


Link to the image. Shameless plug to my original article.
Personality test towards AI? Are you assuming it has mind!?
Nah, SD cannot reflect properly and answer enormous follow-up questions. LLM will simply made up everything without truely referring the details.
Warning: Even I'm proposing a qualitive test coining the idea of HTP test, it is quite personal and cannot fufill your CS or Art study. This is also not suitable for model with a clear learning target.
Before continue reading, please read this, this, and try out this as professional grade (quantitative) evalulation.
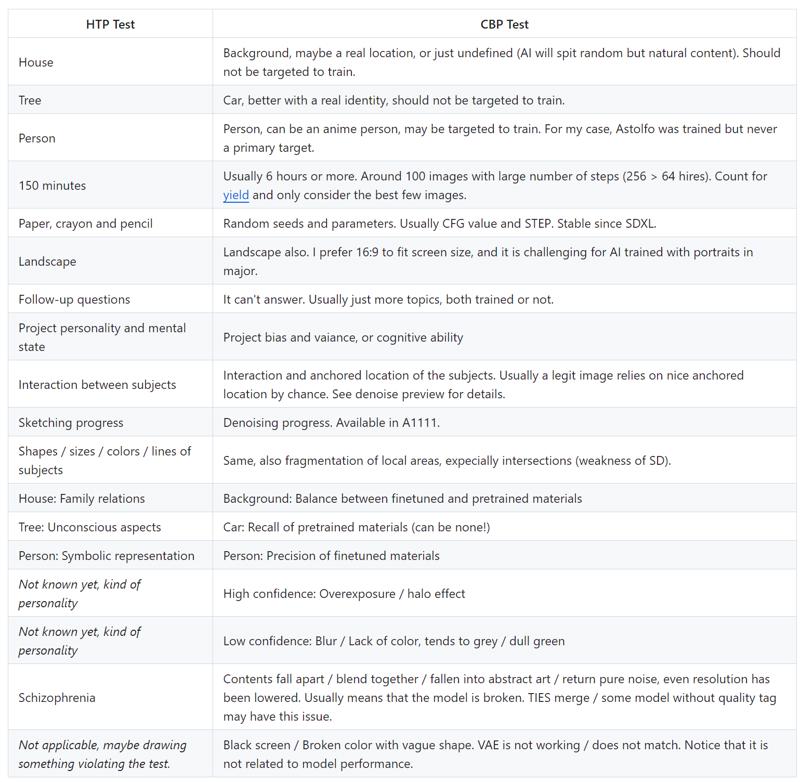
House-Tree-Person test is a popular psychology test on human, to let them project personality and subconscious mind. By either switching projection method from hand drawing into making AI model, or just let "AI model" projecting its undefined behaviour no matter how much we know it, we can design / metaphorize a qualitive test by coining the idea from HTP test. It is better then just splashing a XY grid to the academic paper with little description, then discuss on quantitative test entirely and appeal to the masses.
Instead of "subconscious mind", AI model will project bias and variance along with confidence level. Given some prompts not familiar with training dataset, or just implication (a.k.a "logic") with no words given, AI must guess what should be the interaction between clusters of pixel, and keep the denoising process running to finalize what will be the shape, color, and location of the contents. Given the Markov decision process as the diffusion process, prediction is seldom changed once they are made. Therefore when the uncertainty is high (yet contents are still pretrained instead of never seen), "prediction" can go wild and random, sometimes positively creative, usually just looks broken (no, not abstract art).
Here comes my "Astolfo's Car-Backgound-Person test", which can perform sanity check effecively by looking how many pretrained contents can be recalled, which is usually oppose the learning target, making sure the AI model is still balanced and can continue finetuning. Notice that "great balance" may not be archieved by finetuning, more like by merging (weighted averaging) checkpoints acorss the training process. Moreover, when merging models, "training target" is not projected to the dataset (model pool, haystacks), RL approach will rely on evaluation (reward / loss model) so much, especially executed by human without program codes in hand.

Link to the image. Prompt contains 4 words only.
Since CivitAI doesn't support table view, I use screenshot instead.
Most famous models will failed to output contents out of trained materials. It is because the task nature (creative act) greatly favours on model bias i.e. not balanced, tends to forget pretrained content. Instead of conducting experiments with scale, sometimes a few images can quickly visualize if the training process is good, and project author's soul into the creation (AI model). Make sure the follow-up answer will be answered, from the author, a human.
The "test cases" I'm using on 2506
- No prompt at all (unconditional generation)
- A few words only (no 1girl, solo, just artist, character)
- "Person with car" (no one trains car)
- Direct copy and paste from booru / e621 dataset (random selected)
- Booru / e621 dataset but with NLP caption (random selected)
- "kko" (direct prompt copy and paste) from any images you like in different communities. Usually NovelAI prompts
- TIPO generated prompts, probably for realistic images also
All these test combined will be super duper hard for a trained model, but usually easy for a merged model
