Updated: Sep 18, 2024
base modelDownload
1 variant available
fp16 SafeTensor
sanaeXL-anime-v1.3-2400.safetensors
Half precision, best balance (pruned) • 6.46 GB
Verified: 2 years ago

123
386


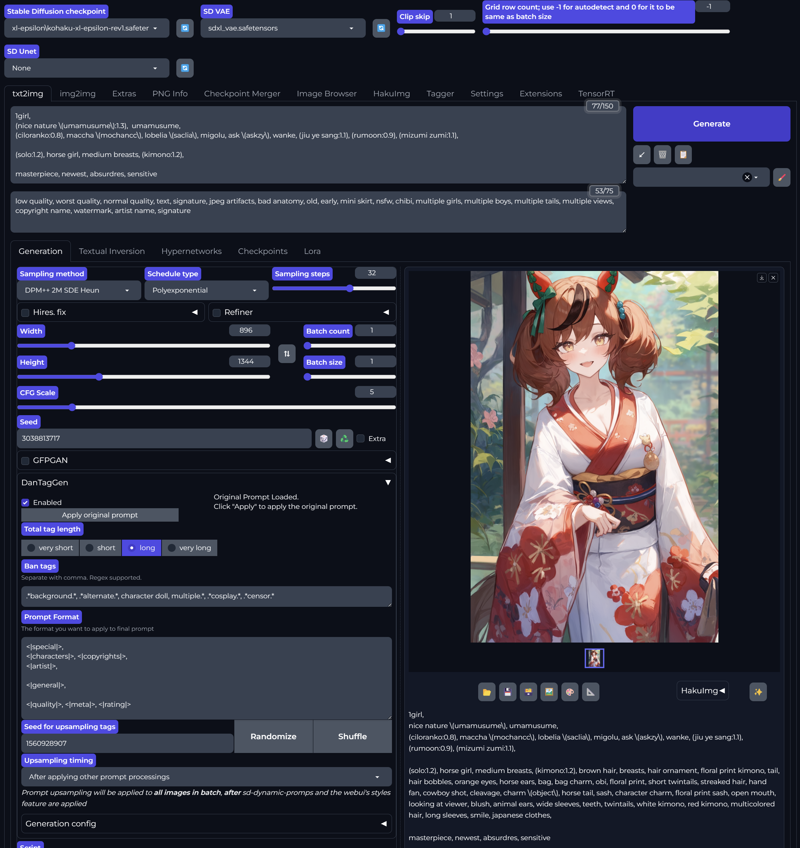
SanaeXL anime V1.0
“苗来承认!苗来允许!苗来背负整个SDXL!!!”
"Make SDXL Great Again!!!"

模型介绍 / Model Introduction
这是一个基于KXL eps rev3改进的图像生成模型,使用了约780万张图像在1张4090上进行训练,极大改善了人物的肢体表现,现在更容易生成准确的人体结构,例如:更好的手指,更好的脚以及脚趾,以及更容易生成准确多人的图像,对于双人拥抱之类的动作均有改善。并且在艺术风格上更加多元,可以像Novel ai V3那样使用artist tag来生成你的喜欢的艺术风格,而且模型也可以生成更多的动漫角色。
This is an image generation model improved upon KXL eps rev3. It was trained on approximately 7.8 million images using a single NVIDIA 4090 GPU, greatly enhancing the representation of human limbs and body structure. Now it's easier to generate accurate human anatomy, such as better fingers, feet, and toes. It also facilitates the creation of precise multi-person images, with improvements in depicting actions like two people embracing.Moreover, the model offers a wider variety of artistic styles. Similar to Novel AI V3, you can use artist tags to generate your preferred art styles. The model is also capable of producing a broader range of anime characters.
版本说明 \ Version Notes:
V1.3: 1.3版本在v1.2的基础上新增了240万张图像用于训练。这次更新重点关注了starry128.txt中列出的艺术风格。starry128.txt是一份精心挑选的artist名单(详细信息请见下方介绍)。通过训练,starry128中的艺术风格得到了显著提升和优化。强烈建议用户下载starry128.txt文档(下载链接已提供),并将其作为wildcard使用,以充分利用更新带来的艺术风格改进。图片标注采用flo2和WD(自然语言+tag),故prompt支持自然语言+tag混合使用。
V1.3: Version 1.3 builds upon v1.2 with an additional 2.4 million images used for training. This update focuses on enhancing the artistic styles listed in starry128.txt, a carefully curated list of artists (see details below). Through targeted training, the artistic styles in starry128 have been significantly improved and refined. We strongly recommend users download the starry128.txt document (download link provided) and use it as a wildcard to fully leverage the artistic style improvements brought by this update. Image annotations use flo2 and WD (natural language + tags), so prompts support a combination of natural language and tags.
v1.2:1.2是在v1.1的基础上额外训练了220万图像的改进版本,增加了更多的角色,例如原神和绝区零;
v1.2: 1.2 is an enhanced iteration built upon v1.1, incorporating an additional 2.2 million images for training. This update introduces a wider range of characters, including those from popular franchises such as Genshin Impact and Zenless Zone Zero.
v1.1:1.1 是在v1.0的基础上额外训练了140万张图像的改进版本,增加了更多的artist。此外,v1.1特别优化了脚部的生成,尤其是脚底的表现。另外我们发现多人画面表现不佳的原因是comic,在negative prompt中添加高权重的comic和multiple views的tag,例如:(comic:1.8),(multiple views:1.4),可以有效改善生成多人画面时的构图错误。
v1.1:1.1 is an improved version built upon v1.0, with an additional 1.4 million images used for training and an expanded range of artists. Furthermore, v1.1 specifically optimizes foot generation, especially the appearance of soles. We also discovered that the poor performance in multi-person scenes was due to comic-style influences. Adding high-weight tags for 'comic' and 'multiple views' in the negative prompt, such as (comic:1.8),(multiple views:1.4), can effectively improve composition errors when generating multi-person scenes.
v1.0 :1.0是我们的初始版本,使用了约780万张图像进行训练。
v1.0:1.0 is our initial release, trained on approximately 7.8 million images.


推荐设置/Recommended settings(please use DTG!!!)
prompt:
<1girl/1boy/1other/...>,
<character>, <series>, <artists>,
<general tags>,
masterpiece,best quality,absurdres,highres,sensitive,newest,
negative prompt (short) :
lowres,low quality, worst quality, normal quality, text, signature, jpeg artifacts, bad anatomy, old, early, multiple views, copyright name, watermark, artist name, signature
negative prompt (long) :
lowres,bad anatomy,blurry,(worst quality:1.8),low quality,hands bad,(normal quality:1.3),bad hands,mutated hands and fingers,extra legs,extra arms,duplicate,cropped,jpeg,artifacts,blurry,multiple view,reference sheet,long body,multiple breasts,mutated,bad anatomy,disfigured,bad proportions,bad feet,ugly,text font ui,missing limb,monochrome,bad anatomy,blurry,(worst quality:1.8),low quality,hands bad,face bad,(normal quality:1.3),bad hands,mutated hands and fingers,extra legs,extra arms,duplicate,cropped,jpeg,artifacts,blurry,multiple view,long body,multiple breasts,mutated,disfigured,bad proportions,duplicate,bad feet,ugly,missing limb,
sampler: Euler A
steps:30
cfg:5~9
upscarler:Latent
Hires steps:25
Denoising strength:0.6
负面提示词必须包含: lowres (由于使用了大量低分辨率图片进行训练)。worst quality 和 low quality 可根据个人需求选择是否添加。也可以使用例图里的负面提示词(long),这串提示词是内部成员测试时使用的的,它非常的“屎山”,我们也无法确认其效果如何,但”it just work.”。
Negative prompts must include: lowres (due to the use of a large number of low-resolution images for training). "worst quality" and "low quality" can be added based on personal preference. You can also use the negative prompts (long) shown in the example images. This string of prompts was used by internal members during testing. It is quite "shitty", and we cannot confirm its effectiveness, but "it just works."
例如要生成一张东风谷早苗的图像,可以使用以下prompt(换行是非必要的):
For example, to generate an image of Sanae Kochiya, you can use the following prompt (line breaks are optional):
1girl,
kochiya sanae, touhou
ask \(askzy\),
solo,green hair, green eyes,
masterpiece,best quality, absurdres,newest,safe,highres
DTG(Danbooru Tag Generator)
在使用Stable Diffusion模型生成角色图像时,由于训练数据和方法的特点,最好能提供角色名字以及角色的特征标签(tag)。如果只提供角色名字而不给出特征标签,模型生成的头发颜色、眼睛颜色等细节可能会不准确,尤其是在角色特征比较复杂的情况下。然而,对于普通用户来说,要补充完善所有必要的特征标签并非易事。
When using Stable Diffusion models to generate character images, due to the characteristics of the training data and methods, it is best to provide the character's name along with their feature tags. If only the character's name is provided without feature tags, details such as hair color and eye color generated by the model may be inaccurate, especially when the character's features are more complex. However, for ordinary users, it is not easy to supplement and complete all the necessary feature tags.
为了解决这一问题,我们强烈推荐使用DTG(Danbooru Tag Generator),它是一个可以在AUTOMATIC1111的WebUI上使用的插件。DTG本质上是一个语言模型(LLM),可以根据输入的角色名自动扩写提示(prompt),补充角色的特征标签以及更多的细节描述。使用DTG可以更好地发挥像SanaeXL这样的高质量模型的性能。
DTG链接:https://github.com/KohakuBlueleaf/z-a1111-sd-webui-dtg
To solve this problem, we strongly recommend using DTG (Danbooru Tag Generator), which is a plugin that can be used on AUTOMATIC1111's WebUI. DTG is essentially a language model (LLM) that can automatically expand prompts based on the input character name, supplementing the character's feature tags and more detailed descriptions. Using DTG can better leverage the performance of high-quality models like SanaeXL.
DTG link: https://github.com/KohakuBlueleaf/z-a1111-sd-webui-dtg
我们建议采用以下格式来构建提示(prompt):
We recommend using the following format to construct prompts:
"1girl/1boy + 角色名 + 系列名 + 动作/场景视角 + 质量词"按照这种格式提供基本的提示信息后,你可以将剩下的工作交给DTG来自动完成。DTG能够根据给定的提示生成额外的相关标签(tag),从而帮助AI模型生成更准确、更具体的图像。
"1girl/1boy + character name + series name + action/scene perspective + quality words"After providing basic prompt information in this format, you can leave the rest of the work to DTG to complete automatically. DTG can generate additional relevant tags based on the given prompts, helping AI models generate more accurate and specific images.
我们有理由推测,NovelAI3内部很可能也采用了类似的机制。在用户提供初始提示后,NovelAI3可能会接入一个标签生成器(tag generator)来自动补充和扩展提示信息,从而实现更好的引导效果。
We have reason to speculate that NovelAI3 internally may also use a similar mechanism. After the user provides the initial prompt, NovelAI3 may connect to a tag generator to automatically supplement and expand the prompt information, achieving better guidance effects.
这种"提示+DTG"的组合方式,使得用户能够以更简洁、更高效的方式控制AI生成图像的内容和风格,无需手动添加大量复杂的标签,极大地提高了使用Stable Diffusion模型进行角色图像生成的便捷性和准确性。
This "prompt + DTG" combination approach allows users to control the content and style of AI-generated images in a more concise and efficient manner, without the need to manually add a large number of complex tags, greatly improving the convenience and accuracy of using Stable Diffusion models for character image generation.
关于artist和character:
因为训练的图片数量非常多,二者的tag有效果的也非常多,尤其是在danbooru上有1000图以上的artist和character,均能取得不错的效果,需要注意的是训练集截止至2024年2月,故模型对近期character的支持不佳。以下是关于artist和character推荐的wildcard的链接:
Because the number of training images is very large, both models have a large number of effective tags, especially artists and characters with over 1,000 images on Danbooru, which can achieve good results. It should be noted that the training set is up to February 2024, so the model's support for recent characters is not ideal. Below are links to recommended wildcards for artists and characters:
基于对模型的CCIP评估,我们提供了一份表现优秀的角色清单供您自取。
请注意,这份清单仅包含我们评估范围内(3711个角色)中表现突出的部分,并未涵盖所有角色。
对于一些较为冷门的角色,您可能需要自行测试其效果。
我们坚持严格评估标准,不会仅仅因为在训练数据集中添加了某个角色的相关数据,就未经评估直接宣称模型支持该角色。
如果采用这种宽松的标准,我们的模型理论上可以宣称支持全角色(>12000),但这显然毫无意义。
Based on our CCIP evaluation of the model, we have provided a list of excellently performing roles for you to choose from.
Please note that this list only includes outstanding performers from within our evaluation scope (3711 roles) and does not cover all roles.
For some less common roles, you may need to test their effectiveness yourself.
We adhere to strict evaluation standards and will not claim that the model supports a role simply because related data for that role was added to the training dataset without proper evaluation.
If we were to adopt such a loose standard, our model could theoretically claim to support all roles (>12000), but this would obviously be meaningless.
character/sanaeXL_v1_character_ccip0.8.xlsx · SanaeLab/SanaeXL-anime-v1.0 at main (huggingface.co)
对于画师清单,目前现状无法进行大规模的评估。
但是对于直接使用,建议可以使用这两份清单,可以直接利用webui的wildcard进行调用。
For the artist list, it is currently not possible to conduct large-scale evaluations.
However, for direct use, it is recommended to use these two lists, which can be directly utilized through the wildcard in the webui.
wildcards/starry_artists_v52_full.txt · SanaeLab/SanaeXL-anime-v1.0 at main (huggingface.co)
wildcards/starry_artists_v52_curated_128.txt · SanaeLab/SanaeXL-anime-v1.0 at main (huggingface.co)
注意:sanaeXL支持的tag并不仅仅局限于上面链接里所提到的。
Note: The tags supported by sanaeXL are not limited to those mentioned in the links above.
关于tag / about tag
模型的使用方法与KXL eps相同,prompt格式如下:
The usage of this model is the same as KXL eps. The prompt format is as follows:
<1girl/1boy/1other/...>,
<character>, <series>, <artists>,
<general tags>,
<quality tags>, <year tags>, <meta tags>, <rating tags>
Rating tags
General: safe
Sensitive: sensitive
Questionable: nsfw
Explicit: nsfw, explicit
2005~2010: old
2011~2014: early
2015~2017: mid
2018~2020: recent
2021~2024: newest
分辨率和采样 / Resolution and Sampling
在1024×1024分辨率上使用webui自带的高分辨率修复(Highres.fix)功能可以更好的发挥sanaeXL的性能,推荐修复倍率为1.2倍至1.5倍之间。
Using the built-in high-resolution fix (Highres.fix) feature of webui at 1024×1024 resolution can better leverage the performance of sanaeXL. The recommended fix ratio is between 1.2 and 1.5 times.
采样器无特殊要求,如果感觉出图效果不理想,可以适当提高采样步数和CFG的值。
我们以Euler A举例,采样步数在20-30之间均可,较高的步数效果会好一些,CFG推荐在7-12之间。
There are no special requirements for samplers. If the output effect is not satisfactory, you can appropriately increase the number of sampling steps and the value of CFG.
Taking Euler A as an example, the number of sampling steps can be between 20-30. A higher number of steps will yield better results. The recommended CFG is between 7-12.
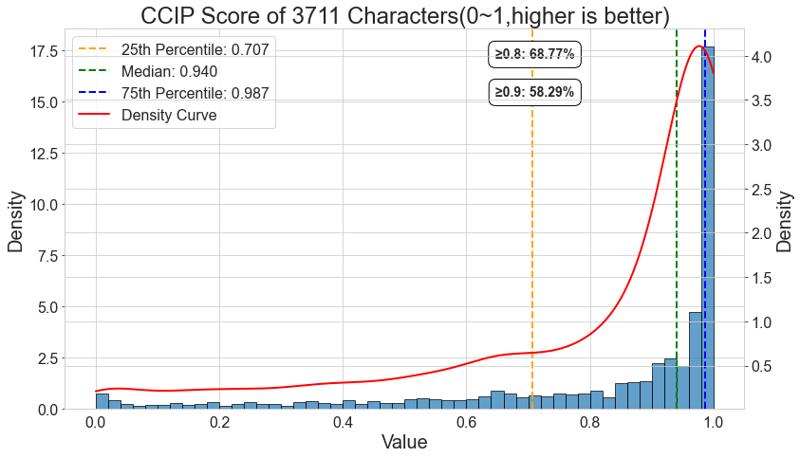
CCIP数据
ccip是一个可以有效评估角色拟合情况的模型。虽然没有单独对角色进行训练,但是得益于有效的训练,模型并没有出现类似于starryXL一样的灾难性遗忘,事实上已经成为写稿时ccip评估上表现最好的模型。68.77%的角色获得了超过0.8的ccip 评分,中位数达到0.94。在这个3711个角色组成的评估集里,绝大部分角色都可以通过prompt组合直接生成。
CCIP is a model that can effectively evaluate character fitting. Although characters were not trained separately, thanks to effective training, the model did not suffer from catastrophic forgetting like starryXL. In fact, it has become the best-performing model in CCIP evaluation at the time of writing. 68.77% of characters obtained a CCIP score above 0.8, with a median of 0.94. In this evaluation set composed of 3,711 characters, the vast majority of characters can be directly generated through prompt combinations.
(具体关于这部分的内容会在日后训练笔记里详细写明)
(Specific details about this part will be elaborated in future training notes.)
笔记链接 / note link:coming soon
关于sanaeXL
SanaeLab:https://huggingface.co/SanaeLab

本模型会持续更新,更新周期大概是一周至半个月。
This model will be continuously updated, with an update cycle of approximately one week to half a month.
后续更新的计划,例如:
● 增加2024年2月份以后的角色
● 更多的artist艺术风格
● 更加良好的手脚
Future update plans include:
● Adding characters released after February 2024
● More artist styles
● Improved rendering of hands and feet

鸣谢 / Acknowledgments:
特别鸣谢KohakuBlueleaf训练的基础模型与deepGHS开源的数据集。
Special thanks to the base model trained by KohakuBlueleaf and the open-source dataset from deepGHS.
Kohaku XL eps rev3 : https://huggingface.co/KBlueLeaf/Kohaku-XL-Epsilon-rev3
Kohaku XL delta : https://huggingface.co/KBlueLeaf/Kohaku-XL-Delta
deepGHS : https://huggingface.co/deepghs
模型发布声明 | Model Release Statement
本模型仅在以下网站正式发布:
Hugging Face: [https://huggingface.co/SanaeLab/SanaeXL-anime-v1.0]
Civitai: [https://civitai.com/models/647664/sanaexl-anime-v10]
重要提示:
除上述平台外,其他任何渠道发布的相关内容均不可信。
未经授权的发布与SanaeLab无关。
我们不对这些未经授权的发布负责,也无法保证其内容的真实性和安全性。
This model is officially released only on the following websites:
Hugging Face: [https://huggingface.co/SanaeLab/SanaeXL-anime-v1.0]
Civitai: [https://civitai.com/models/647664/sanaexl-anime-v10]
Important Notice:
Any related content published on platforms other than those mentioned above is not trustworthy.
Unauthorized publications are not associated with SanaeLab.
We are not responsible for these unauthorized publications and cannot guarantee their authenticity or safety.