


“存在即被感知——知识既为万物尺度,定将穷尽真理、根除谬误”
——《崩坏·星穹铁道》真理医生
*英文使用Chat-GPT4翻译,不保证准确性。如有问题直接评论区说就行,我有时也会出错,但我不是有错误不允许别人提出的人。
*Chat-GPT4 translation is used in English and accuracy is not guaranteed
作者注:
截至发稿,我tmd CivitaiSDXL和baseModel双榜2我需要蹭他的流量?还有这不是我的观点,说我拉踩的有问题的请先去看论文,这只是一篇纠错科普文档!
尊重他人选择,嘲笑他人命运
以及:群友要求加上的:

前言:
近期有这样一个模型和这样一个人,其标榜自己的模型为质量极好,而又拉踩其他的模型、作者。其抓到了一堆确实垃圾的模型喷了一顿。但是随后自己提出了一堆民科内容,然后大量的人听了他的话后被带偏,直到现在仍然有不少人认为他的结论是正确的。
后续是有些知道原理的人或者技术人员去反驳他的错误内容,都被他一一回怼。然后他在自己的文档中痛批说自己影响了很多模型作者的利益,被骂了。
其中错误乃至民科理论的影响范围相当广,外加上LiblibAI平台的推波助澜同流合污,实质上已经对很多人造成了影响。曾有群友去拿repo、readme跟论文去指证LibAI平台存在的某些错误但是LibAI相关的人反而认为这位群友所说的是主观民科理论的行为(他们认为Ghost等的理论才是正确的)
Recently, there has been a person who claims that their own model is of extremely high quality while criticizing other models and authors. They heavily criticized a bunch of genuinely trashy models, but then proceeded to propose a bunch of pseudoscientific content themselves. As a result, a large number of people, influenced by their words, have been led astray and still believe their conclusions to be correct.
The follow up was that some people or techs who knew the principles went to refute his incorrect content and were disliked back. Then GhostInShell was called out on his own documentation for complaining bitterly that he was affecting the interests of many model authors.
The influence of these errors and even pseudoscientific theories is quite extensive, coupled with the promotion and collusion on the LiblibAI platform, which has actually affected many people. There have been group members who have used repositories, readme files, and research papers to point out certain errors in the LibAI platform, but those associated with LibAI instead believe that the group member's claims are subjective pseudoscientific behavior (they believe that theories like Ghost's are the correct ones).
天天在看论文?:
虽然在简介区说自己天天看论文,但是其对于一些目前AI绘画比较基础模型/训练的论文知之甚少,跟完全没有看过一样。(可能是真的没看,谁知道呢):
比如之前的 ghostreview 测评工具,lycoris论文[2309.14859]早在23年9月已经提及了相关的东西,但是23年11月的ghostreview仍然使用了相关错误的方法。
Although it claims to read research papers every day in the introduction section, the author seems to have little knowledge of some of the current basic models/training papers in AI painting, as if they have never read them at all. (It's possible that they actually haven't, who knows): For example, the previous ghostreview evaluation tool and the lycoris paper [2309.14859] mentioned related things as early as September 23, but the November 23 ghostreview still used incorrect methods related to them.


研究记录(Research record):
Style Loss能否作为评价Stable Diffusion模型对LoRA模型兼容性的指标? | Civitai
我们首先来看他的训练数据:
Let's start by looking at his training data:
相信有过炼丹的人应该能看得出来一点东西的,就算没怎么接触过也应该可以看出,这位作者甚至连arb都不会用,Lr开到基本没炼一样(PS:Animagine都开到快1e-5了),他整个训练参数都透露着一种随心所欲不韵世事的感觉。
People who have experience in alchemy should be able to see something from this. Even if they haven't had much exposure to it, they should be able to tell that this author doesn't even know how to use arb and barely refines Lr (PS: Animagine even refines it to almost 1e-5). The author's entire training parameters reveal a sense of whimsy and disregard for worldly matters.
model_train_type = "sdxl-finetune"
pretrained_model_name_or_path = "./sd-models/animagineXLV3_v30.safetensors"
v2 = false
train_data_dir = "./train"
resolution = "1536,1536"
enable_bucket = true
min_bucket_reso = 256
max_bucket_reso = 1536
bucket_reso_steps = 64
output_name = "ghost_test2"
output_dir = "./output"
save_model_as = "safetensors"
save_precision = "fp16"
save_every_n_epochs = 1
max_train_epochs = 10
train_batch_size = 1
gradient_checkpointing = true
learning_rate = 0.000004
learning_rate_te1 = 5e-7
learning_rate_te2 = 5e-7
lr_scheduler = "constant_with_warmup"
lr_warmup_steps = 0
optimizer_type = "AdaFactor"
min_snr_gamma = 5
sample_prompts = "(masterpiece, best quality:1.2), 1girl, solo, --n lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, --w 1024 --h 1024 --l 7 --s 20 --d 1337"
sample_sampler = "dpm_2"
sample_every_n_epochs = 1
log_with = "tensorboard"
logging_dir = "./logs"
caption_extension = ".txt"
shuffle_caption = true
weighted_captions = false
keep_tokens = 0
max_token_length = 255
noise_offset = 0.1
seed = 1337
no_token_padding = false
mixed_precision = "fp16"
full_fp16 = true
xformers = true
lowram = false
cache_latents = true
cache_latents_to_disk = true
persistent_data_loader_workers = true
optimizer_args = [
"scale_parameter=False",
"relative_step=False",
"warmup_init=False"
]
train_text_encoder = true其次,其融合配方如下:
Secondly, its fusion formula is roughly as follows:
(AnimagineV3+10ep)×0.7
LEOSAMHelloWorldV5 ×0.15
dreamshaperXL_v21TurboDPMSDE x0.15
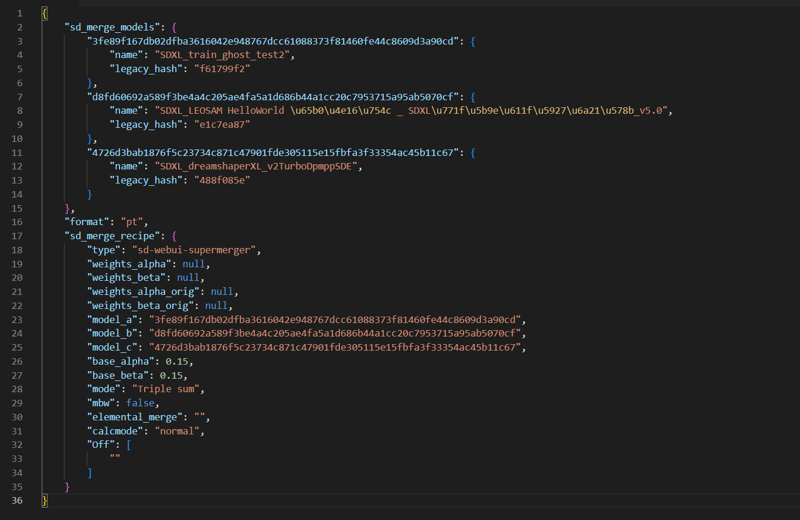
代码块↓
{
"sd_merge_models": {
"3fe89f167db02dfba3616042e948767dcc61088373f81460fe44c8609d3a90cd": {
"name": "SDXL_train_ghost_test2",
"legacy_hash": "f61799f2"
},
"d8fd60692a589f3be4a4c205ae4fa5a1d686b44a1cc20c7953715a95ab5070cf": {
"name": "SDXL_LEOSAM HelloWorld \u65b0\u4e16\u754c _ SDXL\u771f\u5b9e\u611f\u5927\u6a21\u578b_v5.0",
"legacy_hash": "e1c7ea87"
},
"4726d3bab1876f5c23734c871c47901fde305115e15fbfa3f33354ac45b11c67": {
"name": "SDXL_dreamshaperXL_v2TurboDpmppSDE",
"legacy_hash": "488f085e"
}
},
"format": "pt",
"sd_merge_recipe": {
"type": "sd-webui-supermerger",
"weights_alpha": null,
"weights_beta": null,
"weights_alpha_orig": null,
"weights_beta_orig": null,
"model_a": "3fe89f167db02dfba3616042e948767dcc61088373f81460fe44c8609d3a90cd",
"model_b": "d8fd60692a589f3be4a4c205ae4fa5a1d686b44a1cc20c7953715a95ab5070cf",
"model_c": "4726d3bab1876f5c23734c871c47901fde305115e15fbfa3f33354ac45b11c67",
"base_alpha": 0.15,
"base_beta": 0.15,
"mode": "Triple sum",
"mbw": false,
"elemental_merge": "",
"calcmode": "normal",
"Off": [
""
]
}
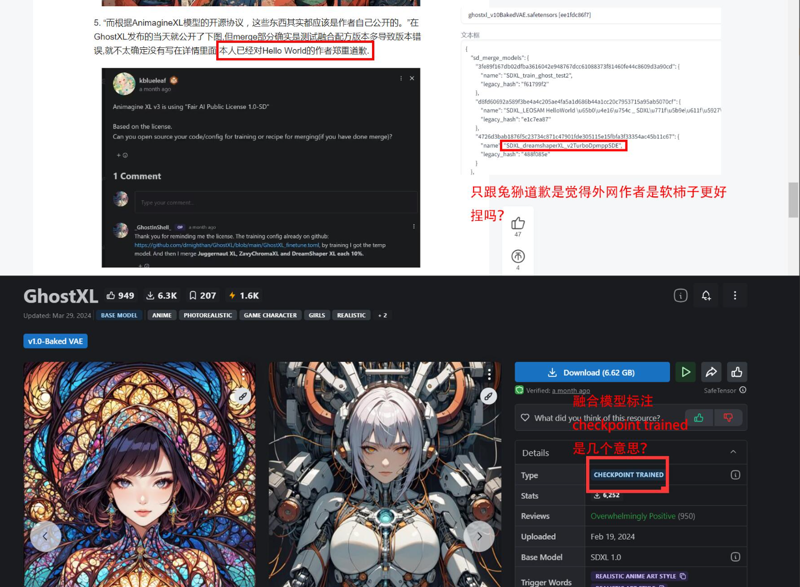
}另外一点就是,虽然Ghostshell在评论区给了融合的比例,但是给出的完全是错误的,跟模型内的元数据是完全不同的。
而根据AnimagineXL模型的开源协议,这些东西其实都应该是作者自己公开的。当然模型融合需要经过多轮次的测试,有的时候作者忘记了融合配方是再正常不过的事了。这里应该是GhostXL的作者忘了,那么我在这里就帮助GhostXL的作者想一下。
我们对此做了研究并且复刻了GhostXL的融合方法,当然我们并没有经过上述训练,只是重新将Animagine、LEOSAMHelloWorldV5、dreamshaperXL_v21TurboDPMSDE按照上述比例融合到了一起:
GhostbustersXL mix - v1.0 | Stable Diffusion Checkpoint | Civitai
According to the open-source license of the AnimagineXL model, these things should actually be disclosed by the author themselves. However, the author did not specify them in the model interface.
We have conducted research on this and replicated the fusion method of GhostXL. However, we have not undergone the aforementioned training. Instead, we simply combined Animagine, LEOSAMHelloWorldV5, and dreamshaperXL_v21TurboDPMSDE in the proportions mentioned above.
GhostbustersXL mix - v1.0 | Stable Diffusion Checkpoint | Civitai

Ghost的理论/观点(错误):
Fallacy and explanation:



目前Civitai的文章已删除,但是在知乎的文章还在:
At present, the article on Civitai has been deleted, but the article in Zhihu is still there:
/
GhostMix作者个人观点:关于StableDiffusion模型的发展方向和现有checkpoint模型乱象的思考 | Civitai
GhostReview:全球第一套AI绘画ckpt评测框架代码工具(By GhostMix Creator) | Civitai
/
GhostMix作者:关于StableDiffusion模型的发展方向和现有checkpoint模型乱象的思考 - 知乎
GhostMixV2.0模型特性及自己的Checkpoint评价体系 - 知乎
认知及理论:
Cognition and theory:
借着这个事,让我们来讲解一下相关的内容。当然你也可以看原视频,接下来的内容基本都是这个视频的总结:
Through this matter, let's explain the relevant content. Of course, you can also watch the original video, and the following content is basically a summary of this video:
视频:https://www.bilibili.com/video/BV1ux4y1r7op
视频总结:https://docs.qq.com/doc/p/2ada6c76b8f98cf4dd8d70b4375d9c349ba3f9fd
什么是微调(finetune)
Finetune?
● 微调是将现有的模型依照自己的需求进行额外的训练
例如:普通的SD1.5跑二次元图是很烂的,但是我想要二次元的图,这时候去喂一堆二次元图区训练得到一个二次元图,这就是微调。但是需要主要,这时候模型本身要做的事情并没有变。
● 其他方式:“迁移训练”Transfer Learning(不属于微调)
依照自己的需求,使用现有的模型作为自己模型的一部分,训练额外增加或者更改部分以达成目的。模型本身做的是跟我想要做的事不一样但是很接近,这种前提下拿去做额外的训练用以达成自己的目的,这叫做迁移训练。
例如:ImageNet的预训练模型,我想要拿来分类我自己手上的图片,我把最后一个网络层换掉,然后在自己的资料集上训练这最后一层,这个就是迁移训练
迁移训练和微调很多情况下是可以一起使用的,有些时候可以先做完简单的迁移训练之后再去微调
● 数学上是怎么讲解的:
一个很简单的模型F(X)=WX+B(看不懂回去读高中)
从F(X)为基础训练一个g(X)=W'X+B,只改变上面的W,W→W'这个过程就是微调
Fine-tuning is the process of training an existing model according to one's own needs. For example, if a regular SD1.5 model performs poorly when it comes to 2D images, but one wants to work with 2D images, they can feed a bunch of 2D images into the model to train it specifically for 2D images. This is called fine-tuning. However, it is important to note that the core task of the model remains unchanged during this process.
Another approach is "Transfer Learning," which is not considered fine-tuning. Transfer learning involves using an existing model as part of one's own model and training additional or modified parts to achieve specific goals. In this case, the model itself may not perform the exact task one desires, but it is similar enough to be used for additional training to achieve one's own objectives. This is referred to as transfer learning. For example, using the pre-trained model from ImageNet to classify one's own set of images by replacing the last network layer and training it on the new dataset is an example of transfer learning.
Transfer learning and fine-tuning can often be used together, and sometimes it is recommended to first perform simple transfer learning before fine-tuning.
In mathematical terms, let's consider a simple model F(X) = WX + B (if you don't understand, go back and read high school math). The process of training a new model g(X) = W'X + B based on F(X), by only changing the value of W to W', is referred to as fine-tuning
LoRA?LyCORIS?
同样是考虑W→W',我们可以将其看成g(X)=WX+B+(W'-W)X,也就是g(X)=F(X)+(W'-W)X,相当于说微调就是在F(X)的基础上,额外加上一个h(X)=△W(X),其中△W=(W'-W)
如果你的模型很大,这就意味着你的h(X)也很大,代表你需要使用更多的资源去微调你的模型,代表你的显卡可能装不下,最开始炼制SDXL使用3090/4090的24G都可以吃满,这个时候我们就不想要花这么大的力气去处理h(X),模型很大那么△W自然也会很大,因为矩阵是相同形状的,但是实际上很多时候我们并不需要这么大的△W。
↓
LoRA:我们提供精简版的△W(LoRA就是利用低迭分解去模拟一个△W),利用比较小的大小来模拟一个完整的△W,并且很多时候这个是完全够用的
LyCORIS:用各种不同的方式去模拟一个△W
这个是比较热门的研究方向,论文数量很多,因为SD本身是比较小的参量有限,但是对于70B等语言模型来说,确实需要一个小很多,但是把你想要练的东西学进去的△W,LoRA/LyCORIS就是在这个基础上发展出来的东西
LyCORIS/LoRA的目的就是用更小的参数去存这个△W,所以这代表LoRA就是微调
错误的信息产生:很多人希望分清这个△W是完整的和不完整的,所以只把△W是完整的这一种情况叫做微调,但是后续很多人就把这些东西分的越来越开了,导致很多人认为训练LoRA和LyCORIS并不是微调,但是实际上这都是同一个东西。
LoRA和LyCORIS的目的,就是用更少的参数量去产生一个h(X)。(也就是PEFT)。本质上LoRA和LyCORIS就是微调,他们做的事情是一样的,不然为什么Dreambooth练完的东西可以“提取”成LoRA呢?
很多时候既然可以抽成LoRA可以用,那么为什么不直接练成LoRA。但是很多人有固有思维认为LoRA不能做某些事情,认为LoRA/LyCORIS只可以练单一角色风格,但是很多时候可以把不同的概念塞到同一个模型里。
When considering W→W', we can view it as g(X)=WX+B+(W'-W)X, which is equivalent to g(X)=F(X)+(W'-W)X. In other words, fine-tuning is adding an additional h(X)=△W(X) on top of F(X), where △W=(W'-W).
If your model is large, it means that your h(X) is also large, indicating that you need more resources to fine-tune your model. It may also mean that your graphics card may not have enough capacity. Initially, when training SDXL, using a 3090/4090 with 24GB was sufficient. At that time, we didn't want to spend so much effort on handling h(X). If the model is large, △W will naturally be large as well because the matrices have the same shape. However, in many cases, we don't actually need such a large △W.
LoRA: We provide a simplified version of △W (LoRA uses low-rank decomposition to simulate △W), using a smaller size to simulate a complete △W. And many times, this is completely sufficient.
LyCORIS: Simulating a △W using various different methods.
This is a popular research direction with a large number of papers because SD itself has limited parameters. However, for language models like 70B, a much smaller one is needed. But △W, which incorporates what you want to learn, is still large. LoRA/LyCORIS is developed based on this.
The goal of LyCORIS/LoRA is to store this △W with fewer parameters, so LoRA represents fine-tuning.
Misinformation: Many people hope to distinguish between a complete and incomplete △W, so they call only the case of a complete △W fine-tuning. But subsequently, many people have further divided these concepts, leading to the misconception that training LoRA and LyCORIS is not fine-tuning. But in reality, they are the same thing.
The purpose of LoRA and LyCORIS is to generate an h(X) with fewer parameters (also known as PEFT). Essentially, LoRA and LyCORIS are fine-tuning, and they do the same thing. Otherwise, why can the output of Dreambooth be "extracted" as LoRA?
Often, if it can be extracted as LoRA and used, why not train it directly as LoRA? But many people have inherent thinking that LoRA cannot do certain things, and they think that LoRA/LyCORIS can only train a single character style. However, many times, different concepts can be incorporated into the same model.
具体差距
Specific differences
既然都是微调,那我们不能从训练的角度直接说差别。虽然说LoRA、LyCORIS就是微调,但是不同算法之间的差距绝非肉眼可见的,所谓XX美院XX美术专业可以从细节上区分算法之间的差距都是无稽之谈。而且也不是LoRA只能练单一角色,LyCORIS可以给角色分的更开这种错误的现象归纳。
你需要去考虑本质上的区别,你再把本质区别去映射到现象上,并不能之间对着现象归纳
● 这些不同算法之间的差距从更本质的角度来说可以用以下的差距去讨论:
①资讯容量(用多少参数去存这个△W):一般来说最大就是跟△W一样大,但是有很多炼丹师听信了错误的言论,dim开到好几百,导致的最后的大小比原本W还要大。当然因为SDXL的△W足够大,实际上你开很小的dim就足够用了
②数学性质(越接近△W原有性质的PEFY算法效果通常更好,通常来说并非资讯容量而是数学性质,例如DoRA就是针对这点改善):Lokr和loha本身也是从数学性质上强调。LoKr就是利用很少的资讯量来达到很高的rank,Loha是资讯量高rank高
③速度:(这个直观表现)SD1.x里面一般来说直接微调更快,SDXL的LoKr更快等等……
Since they are all fine-tuning, we cannot directly compare the differences from a training perspective. Although LoRA and LyCORIS are both fine-tuning algorithms, the differences between different algorithms are not visible to the naked eye. It is ridiculous to claim that certain art schools or art majors can distinguish the differences between algorithms based on details. Furthermore, it is incorrect to assume that LoRA can only train a single character, while LyCORIS can divide characters more effectively.
You need to consider the fundamental differences and then map them to the phenomena. You cannot directly generalize based on the phenomena.
The differences between these algorithms can be discussed from a more fundamental perspective using the following criteria:
1. Information capacity (how many parameters are used to store the △W): Generally, the maximum is the same as the size of △W. However, many alchemists have mistakenly believed in the wrong statements and opened dimensions to several hundred, resulting in a final size larger than the original W. Of course, because SDXL's △W is large enough, you can actually use a smaller dimension.
2. Mathematical properties (PEFY algorithms that are closer to the original properties of △W usually have better performance; usually, it is not information capacity but mathematical properties, such as DoRA, which improves on this aspect): Lokr and Loha themselves emphasize mathematical properties. LoKr uses a small amount of information to achieve a high rank, while Loha has high rank with high information capacity.
3. Speed (this is the intuitive performance): Generally, direct fine-tuning is faster in SD1.x, while LoKr in SDXL is faster, and so on.
谬误与迷思
Fallacies and myths
①LoRA/LyCORIS是拿来少图练单一概念的
→Dreambooth才是拿来少图练单一概念的东西,并且DB和微调/LoRA是不同层面的概念:
LoRA/LyCORIS并不是拿来单独练某一东西的,其用途是让微调这件事变得不那么痛苦。而所谓的少图练单一概念,那是你想的要微调什么,LoRA/LyCORIS只是改进你用来做到少图练单一概念的东西的东西
Dreambooth这个东西跟LoRA/LyCORIS是完全不同的层面,考虑是不同的东西,DB在接近你想要的东西的时候需要微调模型,这个微调的部分可以使用LoRA等,LoRA/LyCORIS是达成dreambooth的一种工具,dreambooth并非只能保存大模型
②融了LoRA的模型,不能拿来当训练底模
→都行,但是这涉及好不好用的问题,只是炼烂的模型拿来当底模一样很痛苦。
另外你可以用△W去理解模型的融合,但是很多人很喜欢用民科的内容来解释这个东西
③不能用LoRA/LyCORIS炼底模
→为什么不行,Kohaku V3/4/5、Kohaku XLdelta、SDAS A3.33都是这样搞的
→如果你接触LLM的话,使用LoRA和其他PEFT炼底模是非常常见的
①LoRA/LyCORIS is used to practice a single concept with fewer pictures.
→Dreambooth is the tool used to practice a single concept with fewer pictures, and DB and fine-tuning/LoRA are different concepts on different levels:
LoRA/LyCORIS is not used for practicing a single concept on its own. Its purpose is to make the process of fine-tuning less painful. The idea of practicing a single concept with fewer pictures depends on what you want to fine-tune, and LoRA/LyCORIS is just an improvement on the tool you use for practicing a single concept with fewer pictures.
Dreambooth is on a completely different level compared to LoRA/LyCORIS. It involves different considerations. When approaching what you want, DB requires model fine-tuning, and LoRA can be used for this purpose. LoRA/LyCORIS is a tool to achieve dreambooth, and it does not only work for saving large models.
②A model with LoRA incorporated cannot be used as a training base model.
→It is possible, but it depends on whether it is effective. Using a poorly trained model as a base model can be equally painful.
Additionally, you can understand the integration of models using △W, but many people prefer to explain this concept using pseudo-scientific content.
③LoRA/LyCORIS cannot be used to train a base model.
→Why not? Kohaku V3/4/5, Kohaku XLdelta, and SDAS A3.33 are all trained using this method.
→If you have experience with LLM, it is very common to use LoRA and other PEFT methods to train a base model.
LoRa通用性越高越好?(错误)
The higher the versatility of LoRa, the better?(Wrong)
只有在“模型都有同一个爹”的基础上才会去讨论LoRa的泛用性。
SD1.5大部分LoRa通用的原因是绝大部分模型都有nai1这一个父模型,而使用nai的后代模型训练的LoRa在ink_base这一从SD1.5直接训练的动漫模型上使用效果是极差的。而到了SDXL,因为二次元模型没有一个共同的二次元爹,大家都是从An3/kohaku/pony等模型训练,这就导致现在SDXL不同模型的LoRA大都不好通用(混用效果很差,但是并不代表着模型不行)。
Most of the LoRa models in SD1.5 are generally applicable because the majority of them have a common parent model called "nai1". However, using LoRa models trained on descendants of nai in the ink_base, a directly trained anime model in SD1.5, yields very poor results. In contrast, in SDXL, since the 2D models do not have a common 2D parent, they are trained from models such as An3/kohaku/pony, which leads to poor generalizability of LoRA across different models in SDXL
(The effect of not following the bottom mold is very bad, but this does not mean that the quality of the model is poor.)
