
Objective
Make your picture speak with the SadTalker extension
Environment
For this test I will use:
Stable Diffusion with Automatic1111 (https://github.com/AUTOMATIC1111/stable-diffusion-webui)
To install Stable Diffusion check my article : https://civitai.com/articles/3725/stable-diffusion-with-automatic-a1111-how-to-install-and-run-on-your-computerSadTalker component (https://github.com/OpenTalker/SadTalker.git )
Installing SadTalker Component
Go to Extension
Select Install from Url
Write https://github.com/OpenTalker/SadTalker.git
Click Install
After the process you will notice the new component in the installed tab(1).
(2) Press Apply and restart UI

This will restart Stable Diffusion

It will write during the restart:
Installing requirements for SadTalker
SadTalker will not support download all the files from hugging face, which will take a long time.
please manually set the SADTALKER_CHECKPOINTS in webui_user.bat(windows) or webui_user.sh(linux)Close "Stable Diffusion" and edit your webui_usr.bat bat file

Add the row : set SADTALKER_CHECKPOINTS=your folder
Set the path of your choise.
Then download the models from :
https://github.com/OpenTalker/SadTalker?tab=readme-ov-file

Unzip in a folder you defined before.
Using SadTalker
After restarting Stable Diffusion you will have now a new tab called "Sad Talker"

On the left you have to select and image and a voce (mp3 or wav file).
Generating the mp3
You can register your voice or take other, I will generate the mp3 with one of my tools
https://misterm.itch.io/mr-text-to-speech
It uses OpenAI API technology (you need an API code to use it).

The tools is quite easy.. you write your text, select a voice and press generate.. it will generate a mp3 file after few seconds.
You can also save the text and m3 generated and manage them.

I will write this text (attached you find the voice.zip file)
Welcome to today's tech news update. In a groundbreaking development, the tech world is abuzz with the latest release of the Stable Diffusion plug-in, dubbed SadTalker, which revolutionizes the way we communicate. This innovative tool enables users to articulate their thoughts and express emotions through speech in a more nuanced and authentic manner than ever before. Stay tuned as we delve deeper into how SadTalker is reshaping the landscape of spoken communication.
I have generated an image for a TV studio
TV woman sexy dress, presenter on TV, sitting speaking abou the news
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 541953647, Face restoration: GFPGAN, Size: 768x512, Model hash: e73d775ff9, Model: theTrualityEngine_trualityENGINEPRO, Denoising strength: 0.7, ENSD: 31337, Token merging ratio: 0.1, Token merging ratio hr: 0.1, Hires upscale: 2, Hires steps: 33, Hires upscaler: Latent, Eta: 0.5, Version: v1.7.0

1° TEST
Now I copy and paste the image on the Sadtalker Image and also I select my mp3 file
Then leave the default options, Set the flag GFPGAN as Face enhancer
Press Generate

Whit these option you will get only the cropped fase.. You can check the attached file face.zip with the mp4.

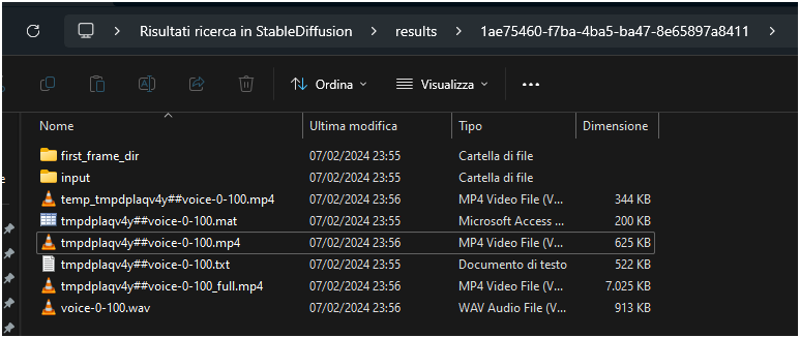
To check where are the files you can look at the console.
There are the path for the files.
Normally is the folder xx:\StableDiffusion\stable-diffusion-webui\results\
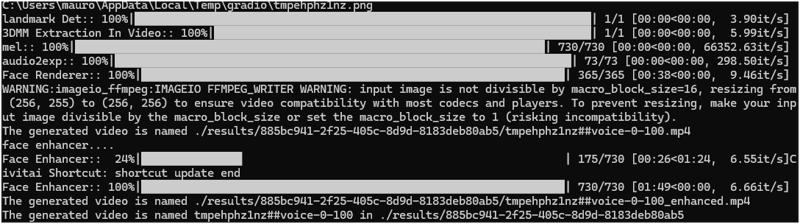

Depending of the length of the mp3 the generation can take long time.
If you access to the result folder you will fine a new folder , there are all the files used during the process. Mp3 , video of only the face, video with voice.
Whe it finish you get the full video.
Attention the flag GFPGAN as Face enhancer it makes the generation very slow because if process twice everything.

When it finish

Check out the output at : https://civitai.com/posts/1378394
Sometimes you can notice that the procedure only process a square of the face. It is not perfect.
I hope you enjoy the article. Let me know if you have any question in the comments.