Updated: Nov 30, 2025
base modelDownload
1 variant available
fp16 SafeTensor
BDRotate+eih15_celestiBlueemb+eih15vpredtext2.safetensors
Half precision, best balance • 6.46 GB
Verified: 8 months ago


License:
NoobAI License
a.k.a. Türkiye model (SHIH)
Description
Random merge of the two recently downloaded models I liked the most, Better Days and ΣΙΗ. Noob vpred model, Retains the best features from both IMO, keeps powerful artist tags and composition from ΣΙΗ but enhances it with some of the lighting effects from Better Days. Made via. un-sepia-fying Better Days via mecha-merge maneuvers, before merging in composition, vpred, artist blocks from ΣΙΗ, before finally mutilating the CLIP with with NVIDIA's QLIP-L-14-392. See Merge Process section for more details.
Usage
Standard NoobAI quality tags apply. Check NoobAI documentation for details. In addition, the very aesthetic positive and displeasing negative tags have some minor effect. The recommended structure according to LAXHAR Labs for ordering prompts is: artist tags, [your prompt here], quality tags
This is a V-pred ZSNR model and will not work with Automatic1111-webui. In order to get images out of vpred models you need to either switch the dev branch on Automatic1111 webui, ComfyUI or reForge. My personal recommendation is to switch to reForge. This model comes with a bundled VAE.
In order to replicate the example images you may have to play around with reForge/ComfyUI extensions. There will be a hyperlink to an article detailing how to utilize PAG and SEG once I finally get around to writing it, but for now if you want to replicate the images perfectly, the best option is to download the image and drag it into PNG Info tab on reForge, making sure to turn off Override for Hires. fix as necessary because for some reason the extension will automatically tick that off.
Don't be this idiot.
License
Same as NoobAI.
Merge Process
In the interest of disclosure and proliferation of merging knowledge, the full list of steps is listed below. Some steps are abbreviated, you should be able to do them should you download the correct ComfyUI nodes. Most of this done through sd-mecha, you may be able to retrofit them to ComfyUI nodes and do them via the Comfy-Mecha extension if you/DeepSeek understand python.
0. betterDaysIllustriousXL_V01ItercompPerp.mecha
1. betterDaysIllustriousXL_V01Cyber4fixPerp.mecha
2. betterDaysIllustriousXL_V01CyberillustfixPerp.mecha
3. merge "weighted sum" &0 &1 alpha=0.5
4. merge "weighted sum" &0 &2 alpha=0.5
5. merge "weighted sum" &3 &4 alpha=0.5Rename the resultant file betterDaysIllustriousXL_V01ItercompCyberfixPerpWeightedSum05Squared. If you want, you can also name step 3 betterDaysIllustriousXL_V01ItercompPerpCyber4fixPerpWeightedSum05 and step 4 betterDaysIllustriousXL_V01ItercompPerpCyberillustfixPerpWeightedSum05. Or you could just download them from here/here because I obsessively store every checkpoint I make.
(And if you really want, you can take a look here to see what they look like.)
6. recipe_deserialize_mda_queue.py
7. vpredtimeout2emb.py
8. recipe_deserialize.pyLast step is the QLIP replace, I just did it through ComfyUI instead of sd-mecha because it's easier and Comfy already packs most of the nodes by default.
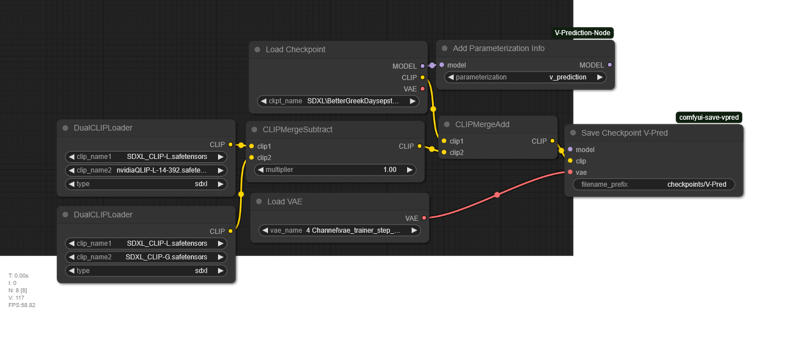 Possible improvements: Steps 3-5 could probably be done better by using a more sophisticated merging method than simple weighted sum. SLERP is the easy drop in replacement, comparative fisher is probably the one that would give the best results atm but I have no idea how to implement that. Could get the text encoder weights from another model. Lobotomized is the easy choice considering the CLIP is more or less similar but it has slightly adjusted unet segments for more quality keywords. Could also just skip Steps 0-5 to just SHADOWMAXX, but I have no idea if that would be good or bad without testing. QLIP replacement is questionable, could skip or maybe use DARE merging. CLIP merging techniques are sadly underdeveloped, given lack of identifiable blocks of weights in CLIP.
Possible improvements: Steps 3-5 could probably be done better by using a more sophisticated merging method than simple weighted sum. SLERP is the easy drop in replacement, comparative fisher is probably the one that would give the best results atm but I have no idea how to implement that. Could get the text encoder weights from another model. Lobotomized is the easy choice considering the CLIP is more or less similar but it has slightly adjusted unet segments for more quality keywords. Could also just skip Steps 0-5 to just SHADOWMAXX, but I have no idea if that would be good or bad without testing. QLIP replacement is questionable, could skip or maybe use DARE merging. CLIP merging techniques are sadly underdeveloped, given lack of identifiable blocks of weights in CLIP.
Feel free to steal this tech and improvement it if you want/can. In fact, if you can improve it, please do. As with LobotomizedMix, the code is here.
Q & A
Q: Stupid name.
A: Thanks.Q: Why does the font on the cover image look so stupid
A: Not my fault, there's like a total of 8 different fonts that support Turkish script, alright? Gimme a break, I had a very limited number of choices to work with.Q: Does this model have innate artist tags?
A: Yeah and they're quite strong as well. I recommend experimenting to see what combination of artists you like.Q: How would you say it compares to the source models?
A: Prefacing my opinions with the caveat that it is subjective, I think it's an improvement on the quality of ΣΙΗ and an improvement of the versatility and power of Better Days. The primary issue with better Days is that it's very much locked into one lighting style. Though you can change things like the texture quality, smoothness, lighting is very hard to affect in Better Days, or more specifically it is impossible to get unmotivated lighting. As a result even though Better Days is responsive to artist keywords (see here), everything ends up looking very similar anyways because illumination and shadow will come from the same angles.Q: What do you mean by 'unmotivated' lighting?
A: Okay so lighting, in not only images but also cinematography, is directional. Often times, a primary source of lighting is practical lighting, from sources that you can see right in the image. The moon in an image, like here, is practical lighting. You take that one step further with lighting that you could theoretically see and we call that motivated lighting. In this image, we don't see the source of the lighting, but it's one directional and coming off from this direction, which could exist. So given those two, unmotivated lighting is then lighting that doesn't have an explanation but simply exists to illuminate the scene. And why does that cause a ton of silhouettes in Better Days? Because Better Days hates unmotivated lighting and loves realistic, i.e. motivated lighting and the viewer is not carrying around a spotlight. So we get this: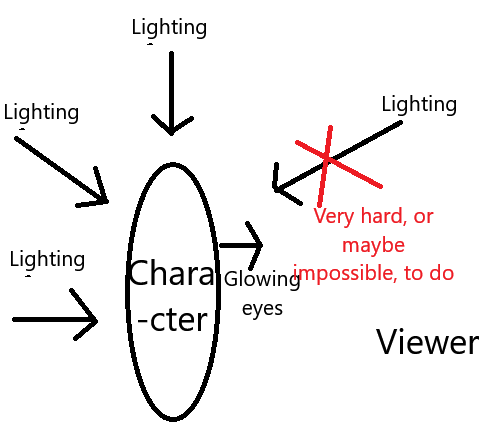 This is the primary reason why silhouettes are so prominent in Better Days and it looks so good with glowing eyes, because it basically just defaults to practical/motivated lighting and rarely if ever does unmotivated lighting. This is both a strength and a weakness because while it allows you to do very atmospheric dramatic scenes, you basically are locked into that style of generation. You won't notice it if you just use Better Days but once you start doing x/y comparison tests you will start noticing it.
This is the primary reason why silhouettes are so prominent in Better Days and it looks so good with glowing eyes, because it basically just defaults to practical/motivated lighting and rarely if ever does unmotivated lighting. This is both a strength and a weakness because while it allows you to do very atmospheric dramatic scenes, you basically are locked into that style of generation. You won't notice it if you just use Better Days but once you start doing x/y comparison tests you will start noticing it.Q: But
betterDaysIllustriousXL_V01ItercompCyberfixPerpWeightedSum05Squaredactually has worse lighting than Better Days.
A: Yes, that's true. That's becausebetterDaysIllustriousXL_V01ItercompCyberfixPerpWeightedSum05Squaredis overexposed. Cyberrealistic, and Cyberillustrious too, are realistic models that have been presumably trained from photos that taken with modern digital cameras that have automatic retouching. The model learns from this and when transplanted, just touches up the lack of unmotivated lighting and illumination by ramping up the color grading. The opposite of that is why modern cinematography looks dark as shit and you can't see anything: because they film on a properly lit set but want darkness and shadows so they 'crush the blacks' and then you get the GoT S8E03.Q: Why merge with ΣΙΗ?
A: Well, ΣΙΗ has very good innate artist tags, but also we need to replace the blocks inbetterDaysIllustriousXL_V01ItercompCyberfixPerpWeightedSum05Squaredthat are causing the overexposure. By merging the two together, the resultant model gets the great artist tags and composition of ΣΙΗ, as well as some lighting upgrades, while still being able to do nonmotivated lighting. Model merging is mostly about averaging out the strengths in weaknesses of both models and in this case, in my subjective opinion, the end result gained more than the two models lost.Q: What is QLIP?
A: QLIP is NVIDIA's own tokenizer/autoencoder that is supposed to be good at both understanding images (i.e. visual recogniztion for tags/natural language/etc) and reconstructing them. It can be used as a drop-in replacement for certain models that use CLIP, however given that the CLIP for Noob-AI has been heavily finetuned, the only way to use it here is to apply the differences between the CLIP-G and QLIP to the finetuned NoobAI CLIP.Q: QLIP effects?
A: As far as I can tell it makes the model much more likely to follow the prompt and is an overall improvement over CLIP-G. However because of the fact that is is 'merged' into the finetuned CLIP rather than being the innately trained CLIP damages the associations in latent space somewhat. For most images you will not notice it but when you start trying to prompt more than 3 characters, the QLIP model begins to struggle to a greater degree than the model with the native CLIP. For this reason I have also uploaded the prototype ver without QLIP because although I think it is worse at most prompts, it make better for some people's workflow.Q: Pony?
A: No.Q: Türkçesi?
A: (Please do not actually message me in Turkish, I do not understand it and will have to reply in some broken ass Google Translate pidgin)
(Please do not actually message me in Turkish, I do not understand it and will have to reply in some broken ass Google Translate pidgin)