下降,直到最后为零。
cosine:学习率呈余弦波形上下波动。
cosine_with_restarts:(没用过带其他人补充)
polynomial:类似linear,但曲线更漂亮
constant:学习率不会改变。
constant_with_warmup:类似于constant,但从零开始,并在warmup_steps期间线性增加,直到达到给定值。
④噪声设置
noise_offset:在训练中添加噪声偏移来改良生成非常暗或者非常亮的图像,如果启用推荐为 0.1
金字塔噪声:增加模型生成图亮度对比和层次感,效果极佳建议开启
4. 过拟合和污染
①触发词和过拟合,并没有十分严格的界定,除非一些lora是过拟到非常糟糕,直接吐原图那种。毕竟训练人物特征本身就需要一定的“过拟合”
②训练中常见污染,主要是因为打标器认不出或者遗漏(训练集质量),还有大模型的部分问题导致更容易被诱发的特征,包括:
混入其中的奇怪动物。
喜欢侧视和背视。
双马尾/兽耳。
胳膊喜欢披点东西(比如外套)。
出现此类情况可以先先检查训练集和标注,然后再更换模型测试
另外:角色的不对称特征请处理使其尽量在同一侧,且不要开启训练时镜像处理。
5. 删标法之争,没有绝对的对与错
在角色训练方面,一直有两种不同的观点
删除所有特征标:多用于多合一,优点是调用方便,一两个tag就能得到想要的角色特征,但缺点是
一些特征可能受底模影响发生偏移。
要换衣服和nsfw比较困难。
容易出现不同概念的相互污染。
提示词严重不准确
删除部分特征标:仅删除多个决定角色特征的tag标注
全标:优点是提示词准确,但是部分角色效果可能不好出现(还原性较差)
是否删标取决于自己想要什么:假设说我的训练图是一个红色的苹果,如果我们标注这个苹果是红色的,那么你可以在生成图片的时候生成出绿色的苹果。如果我们只标注苹果,那么这个红色的就作为苹果的固有属性,只要出现苹果,那么就是红色的。
6. LoRA进阶训练方法
分层训练:https://www.bilibili.com/video/BV1th411F7CR/
完美炼丹术,差异炼丹法:https://www.bilibili.com/video/BV11m4y147WQ/
LoRA BW插件:https://github.com/hako-mikan/sd-webui-lora-block-weight
不是所有人都有4090的(dreambooth)
1. 没有显卡,炼个P(基础准备)
DreamBooth对于显存的最低要求就已经达到了12GB,想要一些其他的效果还需要更高的显存。
DreamBooth有着比LoRA更简单的训练方法和更强的模型效果。
2. 简介
DreamBooth 是一种定制个性化的 TextToImage 扩散模型的方法。仅需少量训练数据就可以获得极佳的效果。
DreamBooth 基于 Imagen 研发,使用时只需将模型导出为 ckpt,然后就可以被加载到各种 UI 中。
然而,Imagen 的模型和预训练的权重都不可用。所以最初的 Dreambooth 并不适用于稳定扩散。但后面diffusers实现了 DreamBooth 这一功能,并且完全适配了 Stable Diffusion。
Diffusers 提供跨多种模态(例如视觉和音频)的预训练扩散模型,作为扩散模型推理和训练的模块化工具箱提供支持。
3. 选择
l 适用于喜欢高训练自由度的推荐使用HCP-Diffusion
l 适用于 本地/AutoDL 的 DreamBooth 版本,由 Kurosu Chan 提供。
l 适用于 AutoDL 的 DreamBooth 版本,由 https://www.bilibili.com/video/av348289643 提供。
l 适用于 WebUI 的 插件,注意这会在启动脚本锁一个新的 Torch CUDA 版本,可能会带来网络问题与兼容问题等。
l 适用于 Colab 的 笔记本,由 Nyanko Lepsoni 提供。
l 适用于 Colab 的 RcINS 的 Colab 笔记本
l (Colab 笔记本来自 社区置顶)
4. 数据集
数据集的创建是在 Dreambooth 训练 中获得良好、稳定结果的最重要部分。
class 和 instance 的质量决定生成的质量。
内容要求
一定要使用高质量的样本,运动模糊或低分辨率等内容会被训练到模型里,影响作品质量。
当为一个特定的风格进行训练时,挑选具有良好一致性的样本。理想情况下,只挑选你要训练的艺术家的图像。避免粉丝艺术或任何具有不同风格的东西,除非你的目标是像风格融合。
对于主题,黑色或白色背景的样本有极大的帮助。透明的背景也可以,但有时会在主体周围留下白色轮廓。
如果需要使你的 Dreambooth 模型更加多样化,尽量使用不同的环境、灯光、发型、表情、姿势、角度和与主体的距离。
请确保包括有正常背景的图片(例如,对象在一个场景中的图片)。只使用带简单背景的图片,效果会比较差。
避免在你的渲染图中出现手粘在头上的情况,请删除所有手太靠近或接触头部的图片。
如果需要避免渲染图中出现鱼眼镜头效果,可以删除所有自拍图片。
为了避免不自然的过度模糊,确保图像不包含假的重景深或虚化。
数据集规范化
一旦你收集了数据集的照片,将所有图片裁剪并调整为 512x512 的正方形(你可以利用WebUI的训练工具批量裁剪),并删除任何水印、商标、被图片边缘切断的人/肢体,或其他你不希望被训练的内容。以 PNG 格式保存图像,并将所有图像放在 train 文件夹中。当然你也可以开启Arb桶。
处理
处理图片的方式有许多,常见的有反转,旋转,亮度和裁切。将图片打碎或者对背景 / 大头等单独裁切,也许有助于提高训练效果。
5. 开始训练/请相信默认参数
【PS:由于笔者多使用HCP-diffusion进行训练,与参考文档部分内容有所不同,所以部分操作内容可能无法很好的讲解,固暂且搁置】
【我自己仅能讲解经验类的东西,以及我所使用的方法,并不能解释其原理】
总有人不相信默认的参数,去问群友得出了更离谱的答案。新人想要入坑dreambooth请先使用默认参数,然后再根据实际效果调整对应的参数。
模型Merge,并不科学但确实有效
1. 你权重乱了
①模型融合必将使得ckp大模型难以继续训练。
②融合模型前请先去除模型中的EMA权重:
模型在Merge后EMA将不再准确反映UNET,这种情况下EMA不止没啥用还会占用宝贵的硬盘空间
③模型融合并不科学,但是仅从生成图片效果上来看:确实会有不错的效果
④部分模型融合对应提示词或者拟合的影响是灾难性的
2. 传统模型merge
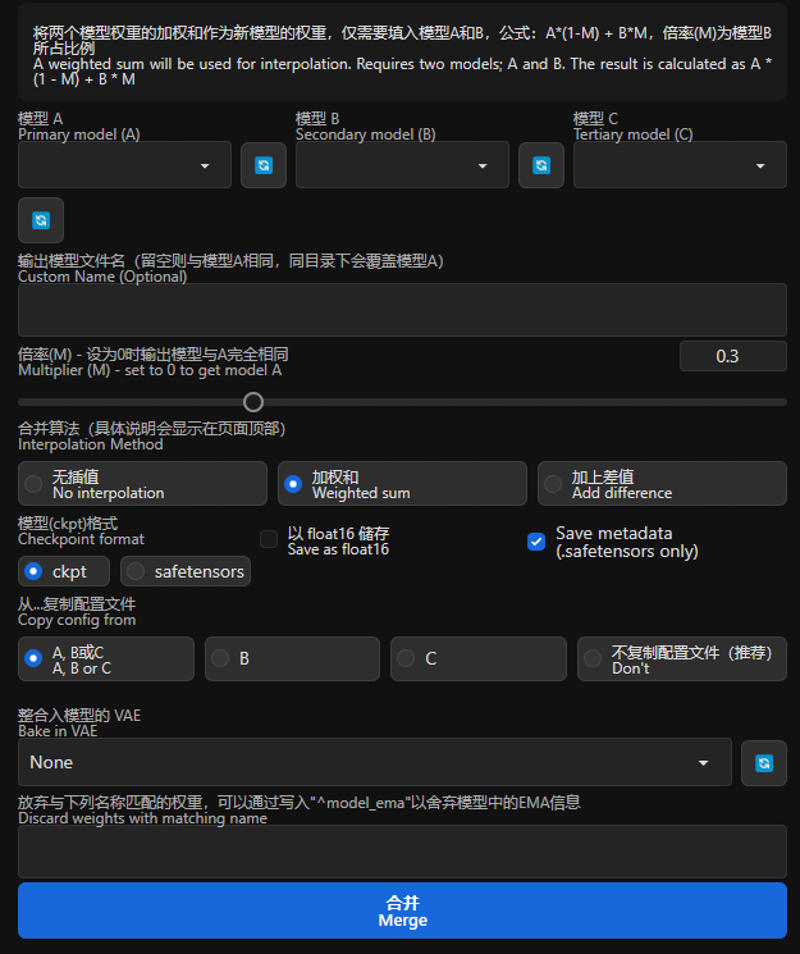
① 选择模型
A、B、C
②设置新模型名字
一般来说可以设置为xxxMix(xxx为你想要的名称,Mix代表融合模型)
在这里设置模型的名字。
③设置Merge比例
传统融合有两种方式,分别为:
加权和Weighted sum:将两个模型权重的加权和作为新模型的权重,仅需要填入模型A和B,公式:A*(1-M) + B*M,倍率(M)为模型B所占比例
加上差值Add difference:将模型B与C的差值添加到模型A,需要同时填入模型A、B和C,公式:A + (B-C)*M,倍率(M)为添加的差值比例
④选择fp16
请直接选择fp16,默认情况下,webui 会将所有加载的模型转换为FP16使用。所以很多时候更高的精度是没啥意义的,不使用--no-half这些模型将完全相同。而实际上哪怕使用--no-half,模型的差别也并不会很大,所以直接选择fp16测试效果即可。
⑤Merge

点击它后等待一会即可,模型在你的webui根目录下的models/Stable-diffusion文件夹。
需要注意的是:传统融合效果并非比现在的mbw等操作效果差
3. Merge Block Weighted
插件基本功能:
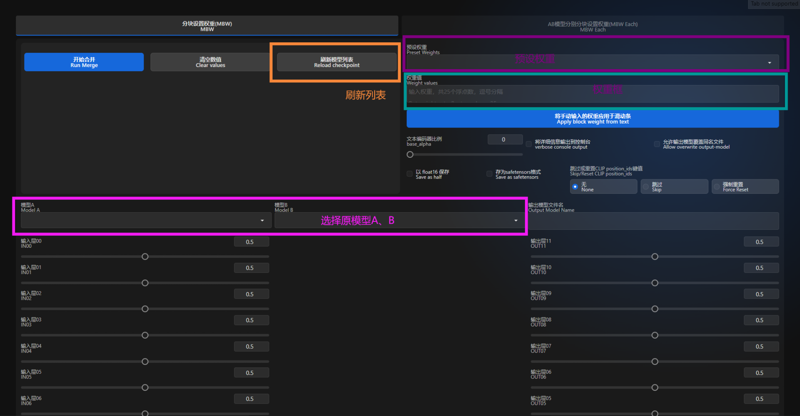
开始合并:点击后直接开始融合
清空数值:将下方的滑条全部置为0.5
刷新模型列表:刷新模型列表。在webui开启状态下,如果模型文件夹新加入了模型,那么将会无法自动识别。如果原模型区域找不到新加入的模型,那么点击这里即可刷新模型列表
模型A:选择需要融合的模型A
模型B:选择需要融合的模型B
输出模型文件名:你要输出的模型文件名称,通常为xxxMix
预设权重:官方预设融合权重,选择后直接加载进下面的滑块
权重框:输入自定义的融合权重,输入完成后点击下面的按钮直接加载进滑块
文本编码器比例:A和B模型的语义分析模块的融合比
跳过或重置CLIP position_ids键值:防止clip偏移导致模型出现各种提示词识别问题,强烈建议选择:强制重置Force Reset
MBE能达到的效果:
画风更换、人体修复、修复过拟合模型、剔除污染层等
更详细的MBW详解:
https://docs.qq.com/doc/DTklkTllGQmdac3Jl
4. LoRA的注入与提取
扩展插件:hako-mikan/sd-webui-supermerger: model merge extention for stable diffusion web ui
插件基本功能除了MBW以外还有LoRA处理的相关功能:当然更多进阶的功能可以到插件仓库去查阅README.md,这里不做更详细的讲解。
通过两个ckp大模型之间做差可以得到一个LoRA。需要注意的是这里需要在filename(option)这一栏输入想要的名称,不然无法提取
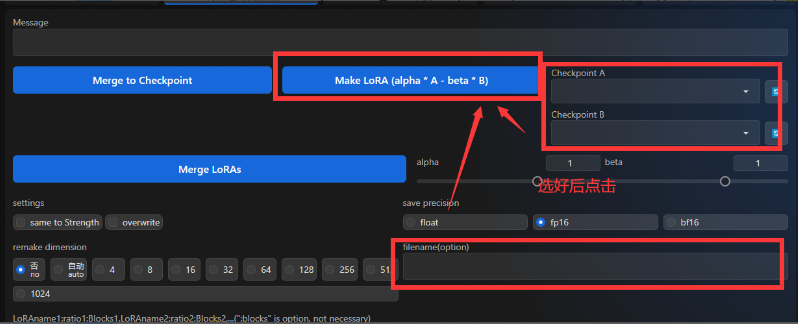
点击下面的LoRA然后在上面选择模型,就可以把LoRA注入到ckp大模型里(同样需要在filename(option)这一栏输入想要的名称,不然无法注入)。需要注意的是,这里只能操作LoRA,并不能操作Loha等一系列其他模型,如有报错请检查模型格式是否正确。
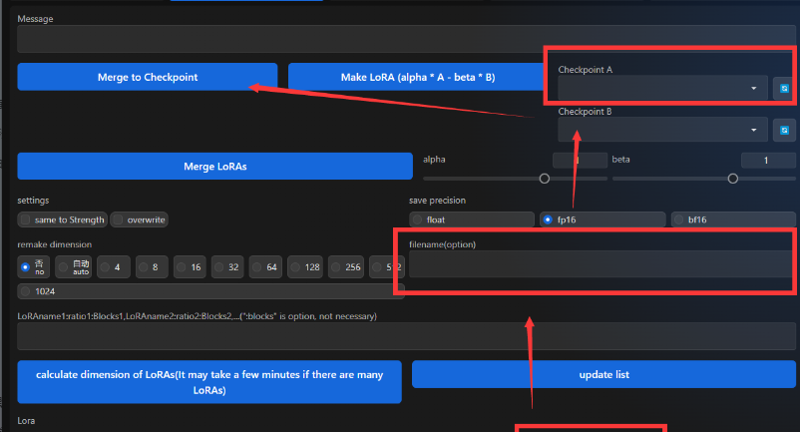
注意:部分模型做差提取LoRA后使用和原ckp模型效果有所差距,部分LoRA注入后和直接使用效果也有可能有差别,具体是否可用请根据不同的模型自行测试
5. 灾难性遗忘与模型融合
目前已有的大部分dreambooth模型灾难性遗忘现象较为严重(排除掉lora是外挂的 其余的微调大部分层次的训练都可能有这个现象),而模型融合会放大这个现象。
由于现在的dreambooth训练以“1girl”为主,所以现在绝大部分的二次元融合模型都是只能画“1girl”了,很多仅仅描述景物的提示词甚至都会出现“1girl”。
更多的功能,更多的插件,无限的可能
注意:安装扩充功能可能会导致Stable Diffusion WebUI启动变慢,甚至无法启动,并且哪怕使用启动器也无法扫描出异常。
请不要自行下载DreamBooth的WebUI插件!!!
请不要自行下载DreamBooth的WebUI插件!!!
请不要自行下载DreamBooth的WebUI插件!!!
自行下载dreambooth插件并且炸了的唯一最佳解决方法:重装WEBUI
1. 用Webui图形界面安装
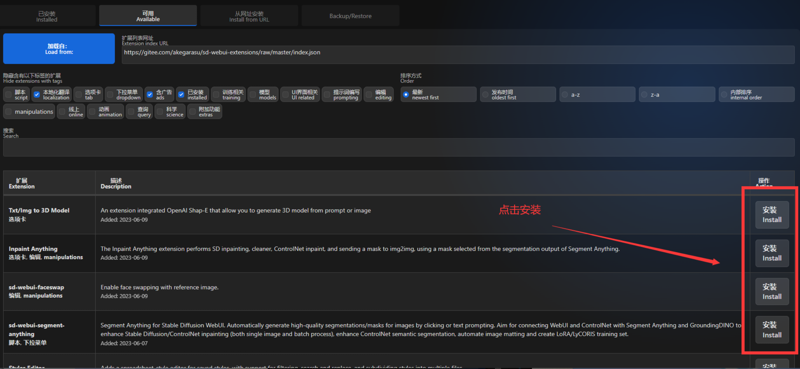
①最简单的方法就是点击Extensions → Available的Load from:,就会列出可下载安装的扩充功能,点击安装
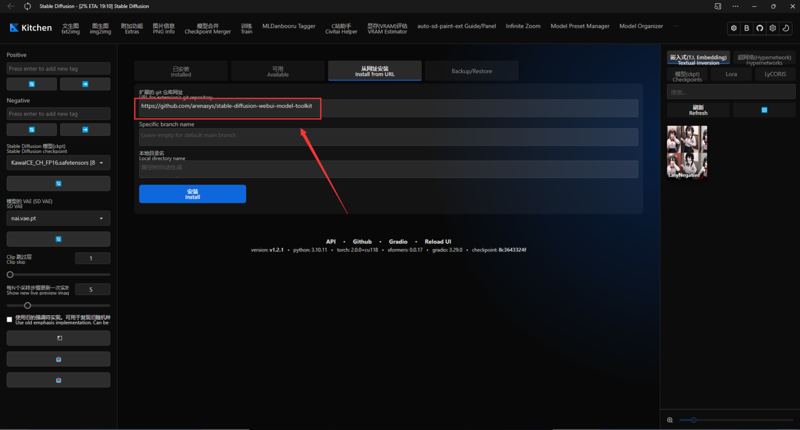
②部分不在列表的插件,需要将Github库链接直接填入WebUI插件下载区,等待自动加载完毕即可
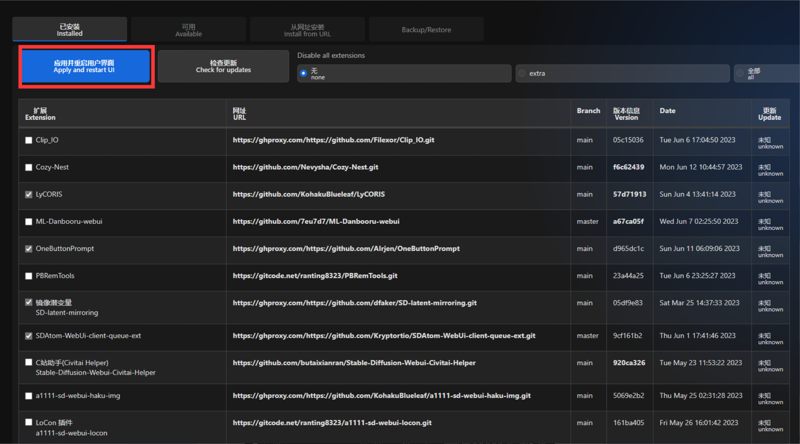
③安装完成后必须点击这里重启UI网页界面才能使用,有的插件则是需要“大退”,即关闭Webui实例,重新启动。
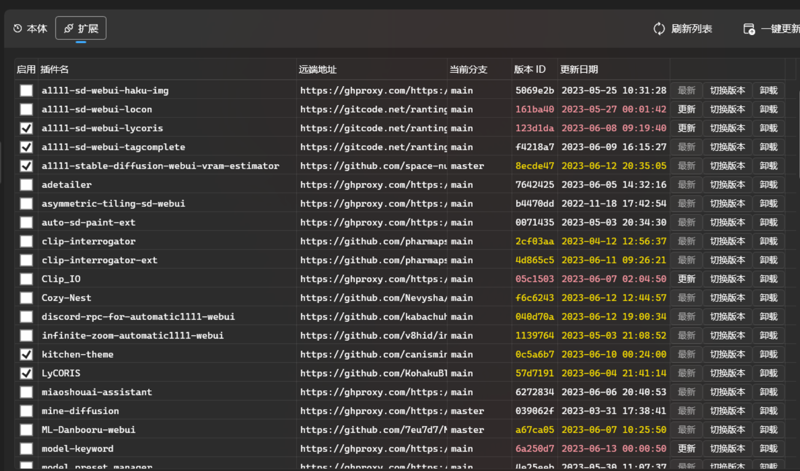
④windows系统更新扩展插件推荐使用启动器,而非Webui内的检查更新。webui内的检查更新大概率会卡住。(国内用户)
2. 使用git安装
①(安装前需要关闭你的webui实例)在你的webui根目录/extensions文件夹打开终端,运行git clone指令,安装扩充功能。
例如:
git clone https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111.git②打开WebUI,你就会看到新安装的扩展功能
③windows系统插件更新同样可以使用启动器进行更新
如果是Linux系统,可以在你的webui根目录/extensions文件夹打开终端,并运行以下指令:
ls | xargs -I{} git -C {} pull3. 使用压缩包安装
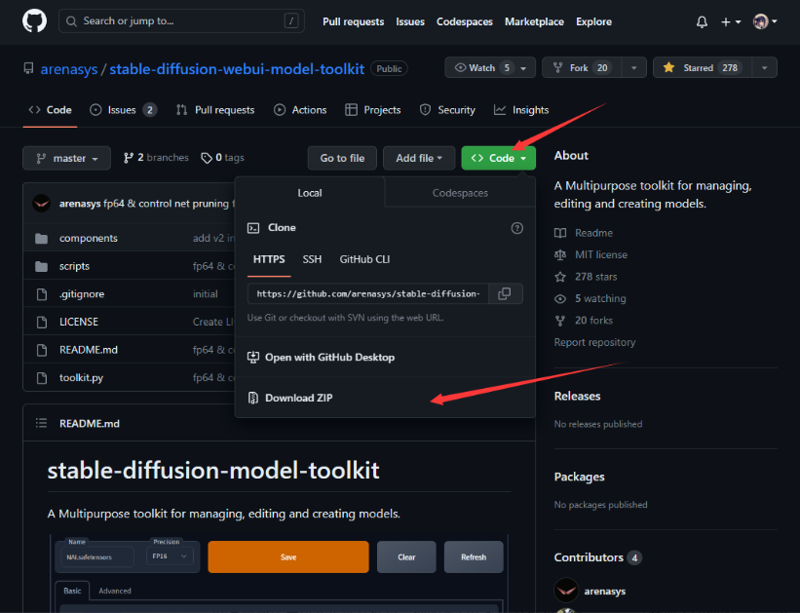
①github界面点击【Download ZIP】
注意:请在尝试了其他安装方式并且均失败的情况下再选择直接下载zip解压
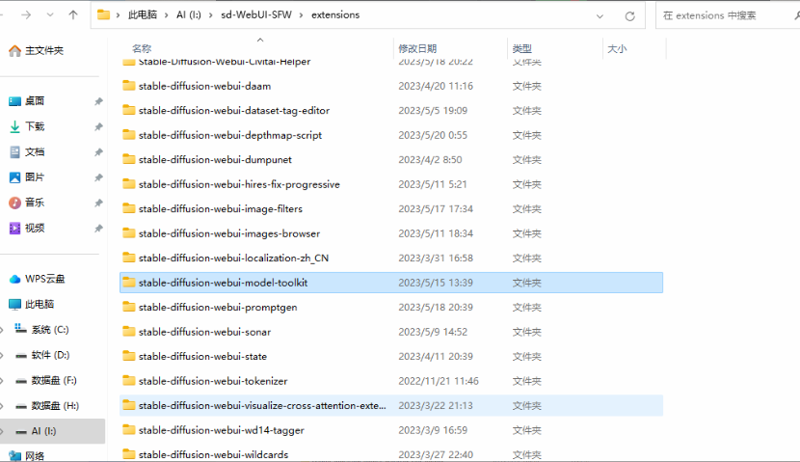
②完整解压后放在扩展文件夹:你的WebUI所在文件夹/extensions(需要关闭你的webui实例)
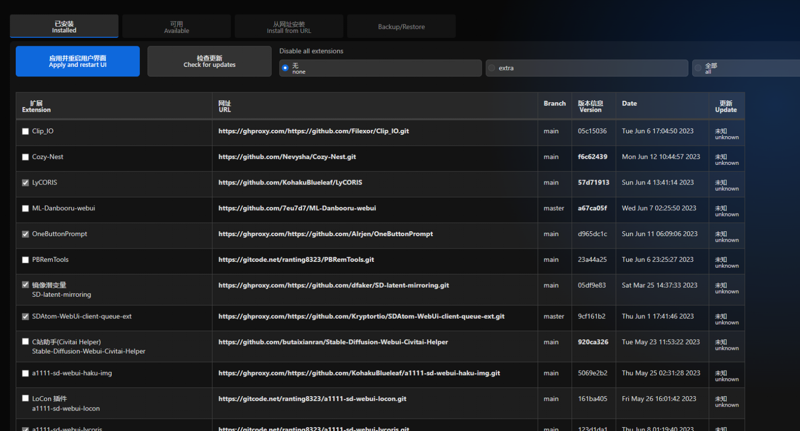
③重新开启webui后能在插件列表中看到即为安装成功
4. 停用、卸载、删除插件
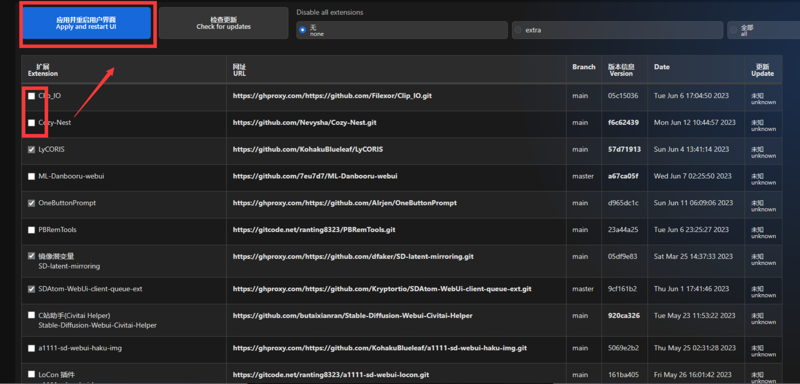
①对于暂时不使用插件,点击扩展前面的✔并且重启用户界面即可
②删除、卸载插件最简单的方法是在启动器界面点卸载(卸载插件前请关闭你的Webui实例)
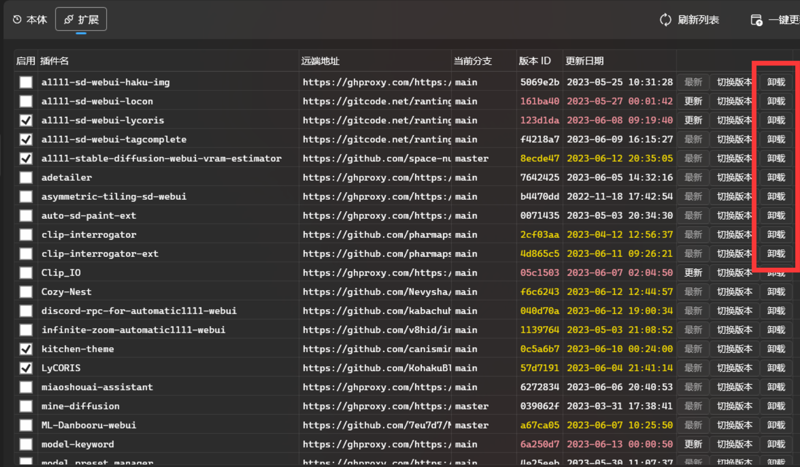
或者打开你的WebUI所在文件夹/extensions,直接删除插件文件夹即可
请远离玄学民科
1. 说明
AI绘画使用的超低门槛与实际研究群体的超高门槛之间存在着非常严重的断层。这就意味着玄学民科的内容会非常的多。
https://docs.qq.com/doc/p/a36aa471709d1cf5758151d68ef5b59397421b2e
这个文档反驳了非常多的玄学民科内容,然而还有更多的玄学民科内容还在等着我们去科普
2. 现状
SD目前并没有专门的交流社区/或者说即使有交流社区那么环境也是比较差的(例如猫鼠队),而一般的网站又过于简单零碎各自为阵的群聊也有一部分人在输出玄学民科内容,并且还有相当的一部分人进行吹捧。而刚接触的新人也没啥分辨能力,自然而然的会出现,玩了几个月发现自己玩的都是垃圾,或者自己也加入输出这种内容等等情况。
彻底卸载Stable Diffusion Webui
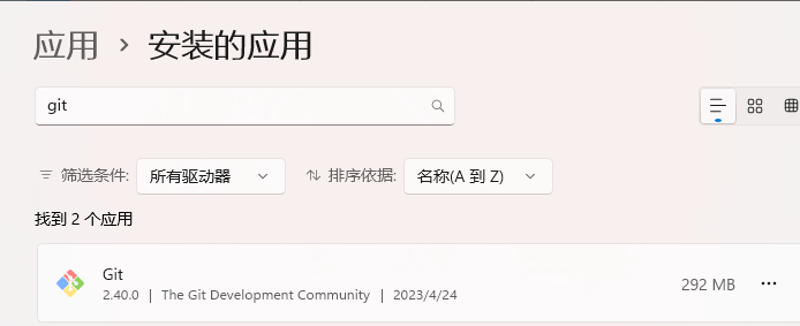
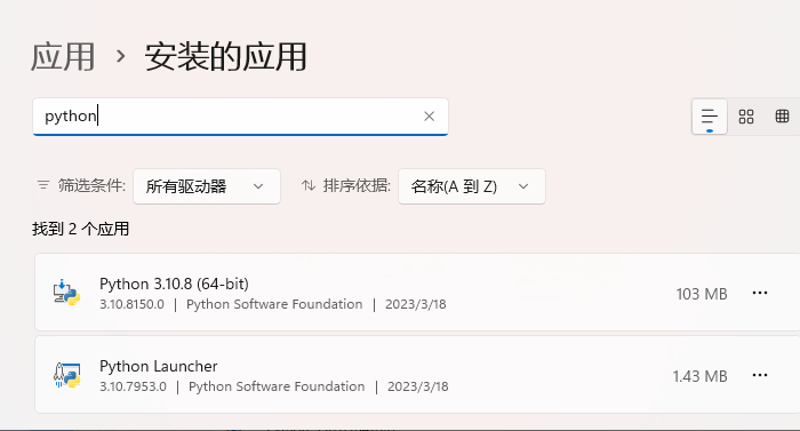
1. 删除环境/软件
python、git等软件都可以在windows系统内设置界面直接卸载,直接打开设置-应用-安装的应用搜索卸载即可
2. 删除Webui本体
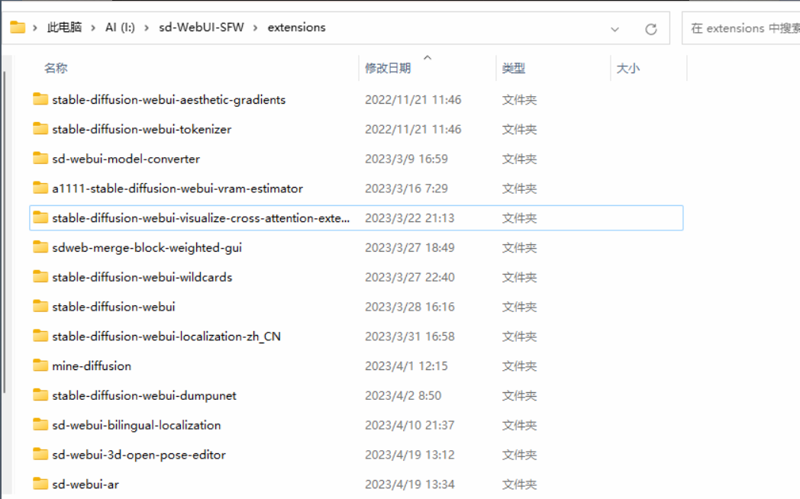
直接删除Webui目录文件夹即可。
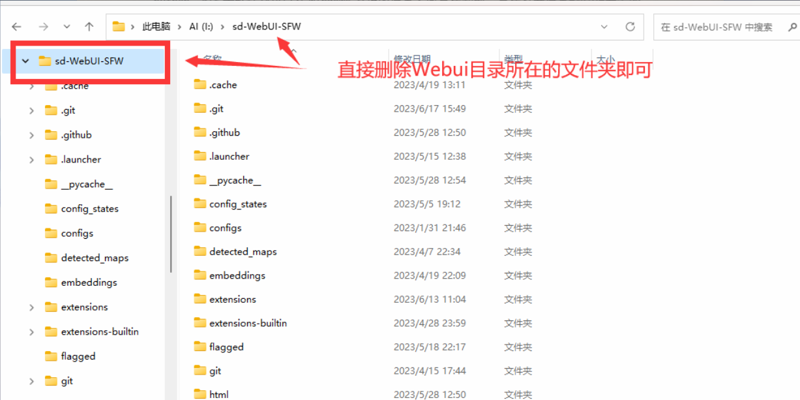
注意这里有一个魔鬼细节:请不要在windows资源管理器内直接右键删除文件夹,如果这样直接删除,那么大概率需要几个小时的时间来检索文件目录。长期使用的stable diffusion Webui本体很可能有几十万个文件,检索相当耗时。
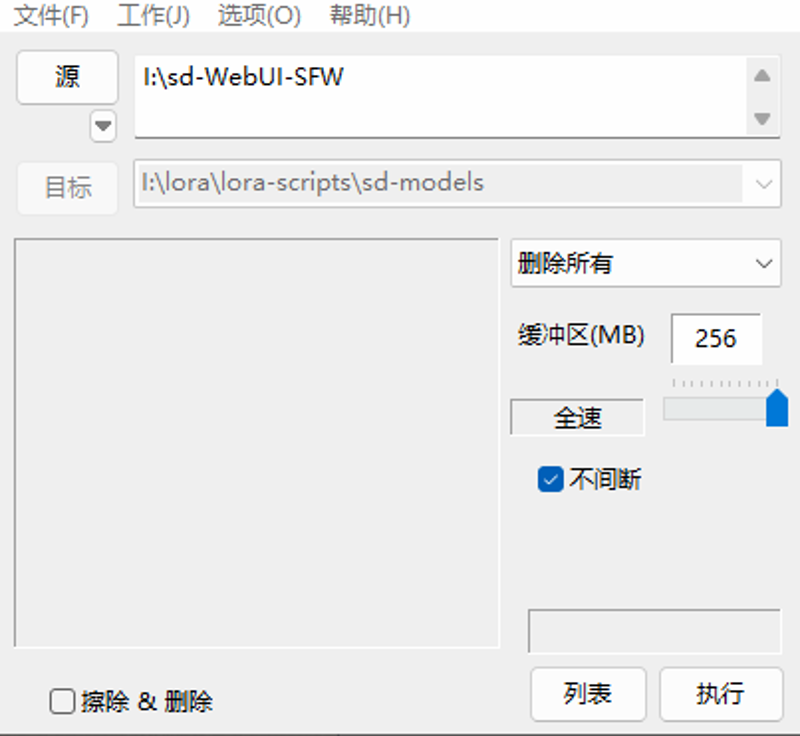
推荐三种方法:
①打开终端使用命令行删除
②使用FastCopy直接删除所有(注意不要点左下角的擦除&删除)
③如果你听了我的建议整个Webui相关的东西都放在了同一个盘符中,那么推荐使用快速格式化,这样删除是最快最方便的。
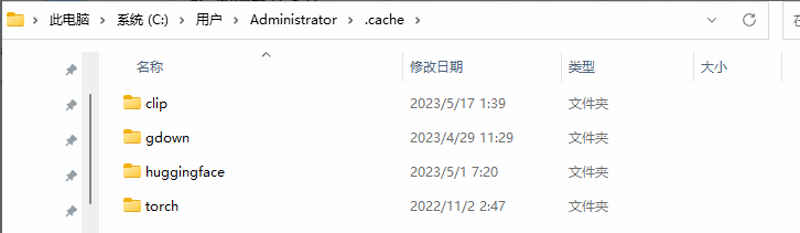
3. 删除缓存文件
①Webui缓存
C:\Users\你的用户名\.cache
这其中这4个文件夹是Stable Diffusion Webui所创建的缓存文件,只需要删除这四个文件夹就可以了,多出来的文件夹是你安装的许多其他的东西。
②pip下载缓存
C:\Users\用户名\AppData\Local\pip\cache
如果找不到AppData文件夹那么请修改文件夹选项:隐藏文件和文件夹-显示隐藏的文件、文件夹和驱动器。
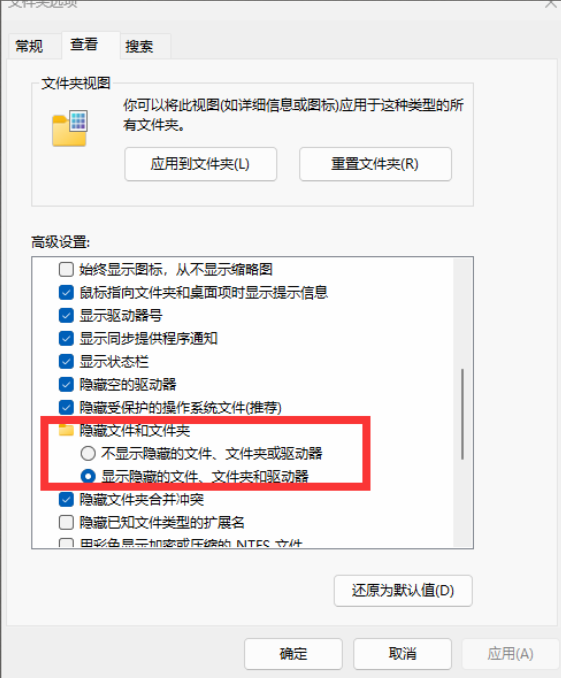
cache文件夹可以直接全部删除不会影响其他的东西

Stable diffusion相关词汇表
● artificial intelligence generated content (AIGC): 生成式人工智能
● ancestral sampling: 祖先采样,又称向前采样
● annotation: 标示
● batch count: 批量数量
● batch size: 批量大小
● checkpoint: 存盘点,模型格式,附文件名为.ckpt。
● classifier-free guidance scale (CFG scale): 事前训练的条件控制生成方法。
● CodeFormer: 2022年由Shangchen Zhou等人发表的脸部修复模型。
● conditioning:制约训练
● ControlNet: 2022年由Lvmin Zhang发表,通过加入额外条件来控制扩散模型的神经网络结构。
● cross-attention: 分散注意
● dataset: 数据集
● denoising: 去噪,降噪
● diffusion: 扩散
● Denoising Diffusion Implicit Models (DDIM): 去噪扩散隐式模型,2022年由Jiaming Song等人发表的采样方法。
● Dreambooth: Google Research和波士顿大学于2022年发表的深度学习模型,用于调整现有的文生图模型。
● embedding: 嵌入
● epoch: 时期
● Euler Ancestral (Euler a): 基于k-diffusion的采样方法,使用祖父采样与欧拉方法步数。可在20~30步数生出好结果。
● Euler: 基于k-diffusion的采样方法,使用欧拉方法步数。可在20~30步数生出好结果。
● fine-tune: 微调
● float16 (fp16): 半精度浮点数
● float32 (fp32): 单精度浮点数
● generate:生成图片
● Generative Adversarial Network (GAN):生成对抗网络,让两个神经网络相互博弈的方式进行学习的训练方法。
● GFPGAN: 腾讯于2021年发表的脸部修复模型。
● hypernetwork: 超网络
● image to image: 图生图
● inference: 模型推理
● inpaint: 内补绘制
● interrogator: 图像理解
● k-diffusion: Karras等人于2022年发表的PyTorch扩散模型,基于论文〈Elucidating the Design Space of Diffusion-Based Generative Models〉所实作。
● latent diffusion: 潜在扩散
● latent space: 潜在空间
● learning rate: 学习率
● Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion (LyCORIS)
● low-rank adaptation (LoRA): 低秩自适应,2023年由Microsoft发表,用于微调大模型的技术。
● machine learning: 机器学习
● model:模型
● negative prompts: 负向提示词
● outpaint: 外补绘制
● pickle: 保存张量的模型格式,附文件名为.pt
● postprocessing: 后处理
● precision: 精度
● preprocessing: 预处理
● prompts: 提示词
● PyTorch: 一款开源机器学习库
● safetensors: 由Huggingface研发,安全保存张量的模型格式。
● sampling method: 采样方法
● sampling steps: 采样步数
● scheduler: 调度器
● seed: 种子码
● Stable Diffusion: 稳定扩散,一个文生图模型,2022年由CompVis发表,由U-Net、VAE、Text Encoder三者组成。
● text encoder: 文本编码
● text to image: 文本生成图片,文生图
● textual inversion: 文本倒置
● tiling: 平铺
● token: 词元
● tokenizer: 标记解析器
● Transformers: HuggingFace研发的一系列API,用于辅助PyTorch、TensorFlow、JAX机器学习,可下载最新预训练的模型。
● U-Net:用于影像分割的卷积神经网络
● unified predictor-corrector (UniPC): 统一预测校正,2023年发表的新采样方法。
● upscale: 升频,放大
● variational auto encoder (VAE): 变分自动编码器
● weights: 权重
● xFormers: 2022年由Meta发表,用于加速Transformers,并减少VRAM占用的技术。