


I've just spent some time messing around with SDXL turbo, and here are my thoughts on it.
Just to preface everything I'm about to say, this is very new, there's little tooling that's made specifically for this model, and there are no custom checkpoints to get better quality out of it.
The attachments include a very basic workflow using the model, for basic text to image generation. Of course, it requires the model.
Setting up
The model can be grabbed from here: https://huggingface.co/stabilityai/sdxl-turbo
Clone the repo, grab the sd_xl_turbo_1.0_fp16.safetensors file from it (or the one at full precision, but there's no reason, and it will be just slower). Drop it into your models/checkpoints directory, and restart comfy. Make sure it's up to date, as there are some new nodes related to properly using turbo in the intended way. Given you have the model installed, and comfy up to date, my workflow should generate an image quickly (once the model loads in, which is WAY slower than the image generation itself).
What works
Image generation, controlnets (ones targeting SDXL 1.0), samplers not meant for SDXL turbo.
SDXL LoRAs, provided a decent custom checkpoint.
Certain img2img workflows work, for example detailers:
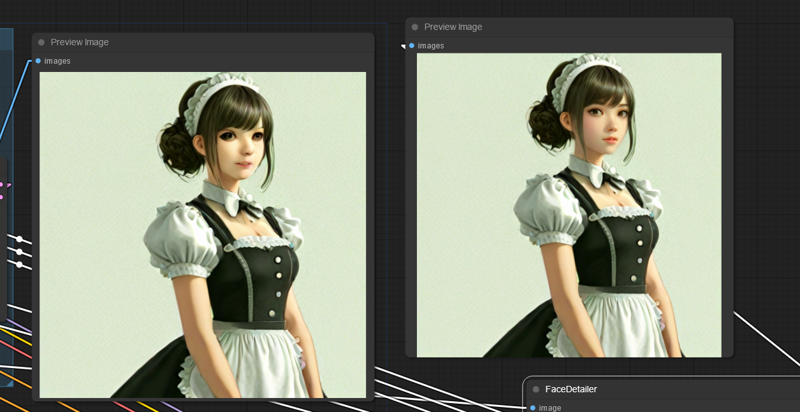
(Left is raw image, right is image with a face detailer).
General img2img detailing and inpainting seems to work, but isn't super reliable (I'd say slightly worse than my experience with SDXL):

IPAdapter seems to work as well, provided you use a setup intended for SDXL:

What doesn't work
SDXL LoRAs (they don't seem to crash it though, which is surprisng) with the base model.
SDXL image sizes (dimensions of 512 and 768 pixels work, 512 is best, going above causes multiple objects to get generated and merged together like with old stable diffusion, see below for an example):

Using CFG values in ranges normal for SDXL doesn't work either, try to stay around 1.0, very low values like 0.1 can cause things like NSFW output despite prompting against it, and going higher causes noisy images with high contrast that stop being coherent quite quickly, even 1.2 will mess them up bad.
Since this model is intended to work in tiny amount of steps (usually 1 to 10 with 1 step being common), prompting techniques that change conditioning or remove it during image creation might not work as intended.
Recommendations
If you aren't using something similar (with the SDXL turbo base model) to the workflow provided (for example, detailer nodes), use the following values as reference:
CFG: 0.6 - 1.0
Scheduler:
euler_ancestralSteps: 1 - 10, going above 4 or 5 is pointless and can significantly degrade quality
Wrapping up
So far, it's hard to tell what people will do with this model. Since it's just a base model provided by StabilityAI, it doesn't output high quality images, and struggles with a bunch of things. It's really bad at anime styles, anatomy tends to be bad, and eyes and faces come out very poor. If people decide to make custom checkpoints and/or LoRAs (if they're even applicable), this might change, and the model might end up having targeted checkpoints that could remove some of these limitations.
The model is REALLY fast, I can generate a single image with 1 iteration, 512x512 in about 0.2-0.4 seconds on a 4090 (will probably get faster given optimized setups, or something like TensorRT in the future), but the results are pretty bad, about on par with base SD 1.5, or even old Craiyon models, especially when it comes to faces and anatomy. It's quite good at detailed textures such as fur, text is working about on par with base SDXL, that is, it can generate something resembling text and sometimes even spell it sort of properly, but it has that simple AI model text quality to it:


So far, I think this sort of model will have very limited use cases, where quality doesn't matter, but generating images fast does. For example, having a real-time-ish way of exploring prompts, a novelty AI image "search engine" with fast previews, or maybe generating animations if quality doesn't matter.
Edit: The first batch of models seems to show that the quality gap might close quickly, but I wouldn't ditch SDXL tooling just yet, especially when it comes to faces.
Outside of that, I think the best this can be used for is generating and detailing small parts of an image that might for example get blurred in post, like backgrounds and possibly characters in them, or generating an image that then gets upscaled and fleshed out by another model, in a way similar to the idea from my previous article. This way, it might be easier to spend some time refining the prompt and mining for the best seed to get the desired composition.
Edit: Added a kitchen sink example workflow with multiple detailers, LoRA, controlnet, IPAdapter, model upscale.