Type | Other |
Stats | 73 |
Reviews | (11) |
Published | Jan 11, 2025 |
Base Model | |
Hash | AutoV2 54FD017021 |


HUNYUAN | Test bench
The BASIC workflows are designed to be as simple as possible, keeping in mind your precious feedbacks (ty) about my previous workflows being too complex. It also allows to exceed 101 frames (actually did 201 frames in only 249 seconds)
It includes the settings and values I use more often after daily use since day one.
The workflows are built around the Fast model, but feel free to switch to another model and raise steps accordingly. By default, the Fast Lora is also loaded but set to a negative value. This is because I find the Fast model to be a bit "overcooked," so I tend to dial back the "Fast factor" from itself.
If you’re curious to understand this reasoning in more depth, I recommend checking out this article: [link]
Advanced workflows includes a bit more compared to the basic one.
However, I believe that beyond a certain threshold, it starts becoming too complicated and less user-friendly. So, I thought that the bare essentials, which I consider the absolute minimum, will be found in the basic workflows.
Anything additional start being included in the advanced workflows.
All the worflows avaible on this page are focused on the settings I use most often, prioritizing timing, achieving good results AS QUICK AS POSSIBLE, NO COMPROMISES.
If you are looking for ultra-high-quality videos and the best this model can deliver
then this is not the workflow for you.
I settle for acceptable balance between quality and speed.
Long waiting times make it impossible to truly understand how this model behave and respond to every little settings changes , the loras you swap, sizes and so on.
You can't master the use of any AI models with eternal waiting times
🟩"BASIC All In One" workflow has 3 method to operate:
T2V
I2V (sort of, an image is multiplied *x frames and sent to latent, with a denoising level balanced to preserve the structure, composition, and colors of the original image. I find this approach highly useful as it saves both inference time and allows for better guidance toward the desired result). Obviously this comes at the expense of general motion, as lowering the denoise level too much causes the final result to become static and have minimal movement. The denoise threshold is up to you to decide based on your needs.
There are other methods to achieve a more accurate image-to-video process, but they are slow. I didn’t even included a negative prompt in the workflow because it doubles the waiting times.
V2V same concept as I2V above
🟩"BASIC All In One TEA ☕" is an improved version of the one above, with slightly different settings for even faster speed. It's based on tea cache
🟩 "Advanced All In One TEA ☕" is an improved version of the BASIC All In One TEA ☕, with an additional method to upscale faster plus a lightweight captioning system for I2V and V2V, that consume only additional 100mb vram.
Bonus TIPS:
Here an article with all tips and trick i'm writing as i test this model:
https://civitai.com/articles/9584
if you struggle to use my workflows for any reasons at least you can relate to the article above. You will get a lot of precious quality of life tips to build and improving your hunyuan experience.
__________________________________________________________________________________________________
All the previous workflows avaible on this page are OLD and highly experimental, those rely on kijai nodes that were released at very early stage of development.
If you want to explore those you need to fix them by yourself.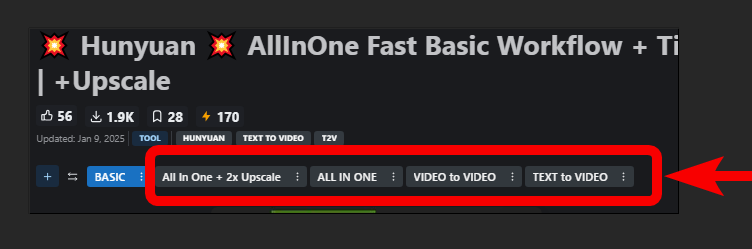
__________________________________________________________________________________________________
__________________________________________________________________________________________________
__________________________________________________________________________________________________
__________________________________________________________________________________________________
UPDATE 06/12/2024
TRITON NO LONGER A REQUIREMENT.
⚠️change to SDPA or COMFY if you don't have TRITON installed
it will go a little slowed but works.
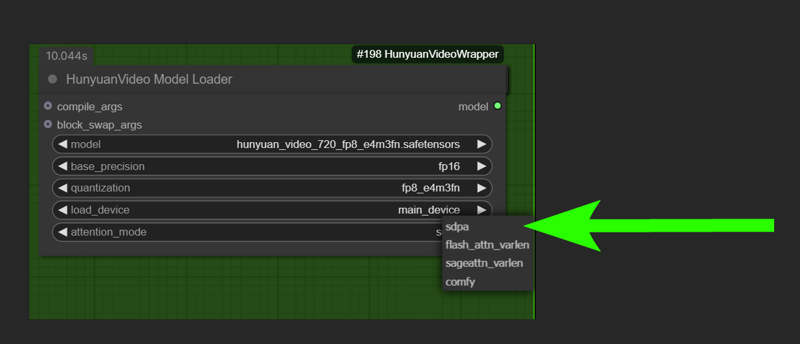
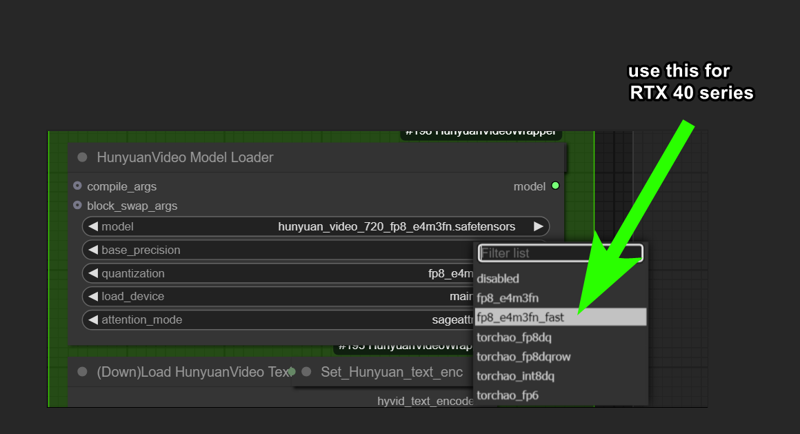
⚠️ if you get "int float" error or something try redownload the workflow, is a temporary bug of some nodes. I think i fixed. Let me know pls.
⚠️To run this model faster you may need to install torch on windows, wich is kinda pain in the ass. Fortunately purz wrote an installation guide for all of us: link.
Another usefull install guide: https://www.reddit.com/r/StableDiffusion/comments/1h7hunp/how_to_run_hunyuanvideo_on_a_single_24gb_vram_card/
⚠️ This model is completly uncensored, it knows human anatomy better than flux.
beware on prompting and be nice on posts and reviews ffs! previous post became pornhub instantly ..as expected 🤣
⚠️it can't do Will Smith. No spaghetti time 🍝 Sorry about that
__________________________________________________________________________________________________
💥 INCREDIBLE MODEL JUST CAME OUT 💥 I'm speechless.
Kijai, our lord, has already made huge improvements to allow us to run this gold on consumer hardware with great speed. So, here we go:
With settings included in this workflow you can easily explore the latent space capabilities of this 13B beast and do all stress tests you want.
__________________________________________________________________________________________________
around 16gb vram on lowest settings but not really sure.
__________________________________________________________________________________________________
default settings of the workflow has very low steps, for the multi pass upscale thing.
if you are not going to use it and only doing one pass generation you should raise that steps slider to 12 or above
in this workflow you can load an image or a video.
-upload an image, it will be used to create auto prompt, and with a denoise lower than value 1 it will guide the video (not suggested, the video will be almost frozen the more you lower the denoise. just use it for autoprompt or for experiment. it can be usefull in some cases like steady shots)
-upload a video and do video to video. auto prompt will be created by analizing the first frame.
in both cases you can choose to disable auto prompt and make your prompt manually and/or leave denoise at value 1 and do TEXT to VIDEO without any input influence.
__________________________________________________________________________________________________
9 seconds generation time per video (*)
(*) rtx3090 - old workflows:
vid2vid mode
0.6 denoise
512x320 resolution
17 frames
12 steps
This setup is excellent for testing purposes.
Naturally, you can use whatever setting you prefer to achieve better quality.
Experiment with it and please share your feedbacks and findings!
__________________________________________________________________________________________________
 __________________________________________________________________________________________________
__________________________________________________________________________________________________
if you want to see some real magic try this settings for txt2vid
720x480 - 25 steps - 17 frames
it takes 1:05 sec per clip on 3090 and results are .. unbelievable.
__________________________________________________________________________________________________
https://arxiv.org/pdf/2412.03603 Very Informative Reading
__________________________________________________________________________________________________
Have fun