



Comfy workflow for iterative latent upscale, wildcards, refiner and noise injection [SD1.X]
Type | Workflows |
Stats | 1,938 |
Reviews | (124) |
Published | Sep 5, 2023 |
Base Model | |
Usage Tips | Clip Skip: 2 |
Hash | AutoV2 1E7229A1C6 |


SD1.X is still gold standard for 2D and nsfw pictures. Trying to squeeze most of it and also experimenting with new tools, I devised this workflow to replicate and also automat most of the things I was doing with Voldy's and vladmandic's UIs. This is not a drop in replacement for anything done with any other tool, but more like a very open and experimental way of generating images, with its own advantages and flaws.
After fiddling with comfyUI and this workflow for awhile, I mustered the courage for sharing and hopefully ending up collecting feedback to improve it and the generated pictures.
The workflow
Let's go through each section, step by step, so I can share most of the features I thought were worth adding into the workflow.
Model Loader
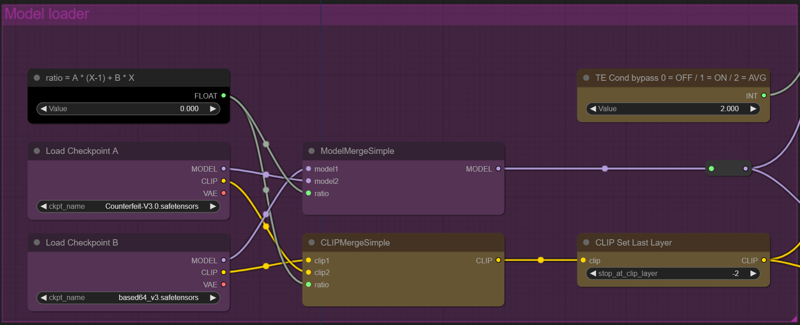
Here we can choose two models, A and B, define a merge ratio for quick drop-in merges and also choose if we are going to use clip skip 2 or not.
After experimenting with futanari, furry and heavily stylized models, I ended up also adding a option to switch between using the prompts parsed by the model + loras/lycos TE, only the base models or merging them together. Quality wise, it seemed to help with prompting for specific stuff like futas and monster girls when the loras/lycos used into the current workflow are interfering negatively with those concepts. Just set it to zero and forget about it if you don't like the results.
Latent configs
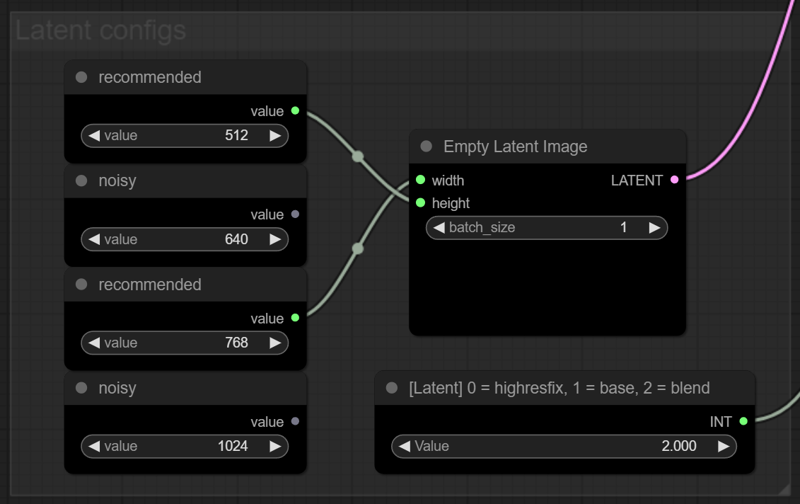
Here you can quick swap between some few resolution presets for the base image latents. There's also a option to use the regular highres fix/t2i second pass with an upscaler model like remacri or ultrasharp before sending the base image to the iterative latent upscaler. Experiment with it and see what result suits you the best. Beware that the blended latent can be quite noisy depending on your base image, but it's not that much of a problem.
Upscaler and Vae
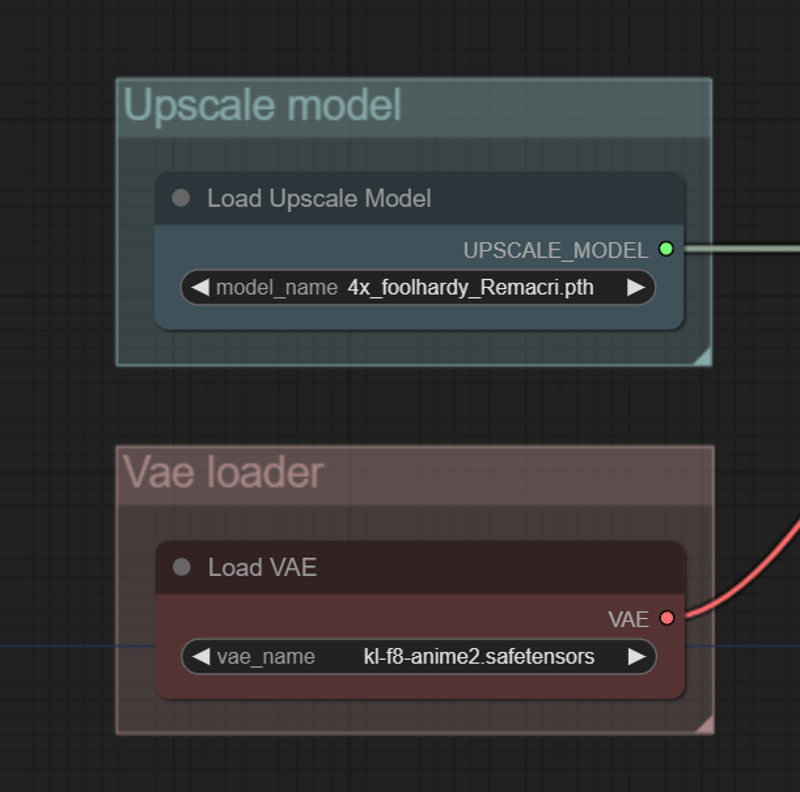
Here you can choose your preferred upscale model and Vae. Both of them will be used through all the generation process.
Add noise controlnets
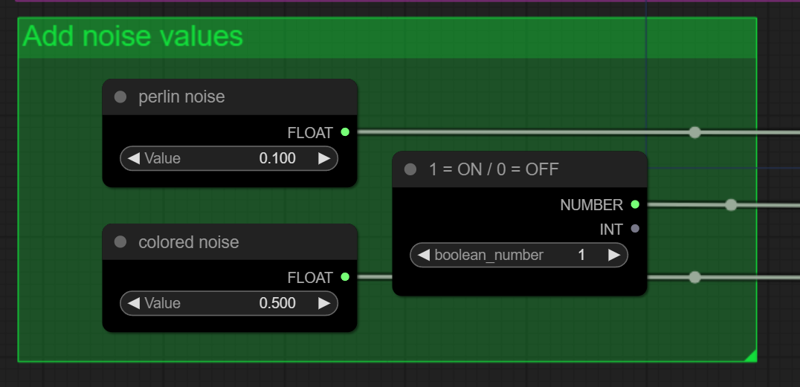
Here you can choose the strength values for the lineart controlnet. Those values will be used to define the strength of the noise that will be added trough the generation process to hopefully increase the details of the image subject and background without relying into loras like Detail Tweaker which could end up influencing your image composition in unintended ways. Some experimentation is needed since each model take this added noise better than others. For instance, you can add a total of 0.6 str noise to Counterfeit without much problem while furry models and Based64 can only take from 0.1 ~ 0.2 before producing nightmarish monstrosities depending of your noise image.
There's also a toggle switch so we don't need increase/decrease the strengths each time we want to turn it on/off.
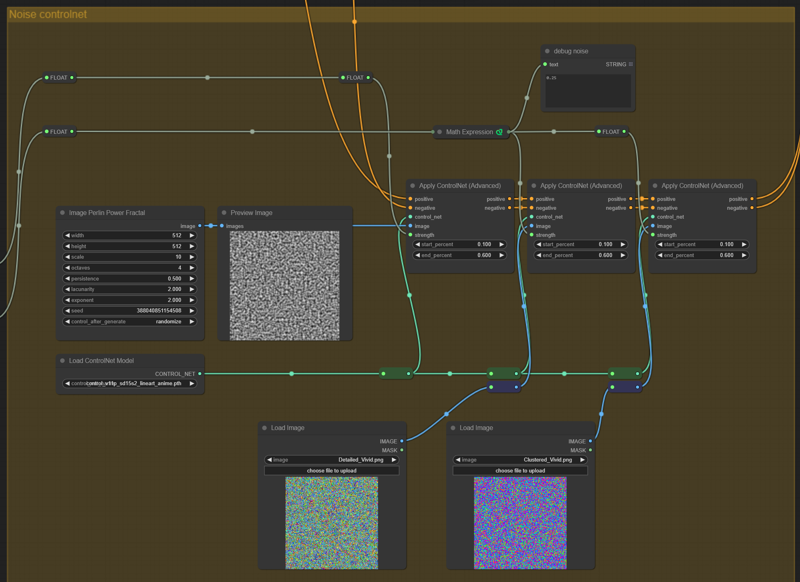
I started using this trick with controlnets after reading this amazing article, which also provided the noise images to use with controlnets in part 2 ("Noises.zip" file)
Lora spaghetti with lycoris meatballs
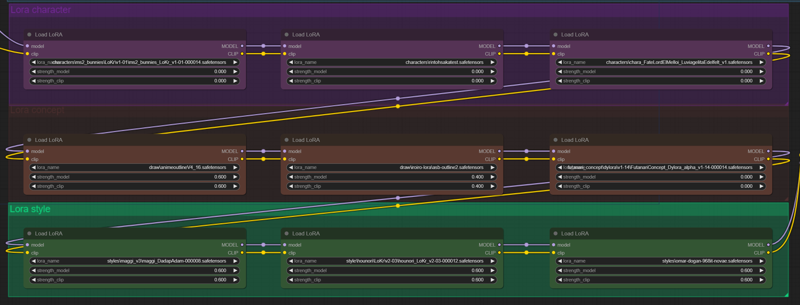
Here all the loras are daisy-chained together to be used in the generation. I segmented the loras into 3 categories, but feel free to ignore or change it according to your needs.
I don't like this implementation at all and would prefer to have a text box to fill in the names and strengths of each lora.
Conditioning
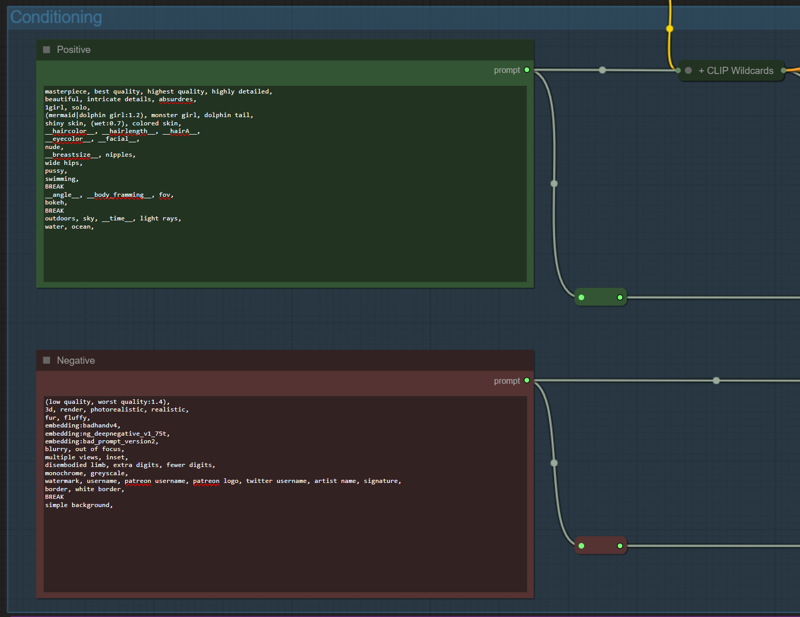
Here we can setup our positive and negative prompts. There's also the option to use wildcards in your prompt. For fixing the problems with refiner/adetailer and upscalers using different wildcard seeds in their prompt, only one seed is used for picking the wildcards and the prompts made with them are shared between each sampler.
Base image
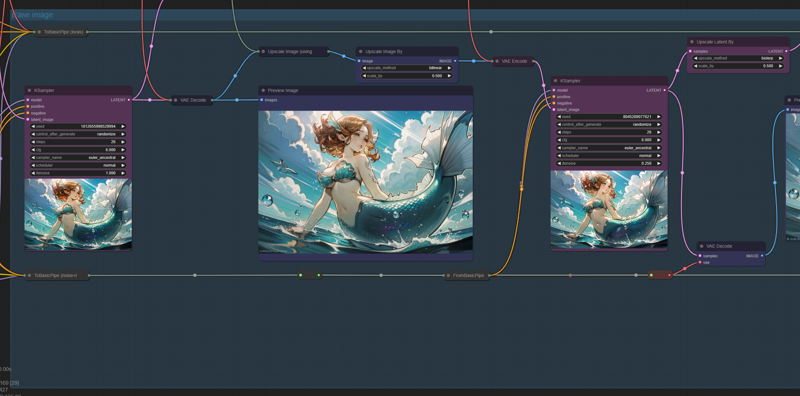
Here we are generating the base image that will be going to be sent to the latent upscaler. You can change here the sampling scheduler and cfg of our base image, but I recommend using the default options if you don't have a clear goal in mind. Here we are also upscaling the base image using highres fix / t2i second pass and then downscaling it back before sending the latents to next step, but it's totally optional and you can toggle it in the "Latents configs" section.

Our image is already taking shape, but I think we can improve it!
Interactive latent upscale
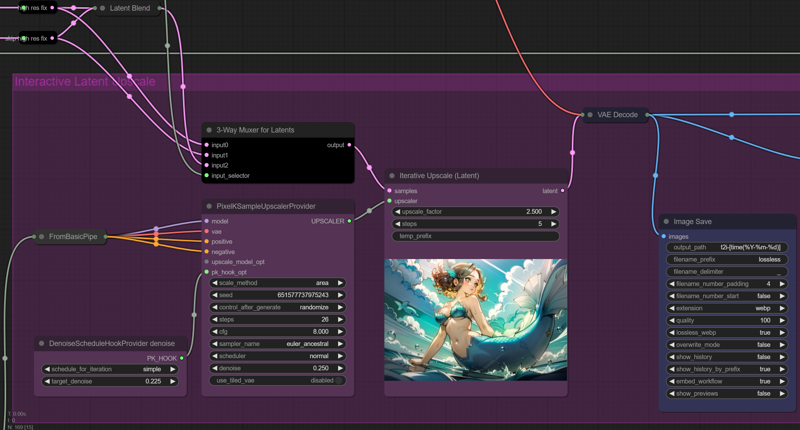
Here we can upscale and bring out more details from or prompts, loras and lycoris. From my experiments, the interactive latent upscale can improve many aspects from our images depending on the denoise, factor and number of upscaling steps. Hands that look like beaten sausages will have a chance to converge into shape once more. The same is also valid for eyes, feet, toes, clothes, background... It can improve your image much further than the GAN upscale, but it can also smother some details like lighting from fireworks, bokeh or even making the image too blurry depending on our tags (for the depth of field and fov enjoyers).
I recommend experimenting with the default values first and then changing it depending on the use case. In some cases, we will need to reduce the number of upscaling steps if we see too much no-sense being added to our image or changing our denoise and target denoise (the scheduler thing at the left of the latent upscaler).
Face detailer
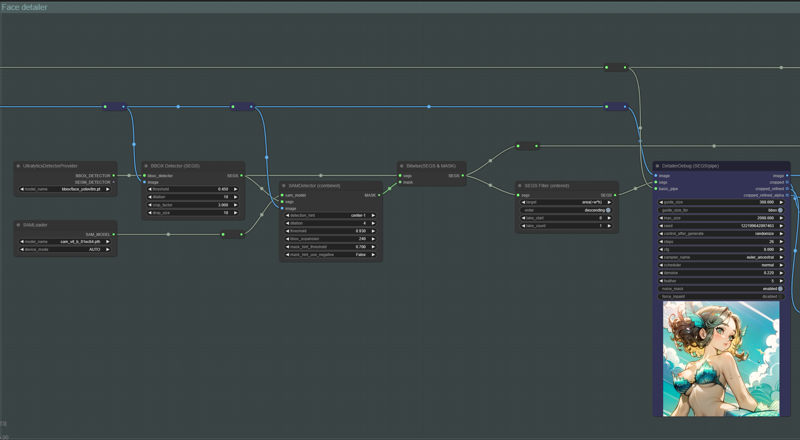
Adetailer is cool, right? I think face detailer can do a similar job at refining the faces from your pictures. In this first segment, we are refining the main subject face by filtering the largest face detected in the image. The prompt, loras and lycoris used for the refinement are the same from the base picture, but from there on we are ditching the add noise controlnets from the previous steps since we don't need more chaos added to our upscaled image.
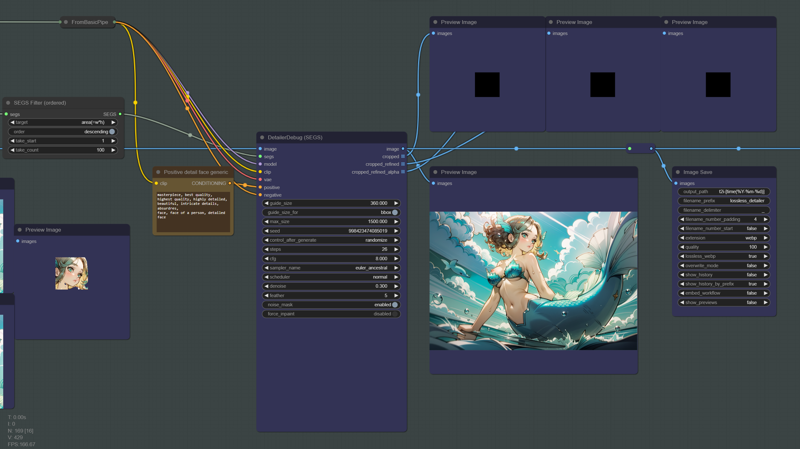
For this segment, we are trying to refine every other face that was found in the picture using a generic prompt that is gender agnostic and should yield pretty good results for secondary and background subjects.
Ultimate SD upscale
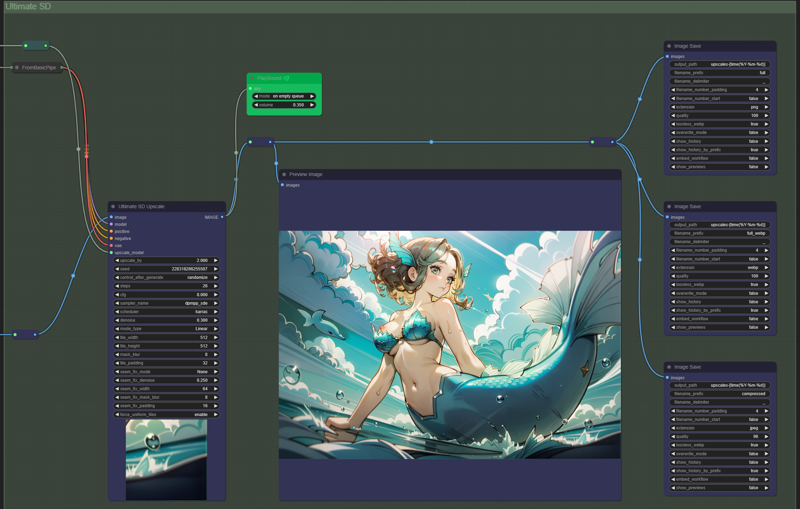
Here we can upscale our image further into titanic proportions and hopefully adding some finer details into our final picture. For a more refined and traditional media looking picture, I like to use dpm sde karras scheduler, but you can change it to something else like Euler A or Unipc if you don't like the style or want something done faster. Since this is a tiled upscaler, we also need to choose a seam fix mode if the final image ends up looking like a chess board, but it really varies from model to model. With Counterfeit, almost all the pictures upscaled with Ultimate SD end up looking really smooth, while based64 and some furry models end up up many seams between each tile. I recommend using the "half tile" method if we're getting seams in our upscaled images.
An important detail about this step is that we are drinking from a different straw when compared to the rest of the workflow. The pipe at the top was setup at the start of the process without any loras, lycoris and controlnets being added to the model. From my experience working with this workflow, it generates less fractal crap and the details end up much better than when upscaling with loras and controlnets on.
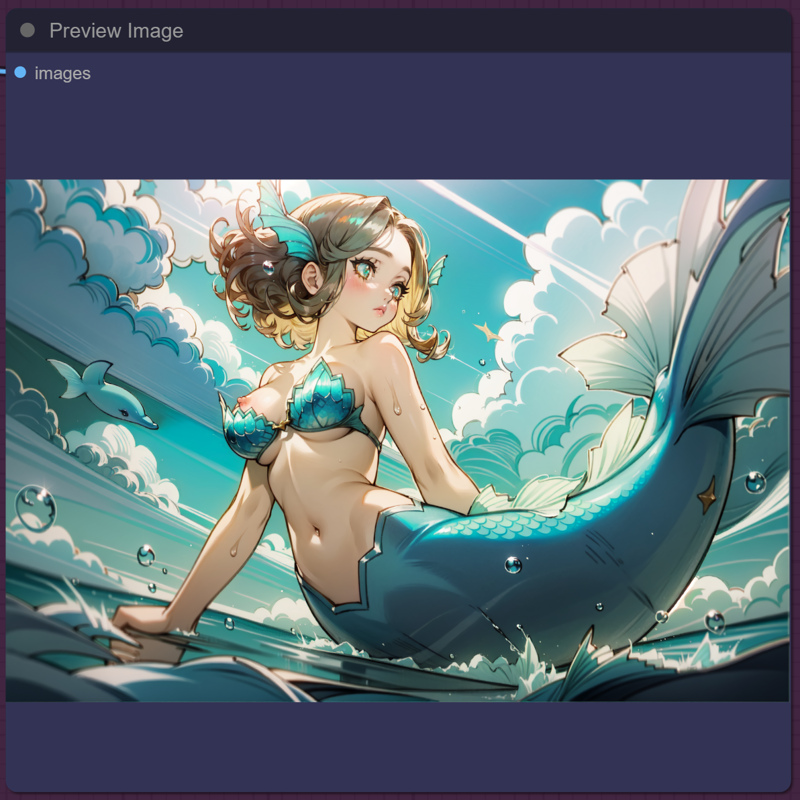
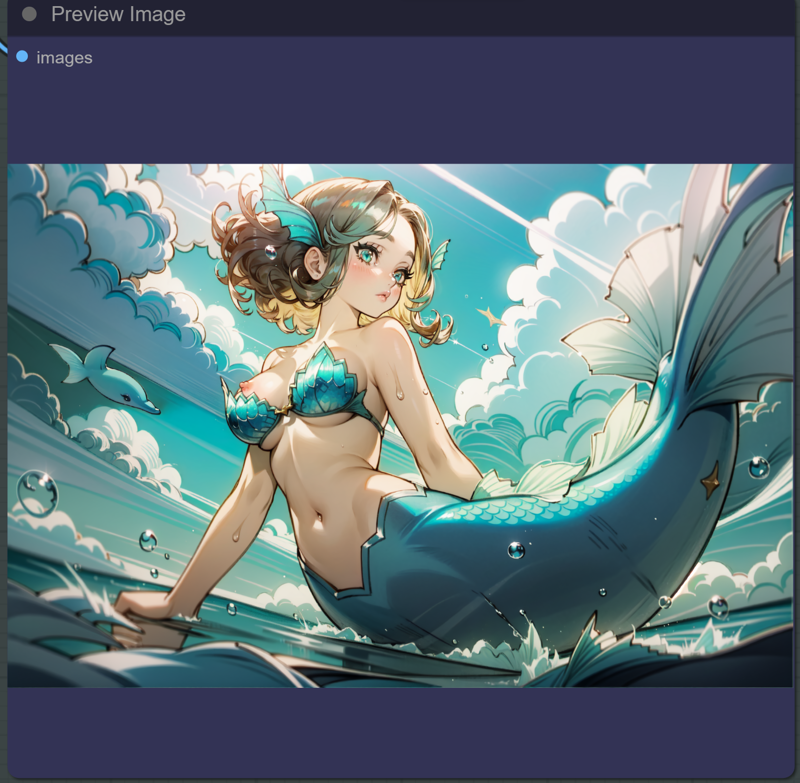
Our final image...


To me, it looks pretty good!
Wake me up when someone ports Tiled Diffusion/Multi Diffusion to comfyUI so we can swap Ultimate SD with it!
Quality of Life
I added an alarm for empty queues and some image conversion and compression methods so we don't need to downscale or save as jpg using other tools for posting in platforms with image size limits. Only the first image save from the workflow will record the generation parameters, so remember using an exif cleaning tool before sharing if you're paranoid like me.
TOME
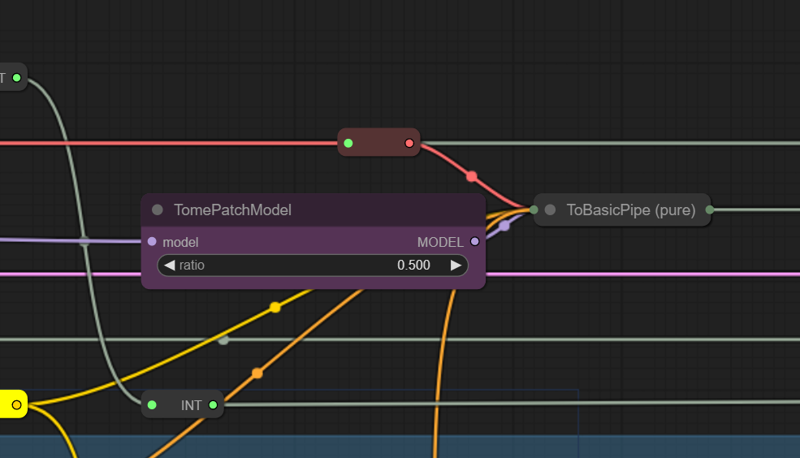
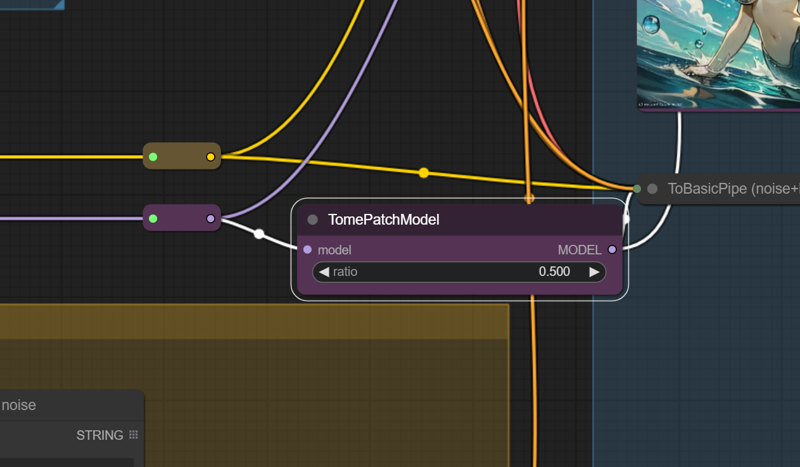
Tome patch is applied in two different places for speeding up the image generation process. If you don't like it at 0.5 and want to change the values, use the "go to" option in the UI to find it on our macaronic workflow
Dependencies
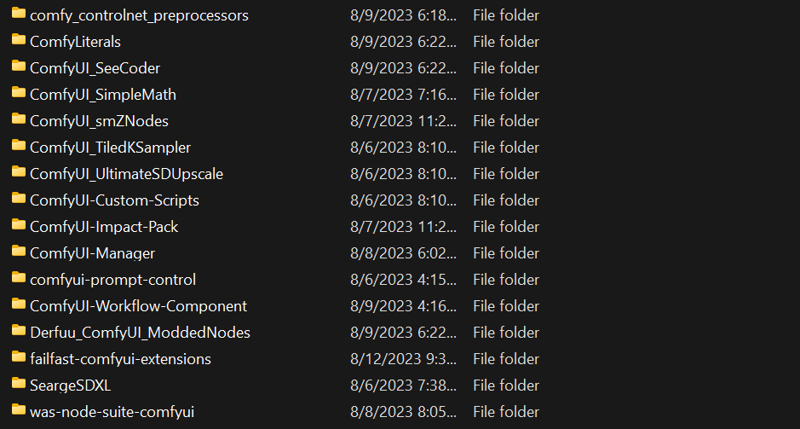
Fuck dude, another point I don't feel comfortable with it. Dependency management for each workflow, at least in my addled smooth brain, feels kinda hard at the time. Since my current environment is already muddied with many custom nodes, you can try your luck and run it and try managing it by reading the error popups from missing nodes.
Here is the list of custom nodes that I'm pretty sure you will need to run the workflow:
ComfyUI-Manager
comfy_controlnet_preprocessors
ComfyUI_SeeCoder
ComfyUI_smZNodes
ComfyUI_TiledKSampler
ComfyUI-Custom-Scripts
ComfyUI-Workflow-Component
ComfyUI_UltimateSDUpscale
ComfyUI-Impact-Pack
failfast-comfyui-extensions
ComfyUI_SimpleMath
Derfuu_ComfyUI_ModdedNodes
SeargeSDXL
was-node-suite-comfyui
ComfyLiterals
comfyui-prompt-control
If you got problems installing MMDET for Impact-Pack, just skip it since this workflow is not using any nodes from it. You can see more about it in the Impact-Pack repo page.
That's it. Feel free to share any kind of feedback! I'm trying to improve this workflow and also the pictures generated with it