Download
2 variants available
fp8 SafeTensor
vision_realistic_flux_dev_fp8_no_clip_v2.safetensors
8-bit, smaller file (pruned) • 11.08 GB
Verified: 2 years ago


The FLUX.1 [dev] Model is licensed by Black Forest Labs. Inc. under the FLUX.1 [dev] Non-Commercial License. Copyright Black Forest Labs. Inc.
IN NO EVENT SHALL BLACK FOREST LABS, INC. BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH USE OF THIS MODEL.
Sponsorship:
For sponsorship, please contact us on Discord. Your support helps us grow and improve future work.
Buy Custom Models:
If you're interested in buying a LoRA model, contact us—we can get it done in a short time.
Vision Realistic Flux dev fp8 Model Overview
I'm excited to share my latest model, Vision Realistic Flux
We all know the original Flux model is already one of the best out there, so further fine-tuning might seem unnecessary—honestly, I thought it could be a waste of time. However, I did notice a few issues, like occasional blurry images that didn’t make sense, and skin tones that weren’t quite right, especially when aiming for realistic results. So, I decided to tackle those problems. While I'm not completely satisfied with every detail, the improvements are definitely noticeable—better handling of NSFW content, brighter images, and far fewer blur issues.
Is this model better than the original Flux?
Not necessarily, but in some cases, like photorealism, it does perform better. Ultimately, it depends on your taste and what you're looking for.
How I Made This Model:
I trained some LoRA models and then merged them with the Flux dev fp8 model. During this process, I made a few optimizations. The model now has CLIP and VAE baked in, so you don’t need to use separate versions.
How to Use This Model:
You can run this model on ComfyUI. I’ve only had time to test it on ComfyUI, so if you try it on something else, I’d love to hear about your experience in the comments.
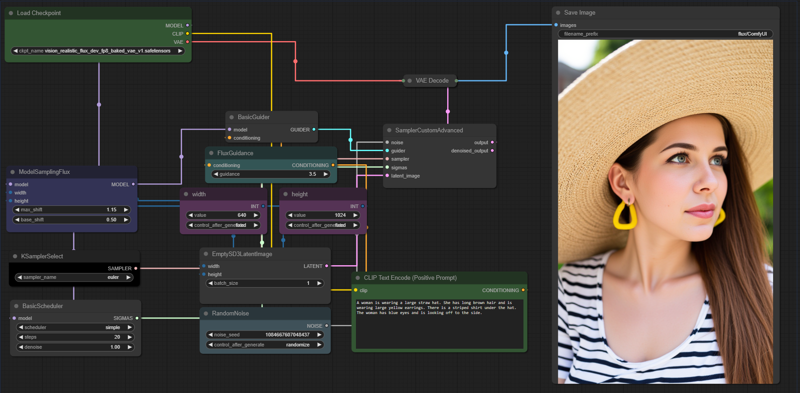
Quick Parameters for ComfyUI:
VAE: Already baked in
Sampler: Euler
Scheduler: Simple
Sampling Steps: 20
CFG Scale: 1
===========================================================
Vision Realistic
I am excited to present my latest Realistic checkpoint model based on SD3M. This model has undergone over 100k+ training steps, ensuring high-quality output.
About This Model:
This is a Photo Realistic model, capable of generating photorealistic images. No trigger words are needed. The model is designed to produce high-detail, high-resolution images that closely mimic real-life photographs.
Configuration Used for Training:
GPU: A6000x2
Dataset: A mix of 5k stock photos and my own dataset
Batch Size: 8
Optimizer: AdamW
Scheduler: Cosine with restarts
Learning Rate (LR): 1e-05
Epoch: Target of 300 epochs
Captioning: WD14 and BLIP mix
Important: Avoid including NSFW-related/mature words in your prompts. Doing so may result in unreliable image outcomes. Also, avoid using too long prompts as smaller prompts work better on SD3.
Quick Guide and Parameters:
Clip Encoder: Not required
VAE: Not required
Sampler: dpmpp_2m
Scheduler: sgm_uniform
Sampling Steps: 25+
CFG Scale: 3+
For better results, try using ComfyUI
If you download the version without CLIP, please follow these guidelines:
This version won't work like a normal SD3M model. You must load the model using 'Load Diffusion Model.'
You can use all SD3M text encoders that come with it.
You need a VAE. Download it and place it in the VAE folder:
ComfyUI\models\vae.Place the model in the UNet folder:
ComfyUI\models\unet.
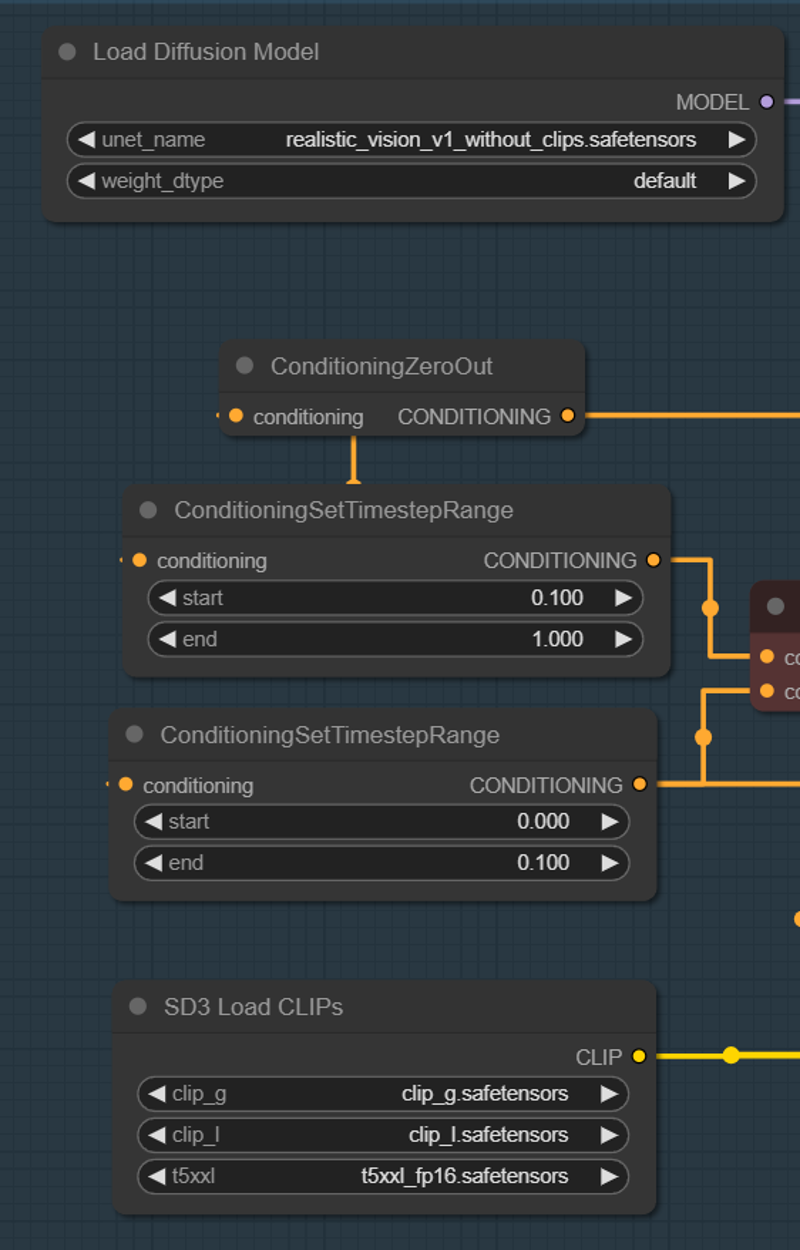
Note:
This is not a merged or modified model. It is the original Realistic Vision fine-tuned model. Some users have been spreading incorrect information in the model's comment section. If you have any questions or want to know more, join my Discord server or share your thoughts in the comment section. Thank you for your time.