Introduction
AnimateDiff in ComfyUI is an amazing way to generate AI Videos. In this Guide I will try to help you with starting out using this and give you some starting workflows to work with. My attempt here is to try give you a setup that gives you a jumping off point to start making your own videos.
**WORKFLOWS ARE ATTACHED TO THIS POST TOP RIGHT CORNER TO DOWNLOAD UNDER ATTACHMENTS**
Change log:
March 26, 2024 - changed some of the file instructions due to comfy now having a default place for them
June 24, 2024 - Major rework - Updated all workflows to account for the new nodes. Changed general advice. There might be a bug or issue with something or the workflows so please leave a comment if there is an issue with the workflow or a poor explanation.
System Requirements
A Windows Computer with a NVIDIA Graphics card with at least 10GB of VRAM (You can do smaller resolutions (512x512 works with 2 ControlNets) or the Txt2VID workflows with a minimum of 8GB VRAM). Anything else I will try to point you in the right direction but will not be able to help you troubleshoot. Comfy has really improved the efficiency recently
Installing the Dependencies
These are things that you need in order to install and use ComfyUI.
GIT - https://git-scm.com/downloads - this lets you download the extensions from GitHub and update your nodes as updates get pushed.
(Optional) - https://ffmpeg.org/download.html - this is what combine nodes use to take the images and turn them in a gif. Installing is a guide in and of itself. I would YouTube how to install it to PATH. If you do not have this the node will give an error BUT the workflows still run and you will get the frames
7zip - https://7-zip.org/ - this is to extract the ComfyUI Standalone
Installing ComfyUI and Animation Nodes
Now let's Install ComfyUI and the nodes we need for Animate Diff!
Download ComfyUI either using this direct link: https://github.com/comfyanonymous/ComfyUI/releases/download/latest/ComfyUI_windows_portable_nvidia_cu118_or_cpu.7z or navigate on the webpage: https://github.com/comfyanonymous/ComfyUI (If you have a Mac or AMD GPU there is a more complex install guide there).
Extract with 7zip Installed above. Please note it does not need to be installed per se just extracted to a target folder.
Navigate to the custom nodes part of comfy

In the explorer tab (ie. the box pictured above) click select and type CMD and then hit enter, you are now should have a command prompt box open. IT should look like this:

You are going to type the following commands (you can copy/paste one at a time) - What we are doing here is using Git (installed above) to download the node repositories that we want (some can take a while):
git clone https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved
git clone https://github.com/Kosinkadink/ComfyUI-Advanced-ControlNet
For the ControlNet preprocessors you cannot simply download them you have to use the manager we installed above. You start by running "run_nvidia_gpu" in the ComfyUI_windows_portable folder. It will initialize some of the above nodes. Then you will hit the Manager button then "install custom nodes" then search for "Auxiliary Preprocessors" and install ComfyUI's ControlNet Auxiliary Preprocessors.
Similar to ControlNet preprocesors you need to search for "FizzNodes" and install them. This is what is used for prompt traveling in workflows 4/5. Then close the comfy UI window and command window and when you restart it will load them.
Similar to the above find "VideoHelperSuite" and install that - its what helps you load videos and images into the workflow.
Download checkpoint(s) and put them in the checkpoints folder. You can choose any model based on stable diffusion 1.5 to use. For my tutorial download: https://civitai.com/models/24779?modelVersionId=56071 also https://civitai.com/models/4384/dreamshaper. As an aside realistic/midreal models often struggle with animatediff for some reason, except Epic Realism Natural Sin seems to work particularly well and not be blurry. Put this in the checkpoints folder:

Download VAE to put in the VAE folder. For my tutorial download https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.ckpt. It is a good general VAE and VAE's do not make a huge difference overall.
Download motion modules (original ones are here: https://huggingface.co/guoyww/animatediff/tree/main). For my tutorial download the v3 motion module. As a note Motion models make a fairly big difference to things especially with any new motion that AnimateDiff Makes. v3 is the most recent version as of writing the guides - it is generally the best but there are definite differences and some times the others work well depending on use - people have even had fine tunes of motion modules (search this site or hugging face for them). Put it in the animate diff model folder:

Download Controlnets and put them in your controlnets folder. https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main . For my tutorials you need Lineart, Depth and OpenPose (download bot the pth and yaml files).

You should be all ready to start making your animations!
Making Videos with AnimateDiff
The basic workflows that I have are available for download in the top right of this article. The zip File contains a sample video. There are basically two ways of doing it. One which is just text2Vid - it is great but motion is not always what you want. and Vid2Vid which uses controlnet to extract some of the motion in the video to guide the transformation.
If you are doing Vid2Vid download the Video you wish to convert.
In the ComfyUI folder run "run_nvidia_gpu" if this is the first time then it may take a while to download an install a few things.
To load a workflow either click load or drag the workflow onto comfy (as an aside any picture will have the comfy workflow attached so you can drag any generated image into comfy and it will load the workflow that created it)
I will explain the workflows below, if you want to start with something I would start with the workflow labeled "1-Basic Vid2Vid 1 ControlNet". I will go through the nodes and what they mean.
Run! (this step takes a while because it is making all the frames of the animation at once)
Node Explanations
Some should be self explanatory, however I will make a note on most.
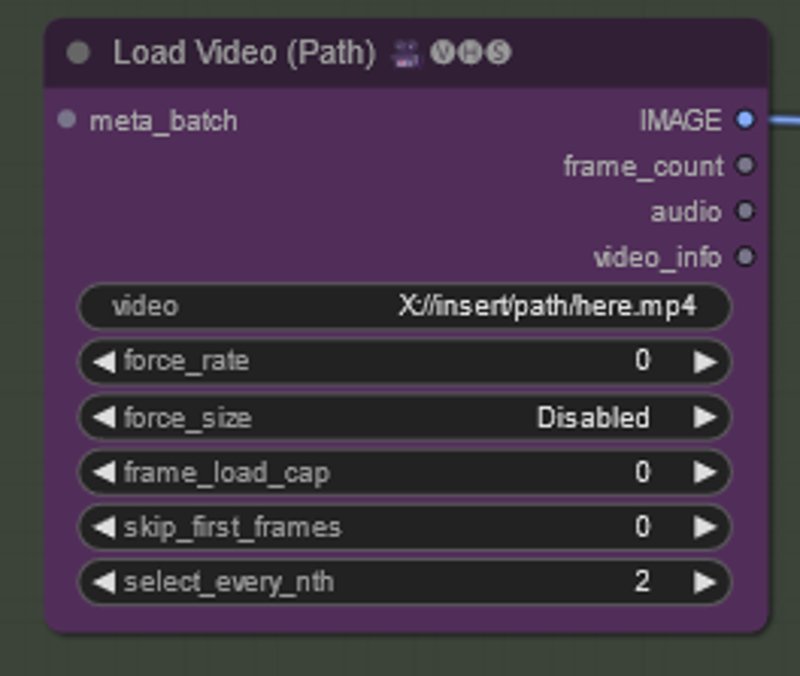
All you have do do is copy the location of the video you want to use. Easiest way is to navigate to the video right click and select "Copy as Path" you can paste it in the form labeled "video".
image_load_cap will load every frame if it is set to 0, otherwise it will load however many frames you choose which will determine the length of the animation
skip_first_images will allow you to skip so many frames at the beginning of a batch if you needed to
select_every_nth will take every frame at 1, ever other frame at 2, every 3rd frame at 3 and so on if you need it to skip some. I have set it currently to 2 - our original video is 24 fps and so we will be taking every other frame.
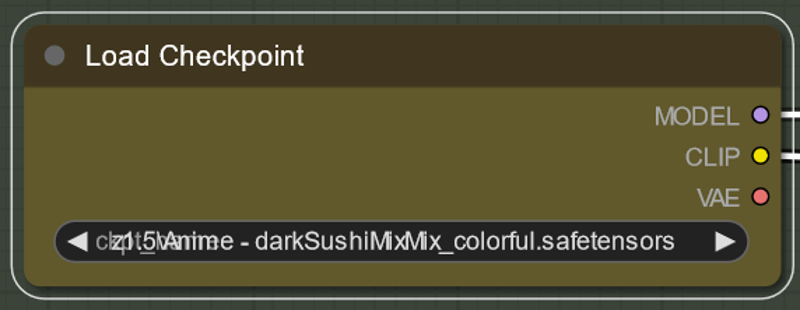
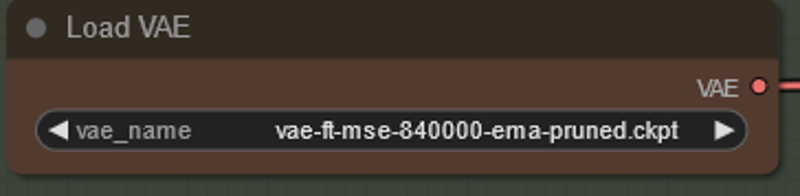
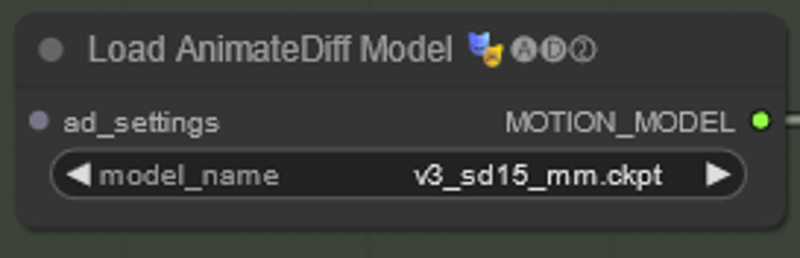
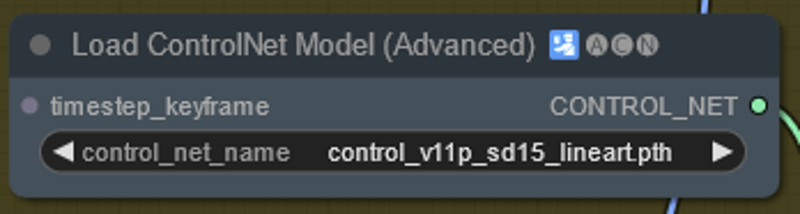
Each of the above nodes have a model associated with them. The names of the models you have and mine are likely not to be exactly the same in each example. You will need to click on each of the model names and select what you have instead. If there is nothing there then you have put the models in the wrong folder (see Installing ComfyUI above).
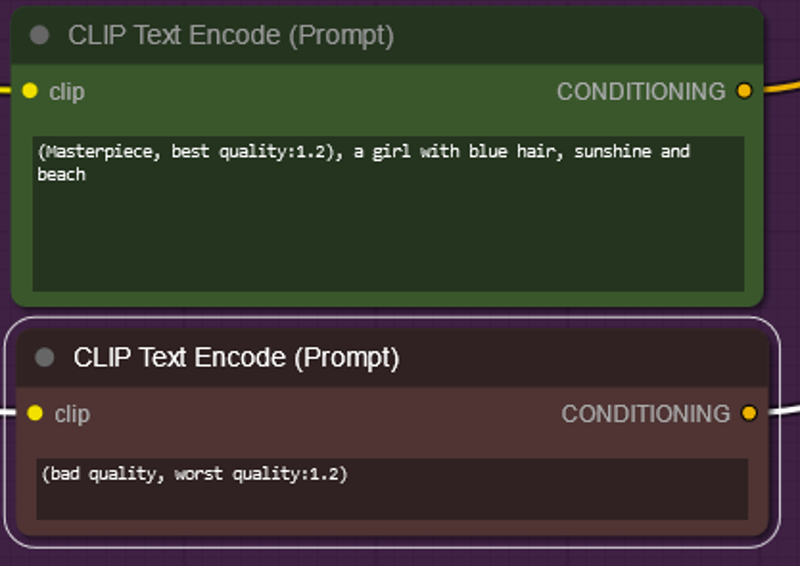
Green is your positive Prompt
Red is your negative Prompt
They are this color not because they are special but because they are set to be this color by right clicking them FYI.
It is worth noting that the motion module uses your prompt to help decide what motion to use, so if you use say walking it will try to make the character walk. If you say windy don't be surprised if things start moving more. There are some strange/unexpected results in the negative prompt so if you are copying a long negative prompt (or positive for that matter) if things look weird motion wise consider simplifying them.
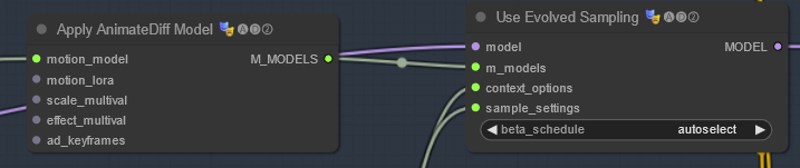
This is what turns on animatediff - context options and sample settings are described below. The other settings here are for advanced way of applying (or not) the motion module. Because the motion module is its own AI - it has its own scheduler - auto select will choose the scheduler that is intended for the motion module.
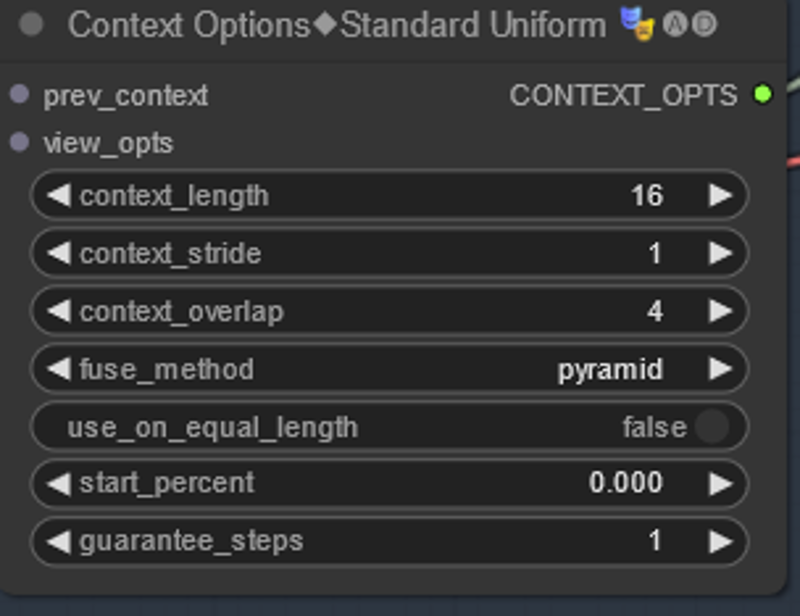
The uniform context options is what sets up unlimited context length. Without it animate diff is only able to do up to ~24 frames at once. The sweet spot is at about 16 frames. What it is doing is basically chaining and overlapping runs of AD together to smooth things out. The total length of the animation are determined by the number of frames the loader is fed in NOT context length. The loader figures out what to do based on the options which mean as follows. The defaults are what I used and are pretty good.
context length - this is the length of each run of animate diff. If you deviate too far from 16 your animation won't look good (is a limitation of animatediff can do). Default is good here for now
context overlap - is how much overlap each run of animate diff is overlapped with the next (ie. it is running frames 1-16 and then 12-28 with 4 frames overlapping to make things consistent)
context stride - this is harder to explain. At 1 it is off. These days this setting is not used much - if you want a good animated explanation please see the Animatediff Evolved readme. https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved
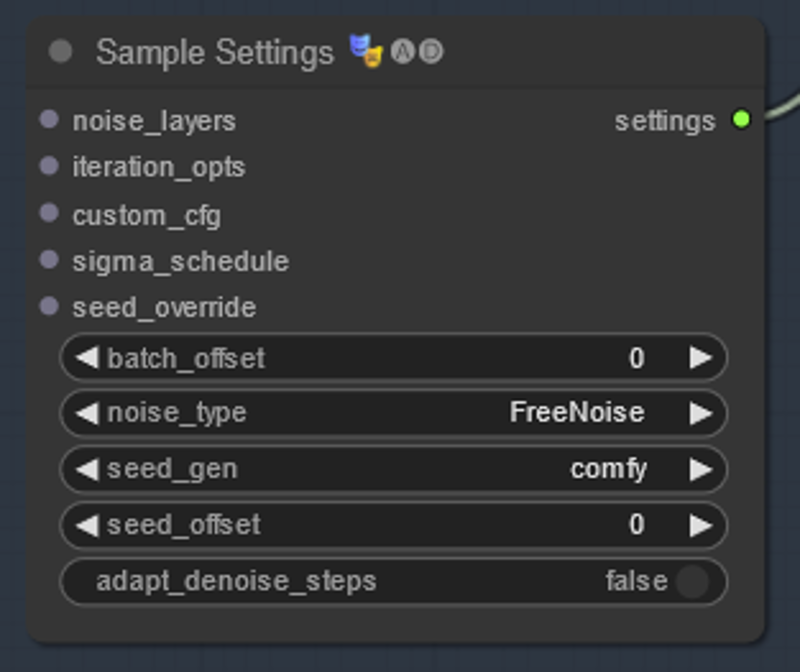
This tells animatediff what sort of noise to use - there has been some research in terms of what makes the 'best' noise - Freenoise is considered to be the general best as of this guide - but default will give more 'random' results if that is what you are aiming for.
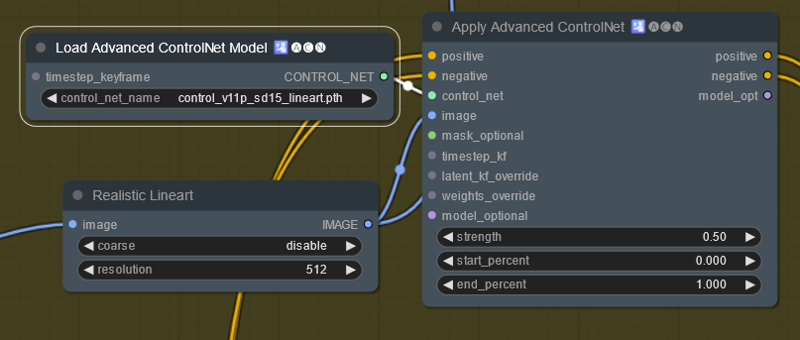
This is a basic controlnet setup. There is a preprocessor (bottom left). A controlnet and strength and start/end just like A1111. Of note the first time you use a preprocessor it has to download. This process can take quite some time depending on your internet connection.
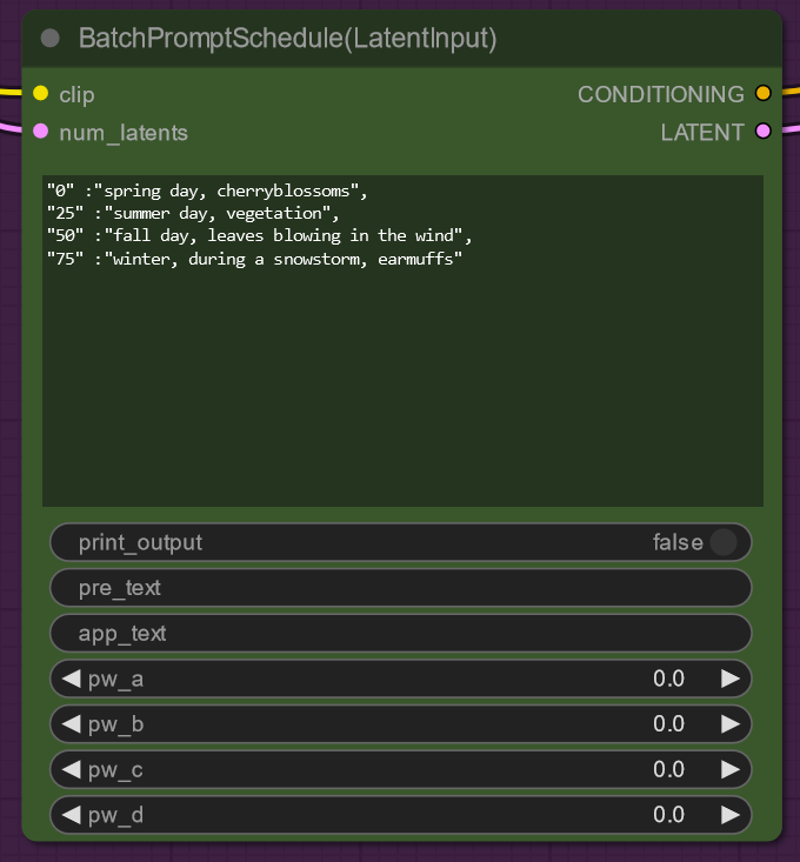
This is the the prompt Scheduler from FizzNodes.
pre_text - text to be put before the prompt (so you don't have to copy and paste a large prompt for each change)
app_text - text to be put after the prompt
The main text box works in the context "frame number": "prompt", (note the last prompt does not have a comma and will give you an error if you put one at the end of your list). It will blend between prompts so if you want to have it held I suggest you put it in twice, once where you want it to start and once where you want it to end.
(Please note that there is another version of this node which does not have latent input - if you are using this node please make sure max frames = max frames of your input animation otherwise this node does not work)
There is much more fancy stuff to do with this node (you can make an individual term change with time). Documentation of this is at https://github.com/FizzleDorf/ComfyUI_FizzNodes. This is what the pw... stuff is for.
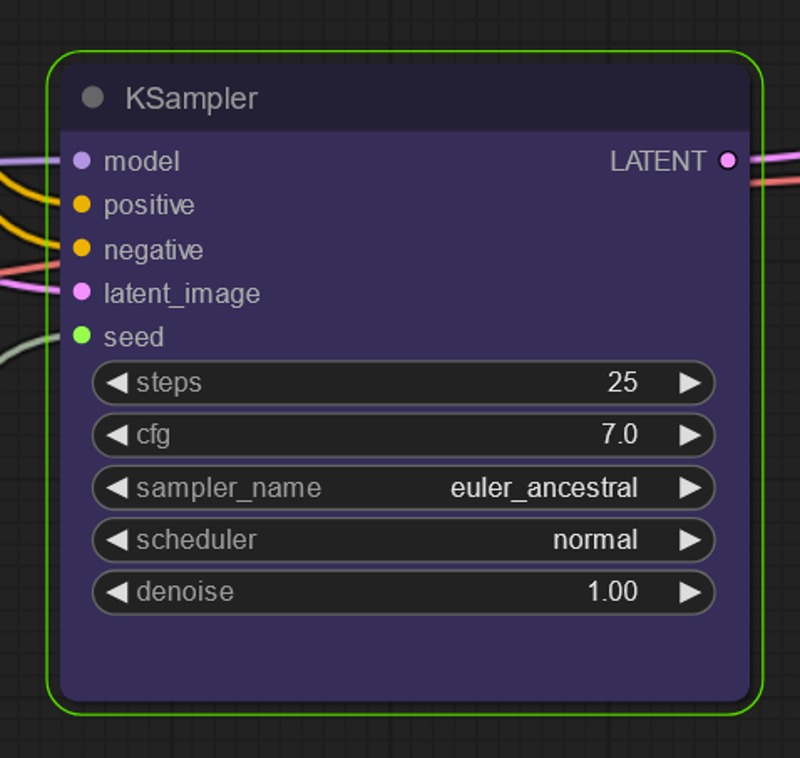
This is the KSampler - essentially this is stable diffusion now that we have loaded everything needed to make the animation.
Steps - These matter and you need more than 20. 25 is the minimum but people do see better results with going higher.
CFG - Feels free to increase this past you normally would for SD
Sampler - Samplers also matter Euler_a is good but Euler is bad at lower steps. Feel free to figure out a good setting for these
Denoise - Unless you are doing Vid2Vid keep this at one. If you are doing Vid2Vid you can reduce this to keep things closer to the original video
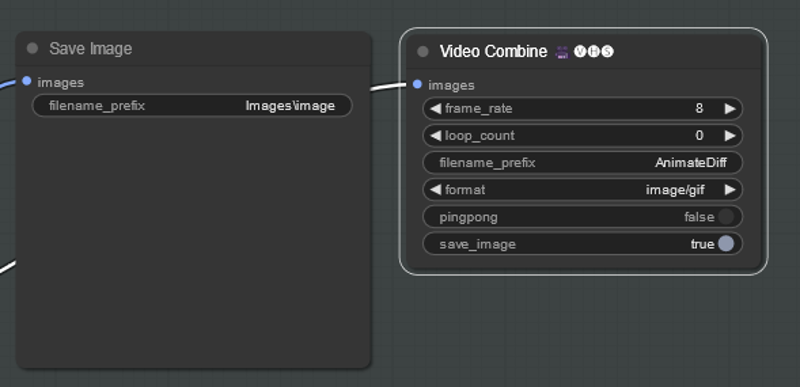
These are your output nodes and will end up in

If you see how I did the save image node it allows for you to save things into folders
For the Combine node it creates a gif by default. Do know that gifs look a lot worse than individual frames so even if the gif does not look great it might look great in a video.
frame_rate - frame rate of the gif
loop_count - number of loops to do before stopping. 0 is infinite looping
format - changes what to make gif/mp4 etc
pingpong - will make the video go through all the frames and then back instead of one way
save image - saves a frame of the video (because the video sometimes does not contain the metadata this is a way to save your workflow if you are not also saving the images - VHS tries to save the metadata of the video on the video itself).
Please note that in the example workflow using the example video we are loading every other frame of a 24 frame video and then turning that into at 8 fps animation (meaning things will be slowed compared to the original video)
Workflow Explanations
Basic Vid2Vid 1 ControlNet - This is the basic Vid2Vid workflow updated with the new nodes.
Vid2Vid Multi-ControlNet - This is basically the same as above but with 2 controlnets (different ones this time). I am giving this workflow because people were getting confused how to do multicontrolnet.
Basic Txt2Vid - this is a basic text to video - once you ensure your models are loaded you can just click prompt and it will work. Do note there is a number of frame primal node that replaces the load image node and no controlnets. Do know I don't do much txt2vid so this produces and acceptable output but nothing stellar.
Vid2Vid with Prompt Scheduling - this is basically Vid2Vid with a prompt scheduling node. This is what I used to make the video for Reddit. See above documentation of the new node.
Txt2Vid with Prompt Scheduling - Basic text2img with the new prompt scheduling nodes.
What Next?
Change the video input for vid2vid (obviously)! There are some new nodes that can separate video directly into frames. See Load video nodes - this node is relatively new.
Change around the parameters!!
The stable diffusion checkpoint and denoise strength on the KSampler make a lot of difference (for Vid2Vid).
You can add/remove control nets or change the strength of them. If you are used to doing other stable diffusion videos I find that you need much less ControlNet strength than with straight up SD and you will get more than just filter effects. I would also suggest trying openpose.
Try the advanced K sampler
Try to add loras
Try Motion loras: https://civitai.com/models/153022?modelVersionId=171354
Use a 2nd ksampler to hires fix (some further good examples can be found on the Kosinkadink's animatediff GitHub https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved).
Use masking or regional prompting.
With these basic workflows adding what you want should be as simple as adding or removing a few nodes. I wish you luck!
Troubleshooting
As things get further developed this guide is likely to slowly go out of date and some of the nodes may be depreciated. That does not mean that they won't necessarily work. Hopefully I will have the time to make another guide or somebody else will.
If you are getting Null type errors make sure you have a model loaded in each location noted above.
If you already use ComfyUI for other things there are several node repos that conflict with the animation ones and can cause errors.
If you are having tensor mismatch errors or issues with duplicate frames this is because the VHS loader node "uploads" the images into the input portion of ComfyUI.

Navigate to this folder and you can delete the folders and reset things.
In Closing
I hope you enjoyed this tutorial. If you did enjoy it please consider subscribing to my YouTube channel (https://www.youtube.com/@Inner-Reflections-AI) or my Instagram/Tiktok (https://linktr.ee/Inner_Reflections )
If you are a commercial entity and want some presets that might work for different style transformations feel free to contact me on Instagram or Twitter.
If you are would like to collab on something or have questions I am happy to be connect on Instagram or Twitter.
If you’re going deep into Animatediff, you’re welcome to join this Discord for people who are building workflows, tinkering with the models, creating art, etc.
(If you go to the discord seeking tech support please find the adsupport channel and use that so that discussion is in the right place)