
This article is oversimplified. If you want to know more, please visit my Github page. Links in the bottom session. My Github is updated daily.
Changelog:
v15: Revise "isotropic merge" (chapter 15) as "ISO-Z".
v14.1: Revised chapter 14.
v14: Added "215cR-Evo" (chapter 14), "isotropic merge" (chapter 15), and removed the entire first half of diagrams. Meanwhile there are more developements but I decided to seperate.
v13: Added "Karmix" (chapter 13), a model created by someone else, but worth mentioning.
v12: Added "255c" (chapter 12), which is scale up of 215c. Should be final version.
v11: Added "215c" (chapter 11), which is DGMLA-216 + Git Rebasin.
v10: SD3.5 is out! Make sure you manually update the libraries.
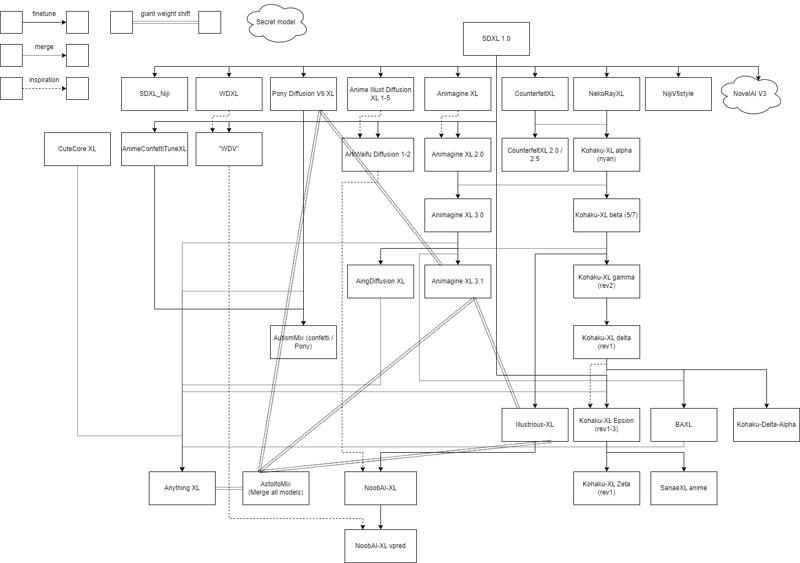
v9.01: I updated my "model history" to become a bit more accurate (anime models only).
v9: Added DGMLA-216 (chapter 10). BTW finally there are related works (and this in HF).
v8.02: Model comparasion table updated. Used multiple approaches for counting parameters.
v8.01: I found that my "model history" is interesting so I add it (in Chapter 0).
v8: Added TGMD-192 (chapter 9).
v7.1: Add AuraFlow and Hunyuan-DiT. Also made a tiny comparasion.
v7: Added Flux MBW diagram! Direct intercepting "latent" from diffuser source code. My source code. Yo 57 MBW layers!?
v6.95: Edited the L2 chart in Chapter 8 for concept illustration.
v6.9420: Thanks mcmonkey now I can make the diagram of SD3. Spoiler: No more UNET!
v6.10086: UwU SD3 merger is out! (no models to merge yet) And there are 24 MBW layers for the mmDiT! (no more UNET) Waiting Diffuser support for visualization. Or I use this instead?
v6.1: Replace the L2 distance diagram with full blown 118 models.
v6: Added TGMD (chapter 8 and chapter 0).
v5: Added TSD (chapter 7).
v4: Added TIES-SOUP (chapter 5), Git Rebasin (chapter 6). Meanwhile put it to new category "ML research".
v3: Added SDXL content (chapter 4), marked as v3 because engineering advancement still counts.
v2: Added SD2 content (chapter 0), and a few wiki links.
v1: Initial content (SD1)
Exotic merging methods
Full article in my Github article "AstolfoMix", and "AstolfoMix-SD2". I am not an AI professional, please always seek for processional advice. I will go ranting.
0. "All models are wrong, but some are useful"
Featured in AstolfoMix-SD2.
This is "point 0" because it is not related to merge, but it is critical for merging models.
From the history of SD2, it is a disaster. Since WD1.4 and 1.5, until ReplicantV3, I suspect malfunction of both trainer and runtime, along with wrong configuration on the trainer (and slightly controversial tagging approach), making most models of the era is unuseable.
However, with a core discovery of "Replicant-V3 UNET + WD1.5B3 CLIP", as the result of tedious process of model selection, I quickly "test" all discovered models with seperated UNETs and CLIPs under controlled naive "uniform mix" of other components. After a few pass of storage consuming model sets with pattern recognition, finally I shortlisted 12 UNETs with 4 CLIPs, under total of 15 models, in a set of 24 discovered models.
The high diversity of model weights, including both nice and broken weights, merging them may yield glitched imges and even break the merger.

For SD1, it is a lot better. Just keep reset the CLIP to SD's original CLIP, and choose UNETs freely. If you need "trigger words", use LoRA instead. If you doubt why use SD's CLIP, because NAI use SD's VAE and CLIP also. Use this toolkit to replace.
0. "Just buy the haystack"
Applied since AstolfoMix-XL (TIES-SOUP).
This is also a "point 0", but different from my old filtering streadgy.
Thanks for the advancement of merging alforithm, we can finally accepts all model without worring the model weights contradicting together. The only requirement is making sure the valueable weights are the majority of the model set.
TIES did this by voting on sign movement, and Geometric Median, is a famous 51% attack solver.
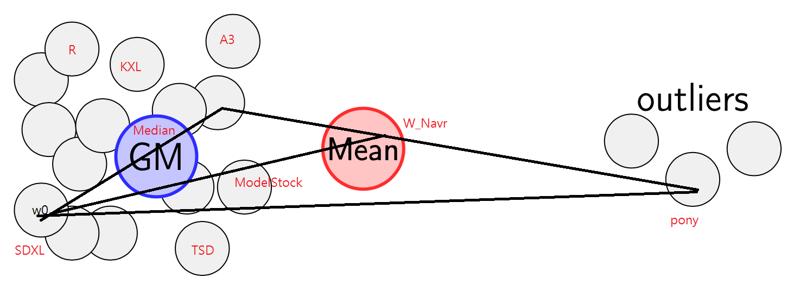
You will see clearly Pony variants are spread in a corner, Kohaku D / E series are spread in other corners, and others are stay in a very dense cluster (my mixes are not included).
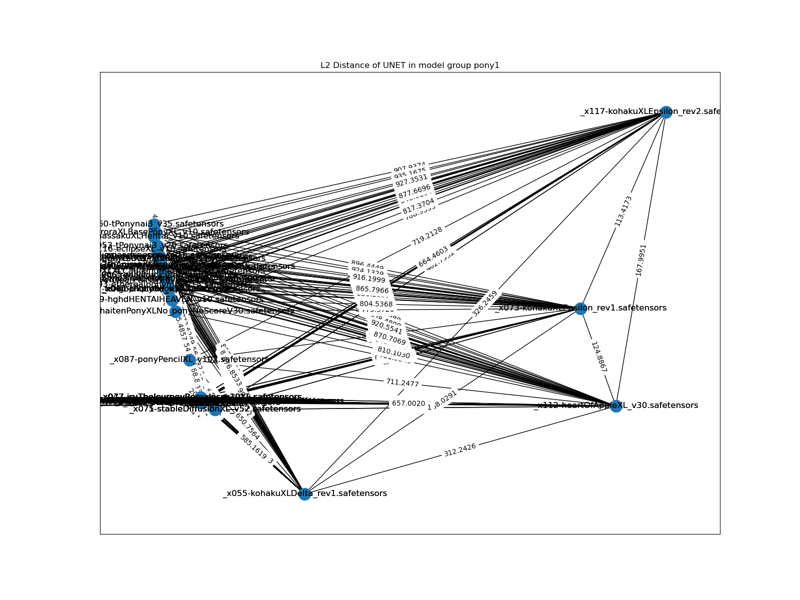
Here is a model tree based from published content. "Anime models only".
1. Uniform SOUP / Isotropic Merge
Applied to AstolfoMix (Extended).
It is just Ensemble averaging from 1990s, proposed by Polyak. As simple as its definition. No hyperparameters needed.
Terms "Uniform soup" comes from Model Soup, meanwhile "Isotropic Merge" comes from Fisher Merge.
You can either merge with math series (1/x for x > 2, change ui-config.json for better precision):
"modelmerger/Multiplier (M) - set to 0 to get model A/step": 0.0001,Or use parallel mege with weight = 0.5 throughout the process.
To make noiticeable difference in performance with stable visual style, I found that it takes around 6 models to stable, but somehow I found 20 models which can generate 1024x1024 images.
You can merge ALL the LoRAs in the Internet to hope a tiny SD1 can beat SDXL with this approach, but I don't have time to do so.
2. Bayesian merge / AutoMBW / RL
Applied to AstolfoMix (Reinforced).
All 3 concepts are related. Full article available.
Bayesian Optimization over MBW (a framework) as a variant of Reinformcement Learning (or more precise, multi-armed bandit). Bought to SD by s1dx. Somehow archieved by me with AutoMBW. S1dx use Chad score for reward, but I use ImageReward because it is more convincing. AutoMBW also support other reward model and optimization algorithms (and some fancy feature which are untested), but they are yet to be proven. However S1dx supports "Add diff", but my extension dosen't.
To perform RL, we make payloads (prompts / parameters / settings you think worth to learn), choose a reward model, and leave your GPU burning. It will output the "best merging receipe".
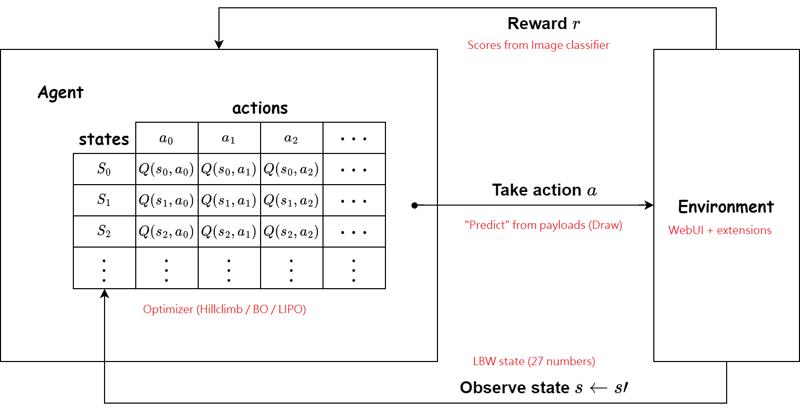
(Explaination is omitted) RL doesn't need dataset (and tedious preparation / preprocessing), and it is easier to archive along with multiple black box as environment. However the design of payloads is important, and it does overfit to payload and damage diversity. As discussed in recent LLMs, alignment between Reward models and human evalulations are also important. We shuold study carefully how such reward model (aesthetic score predictor in this example) is produced, and determine if such model is useful and correlate to the objective we want to archive.
Usually it don't need 256 H100 to do so, but it may takes a lot of time, with up to 120 iterations to archive early stopping, and the process is hard to be parallel. It took 3 weeks to train for my model, using 2x RTX 3090.
Parallel mege is expected, and all 20 models must be merged for desired effect. Feature selection occurs in an unpredictable mannar, and without obvious preservation. There is no "performance preview" until the very last merge. However with long runs, it tends to be "uniform merge" with optimized "direction", because the weight initialization is pure random by refault.
The reason it works (without either traditional finetuning or inventred "MBW theories") is simple: Feature extraction with 27 parameters in somewhat useful areas are already effective.
3. Special case of "Add difference"
Applied to AstolfoMix (21b).
This is the hardest part to understand. For "add difference", we can take the special case "b-c=a+1" to make "one more thing". Notation "a" is easy to understand: They come from same set of 20 models. and for the notation "1", it is the "adjusted direction".
This diagram may make it easier to understand:

It does preserve most of the "good features" and further "adjusted to the best direction" a.k.a balance of all 20 models. Such balance may show its strength in extreme conditions, such as DDIM 500 STEP with CFG=1 with absolutely no prompts. However this is a bit far from academic.


Here are the Github articles in my repo:
https://github.com/6DammK9/nai-anime-pure-negative-prompt/blob/main/ch01/autombw.md
https://github.com/6DammK9/nai-anime-pure-negative-prompt/tree/main/ch03
FULL receipes are included (a lot, talking about 20 models):
https://github.com/6DammK9/nai-anime-pure-negative-prompt/tree/main/ch05
4. "E2E" merge procedure with FP64 precision
Applied to AstolfoMix-XL (Extended-FP64)
When the model pool is being really large (say 70), merging them by hand will be impossible, meanwhile casting model weights to FP16 multiple times will propogate the precision error, and managing recipe will be hard, therefore a dedicated merger is used to automate the process. All merges are done in memory with FP64 precision therefore such error can be prevented.
Such merge still used hours to obtain, and it will be days if it is done by hand. Also, the elimination of "precision error" is visiable in resulting image, and it can be propogated to a distinct image.

5. TIES merge and "TIES-SOUP" merge
Applied to AstolfoMix-XL (TIES-SOUP)
Don't be afraid of a paper reaching academic conference ("above arxiv"), I'll keep it in short: "Model parameters votes for their math sign to reduce noise".
My "TIES-SOUP" version is made because 50% by accident (it works), and 50% that the correct TIES implementation actually doesn't work, and I need to get it theorized again.

It successfully "dissolved" the poor Pony into the model soup, but it will forget half of random details (and most of the quality tags yay), and made "Untitled" art finally possible (theory is present but the prediction was too noisy). Also, I have found that it is no more associative, where covariance exists, so no model filtering has the best performance (which I did in previous merge).
If you found that you RAM is not large enough to handle many SDXL models (310GB for 73 SDXL models), build a proper workstation or just choose what you belief worth to merge (should be 0.8x of all model size).
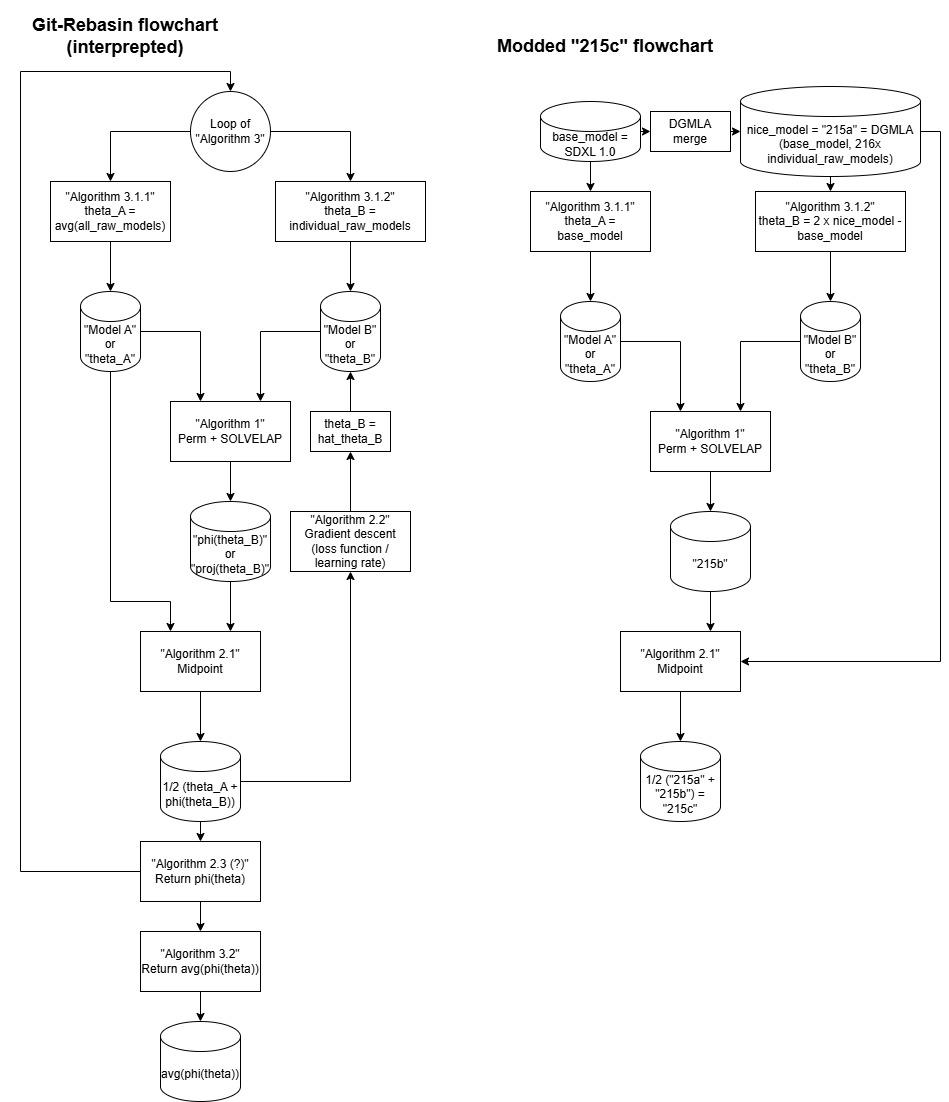
6. Git Re-Basin: Is a merge
(No model published here, see HF) See Chapter 11.
Referring this paper. The algorithm is too complicated to post here, and I found that there was only one correct implementation in the wild (better than nothing haha), and spent 4 hours to merge a pair of SDXL model. It is infeasible to find an algorithm requires evalulation of the model (a.k.a. T2I) or solving optimization problems in place. It was designed for VGG which is simple in structure, it may not work for SD / LLM which is complicated (parameter count with many components).

See Chapter 10 for more comparasion. It changed the orientation like Chapter 3, meanwhile the model weight is close to idential with comparasion with many other models (kind of dimension reduction, visually). 215a and 215b are almost in the same spot, but giving entirely different image.
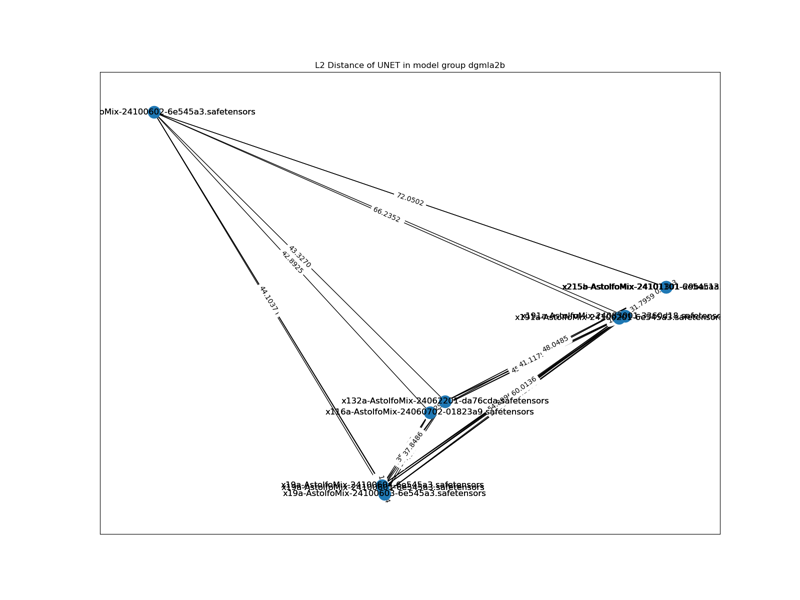
7. DARE merge and "TSD" merge
Applied to AstolfoMix-XL (TSD)
Don't be afraid of another paper reaching academic conference ("above arxiv"), I'll keep it in short: "Dropout And REscale". Dropout is a common technique while trainine neural networks. Picking the nerurons to disable is by pure random without looking for any meanings.
My "TSD" version is made because 50% by accident (it works again), and 50% that the correct TIES implementation actually doesn't work, and I need to get it theorized again.
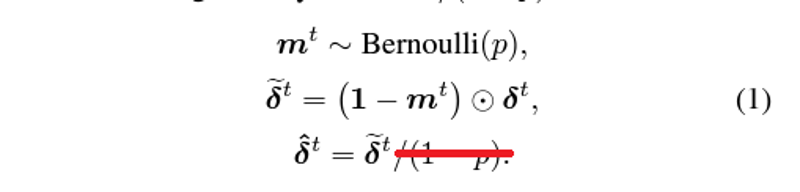
The effect is similar to TIES-SOUP, because it is just an additive above algorithm. It takes 450GB for 102 SDXL models with limited threads (merge 16/2515 layers at a time). BTW, 10% droupout rate is preferred, paper's 90% are just showing the properties in GPT instead of SD.

Also, since randomness is introduced, changing seed also changes the final result (hint: livery).

8. Model Stock and "TGMD" merge
Applied to AstolfoMix-XL (TGMD).
Yes, I read the paper. No, I'm confused. I know it is trying to find a center, but cosine similarity (for 2 vectors) just doesn't comply with 100 SDXL models. Even the paper doesn't clearly state what kind of "center" it is. Averaging is already finding the centroid of the models i.e. a kind of center. So what I can think of is a kind of median... Maybe geometric median.
As soon as trying the GM against mean / centroid (a.k.a. average), I found that it is effective. Then plugging it into current DARE / TIES stack, yes it works. Here is the current modification.

(This may be inaccurate) This is the concept illustration on how and why it works:

You can read Chapter 0 for why GM works. Since SD3 is releasing on June 12, I want to rush before I have absolutely no chance to be noticed, even I don't think there will be another 100 SD3 models for me to merge.

9. Scaling up the "TGMD" Merge
Applied to AstolfoMix-XL (TGMD-192).
Given that I'm picking the "median-ish" (Fermat point) instead of the "mean" (Mid point) with quite extensive of weight filtering, the "117 model" version sounds not rich enough, with many picked weights are "not stylish". Given the OP hardware I've owned, maybe I can scale up the merge to 192 models and see what it happens.
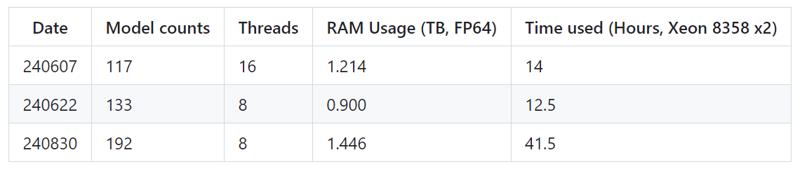
After including 50 more Pony models, 10 more ohaku XL models, and 40 more realistic models (they overlap with Pony with obvious reason), would I see the Pony content?
... Yes?
+ twilight_sparkle, masterpiece, score_9, score_8_up, score_7_up best quality
... No? Not just Astolfo, "action scenes" are missing also!
+ astolfo, best, absurdres, score_9
- worst, bad
Also, as a base model, would it be another great model after finetune, just like SD1.5 era? Would there be another 100 models for Flux / any future architecture? Or any new algorithms (DELLA / OFT / SVD) that seems legit to me? I don't know. No one knows.
10. "DGMLA" Merge and Parameter selection
Mini Rant
Making stuffs consistant is hard, especially in this "artistic domain". LLM Community may find merging fufill a niche as an academic topic lacked in discussion, meanwhile gathered MANY forgotten ideas which has potential with the new environment, SD community especially anime sector was still suffering PTSD in SD1 era, \*Cough \*Cough and found that it never fufill their precise expectation which is another niche (hence the approach in sophisticated finetuning). \*Cough \*Cough \*Cough Therefore it is challenging for me to keep myself against the trend with my hybird "hobby / academic" research under tight resource (majorly in time / human) as a kind of "amateur art". Thank you for the interest on this topic.
Applied to AstolfoMix-XL (DGMLA-216).
This is modified from DELLA Merge, which is also on top of my previous versions. Detailed explanantion in Github. Notice that the result model weights is closer to the base model (original SDXL) instead of a mixutre of finetune models. Precise content (e.g. particular character and artist style) comes with price. Fintuning will eventually forget pretrained data and decrease the variety of the image (as prediction), and even make the whole model instable to use for general (trigger word effect). Merging in this level is more like doing the opposite: Regain the balance between pretrained content and finetuned content, and make it "perform generally well". You will fine that it tried to draw things, but the details is never complete. It acts like "high precision low recall".
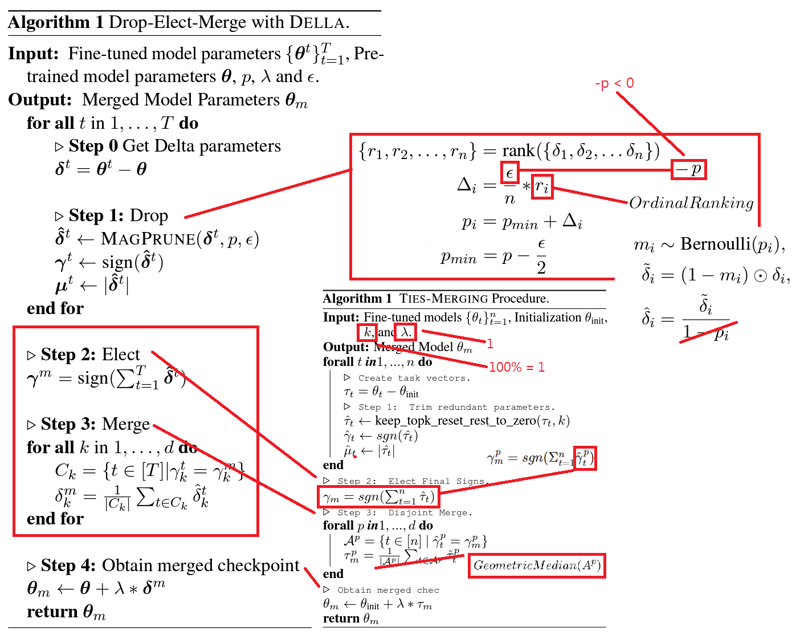
Since the model pool is larger, and the "ranking" takes more time to merge (in magnitue), I need to make some "small merges" to project the actual "large merge". Since the model pool is unfiltered (Ch.0) and order by chronological order, picking a simple random sample should able to represent the whole dataset. And it did. Currently my agressive approcah is still having minimal parameters with p=0.1 and keeping others linked to other variables or common constants.
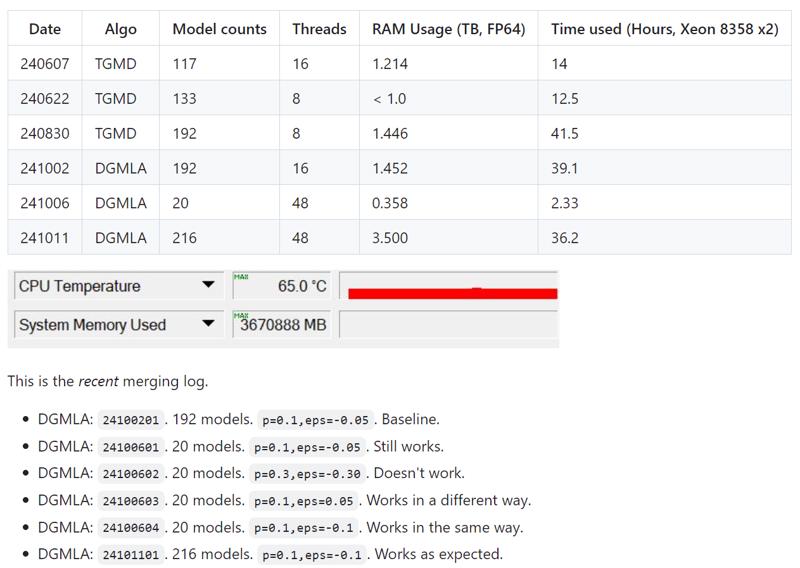
Meanwhile I have explored the Rebasin (Ch. 6) again, and the change of content is not meeting my expectation.
Also it is experiencing diminishing return because of the big model pool and slight change of algorithms. I need to swap image previews to observe the difference, meanwhile enhancement of "image quality" is less desireable of the "image content" from the previous versions.
This comparasion is "TGMD-192 > DGMLA-192 > 4 samples > DMGLA-216 > amp > basin"

11. Special case "Permutation from the Fermat Point"
Applied to AstolfoMix-XL (215c).
It is based from Chapter 10 and Chapter 6. I am busy because of lots of incidents and issues, so this may be a bit "too simple" yet "too hard to understand".

Revisiting the Git Rebasin paper, puzzling that why I cannot get satisfied result between base model and the merged model, I have found that I have overlooked a step in Algorithm 2, which I thought it is infesible to implement. There is an initial step: Make the midpoint after Algorithm 1.
Besides that, using the code in Chapter 2 is possible to make some "backward pass" as integration between trainers and mergers, but I'm lack of training target i.e. prompts that yield nice images).
Therefore, considering I may already made my merge fufilling some mathmatical properties, I can have a try with the illustrated flowchart:
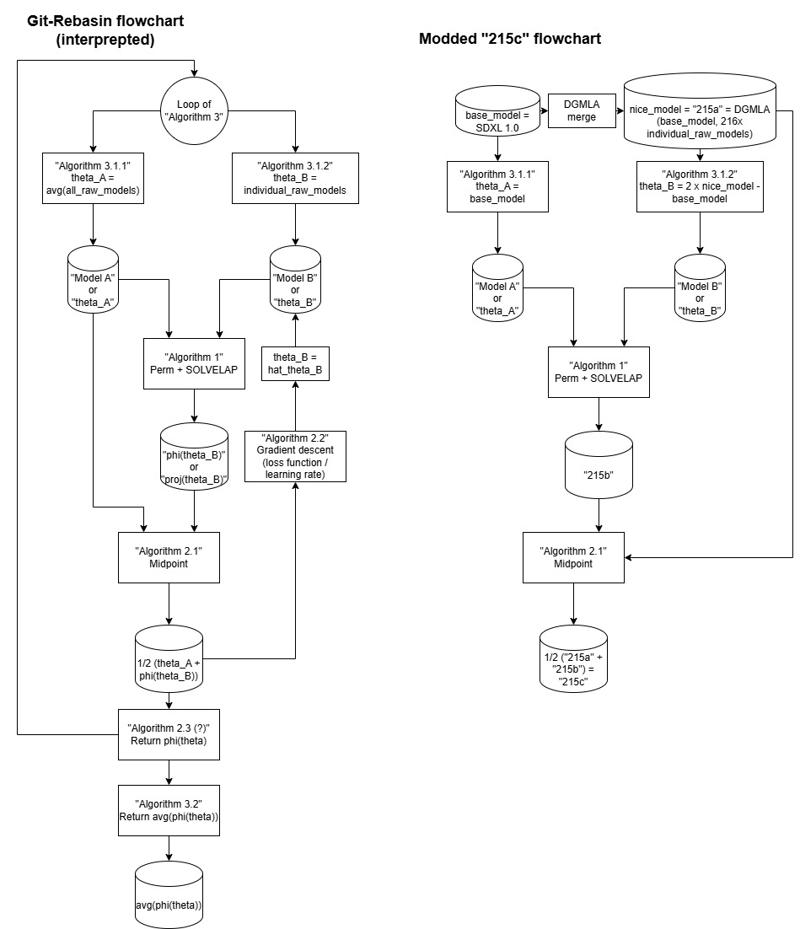
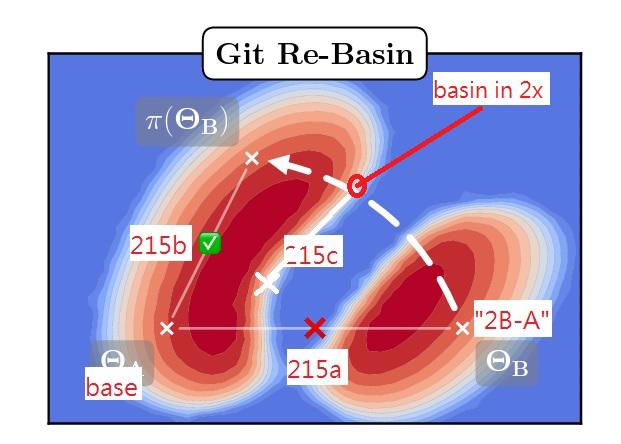
Which "215a" as Chapter 10, "215b" as Chapter 6, and the "215c" as the midpoint of them. Suprisingly the anatomy is way more normalized (realistic), yet it can sometimes show multiple styles within an image.

Revisitng the "gradient" image from the paper, even with the enlarged gradient (background is not in scale!), my "215c" may just able to stay in the "cliff" of the gradient, or even the critical point (as the hypothesis in nerual science, see this video), empowering the model to decide when to follow the prompt (c) and when to follow its own judgement (uc). Sadly this is no longer a (training) target, more like creation in the extreme.
12. Scale up and hitting wall (finally)
Applied to AstolfoMix-XL (255c).
I don't know why the entire section is disappeared, and there was no backup for this article (just picked from my Github article), so this will be shorter than expected.
It suffered from gradient vanishing problem. Meanwhile, with an multiple discovery which linked to RCM, I think there is no more algorithms to be discovered in short period of time. For example, "distillation as merging" requires as many GPU powers as finetuning, it just doesn't require full image / caption dataset. The benefit is not great enough for me to explore further.

13. Parallel Universe: Karcher merge with PCA
Applied to Karmix PCA TV.
Instead of describing again, I leave the screenshot directly from the PR post. Karcher merge is Geometric Median with Riemannian manifold instead of Euclidean Space. Does ML latent space a Borel space? Does latent space relates to either Euclidean Geometry or Rimeannian manifold? It is a open question right now. However I prefer not applying trigonometry functions inside the alogrithms because it will be very slow.

Meanwhile the "PCA" part, it is similar to SVD, which they are usually applied for the same task. It is related to KNOTS Merge, which is merging in a LoRA-ish way, and the most importantly, PCA can be used for image reconstruction, which is a kind of "denoising" when applying to model weights.
Finally, by applying a themed model pool (IL / NB variants instead of entire 256 models), it works distinctly better than usual anime merges.

Well... spoiler alert: I have merged successfully. However this time I need to make decision, and the image below, direct (A+B)/2 will fail.

13.5. Prophecy on training over a merged model?
Applied to AstolfoXL (1EP) and 9527 Detail Realistic XL.
From the HF incident in 2411, I planned to finetune from this model. After months of preparing, and the "wall" in 255c, this will conclude my experience in merging models turns out there are a lot more. Astolfo will be a boy soon has many fur now. Meanwhile, just after I complete the training and release the model, I see this paper. Yep, I knew it.

14. Merging the (pre)trained model again
Applied to AstolfoMix-XL (215R-Evo).
There is no algorithm: Just repeat the Basin Averaging (Chapter 11) over a simple (0.5 215c + 0.5 1EP) merge. However I spotted great improvement on prompt understanding. Probably it is because my LR on TE is 8x higher than UNET.
The "215cEvo" without "R" was the model without the "9527R" content. I used that for control test. It just replace 215c with "0.5 215c + 0.5 9527 R", which "9527R" is just a trained and merged LoRA over 215c.
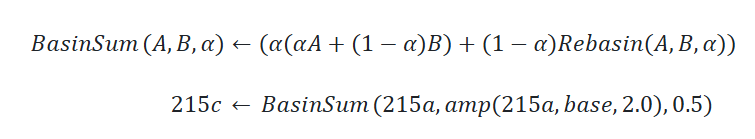
At that moment, I thought that it was the end of the project. I was out of idea.

15. Isotropic Merge: SVD Post process?
Applied to AstolfoKarmix-XL (NoobAI Based V1.1) and AstolfoMix-XL (DGMIZ-AK7c).
From this paper. The merge suffers from failed to preserve attention. Content has lost focus and being deformed.

The image: "AstolfoKarmix", "with Iso-C", "with modified Iso-C", "x6b", "x6c" as the Rebasin.

After revising the algorithm, I found that "mean value" and "original value" can be interprepted as a Z Score funcitnon.

Since new parameter has been introduced, I just naively perform a image reconstuction test (applies for Dimensionality reduction such as PCA, SVD, and tSNE) to find the parameters.

Logically it is not equivalent to Model Merging, however the tiny relevance is enough to see advancement.
Image: AK, ISO-C, ISO-C Exp, 3x ISO-Z (0.8), 3x ISO-Z (2.0)

No more algorithms?
Other than sd-mecha, mergekit, there is a new toolkit "FusionBench" focusing on more recent algorithms, especially the rising MoE merging. However, SD is never trained on the entire denoising process, which it trains only 1 timestep (over 1000) for each image under an epoch. Such MoE merging still reqruies a full training process over gradient descent. Meanwhile, for fisher weight or ada merging, they requires continous evalulation over prediction, which is likely full denoised image instead of a single timestep. Therefore we don't have much options left.

Yes. The Karmix mentioned in Chapter 13. I figured out how to merge them, but I need to think about model pool over the algorithm. Since it is no longer exploring algorithms, I'll move to seperated article.