Download
1 variant available



这是一个用于生成《剖面手册》风格剖透视图的微调模型,可以在绘制线稿风剖透视图的时候用于提供灵感(其实并没有什么用。。。)
This is a fine-tuned model for generating section-perspective drawings in the style of the Manual of Section. It can provide inspiration when drawinging line-art style section-perspective drawings (although it's useless in fact...).
训练集来源于《剖面手册》(Paul Lewis, Marc Tsurumaki, David J. Lewis. Manual of Section)。
The training set is sourced from Manual of Section (Paul Lewis, Marc Tsurumaki, David J. Lewis).
基于KohakuXL Zeta,用传统lora、loha、lokr三种方法微调。这三种模型各有千秋,供大家自行选择。值得注意的是,传统的lora大小为162MB,loha由于加入了卷积层的训练,为337MB,而lokr由于其巧妙的算法,仅为21.9MB。我会推荐大家使用lokr模型。
The model is based on KohakuXL Zeta and fine-tuned using three methods: conventional LoRA, LoHa, and LoKr. Each has its own strengths, so users can choose accordingly. Notably, the conventional LoRA is 162MB in size; LoHa, due to the inclusion of convolutional layer training, is 337MB; while LoKr, thanks to its clever algorithm, is only 21.9MB. I would recommend using the LoKr model.
使用时,建议使用自然语言提示词,建议用“architecture, a section perspective drawing of a ……”进行描述,以下是一些示例:
When using it, natural language prompts are recommended. Try starting your prompt with "architecture, a section perspective drawing of a…". Here are some examples:
architecture, a section perspective drawing of a house with a roof and a porch area with a table and chairs and a bench, David Chipperfield, archdaily, modernism architecture, a section perspective drawing of a building with a lot of windows and a lot of people walking around it and a lot of windows, David Chipperfield, isometric view, modular constructivismarchitecture, a section perspective drawing of a building with a lot of stairs and a lot of windows on the side of it, Enguerrand Quarton, isometric view, modular constructivism可以配合controlnet,输入自己的剖面线图,使用xinsir的union_promax,使用canny/lineart/anime_lineart/mlsd模式或者hed/pidi/scribble/ted模式,即可做剖面图的风格化,生成《剖面手册》风格的剖面。以下是几个范例(例图用的是我自己的课程设计,献丑了):
You can use ControlNet by inputting your own section line drawings, and use xinsir's union_promax. By applying canny/lineart/anime_lineart/mlsd type or hed/pidi/scribble/ted type, you can stylize your section drawings and generate them in the style of Manual of Section. Below are a few examples (the sample images are from my own course projects, apologies for the imperfections):
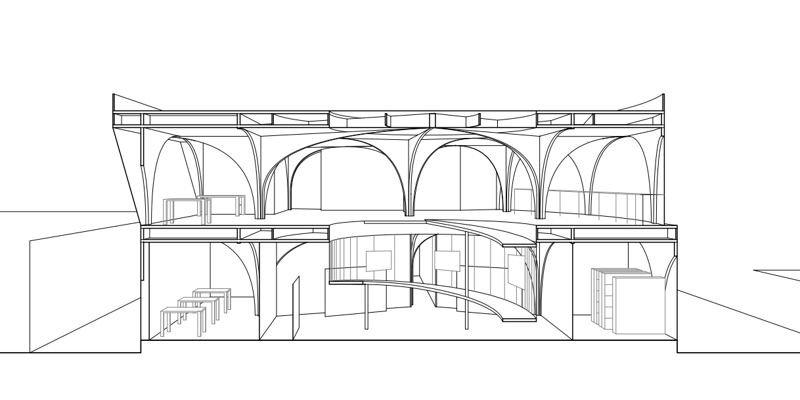
例1 输入controlnet的图片:
Eg1: Input image for ControlNet:
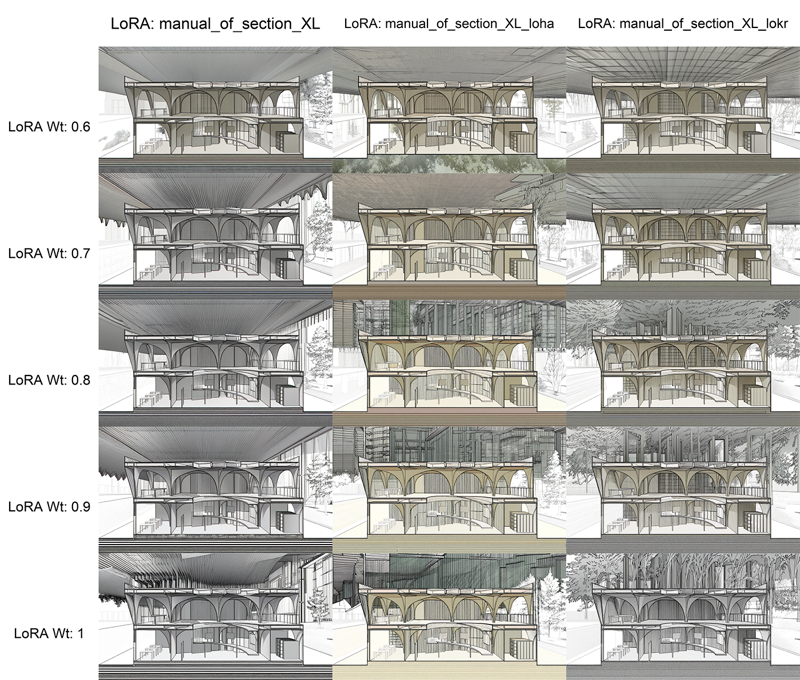
 输出:
输出:
Output:
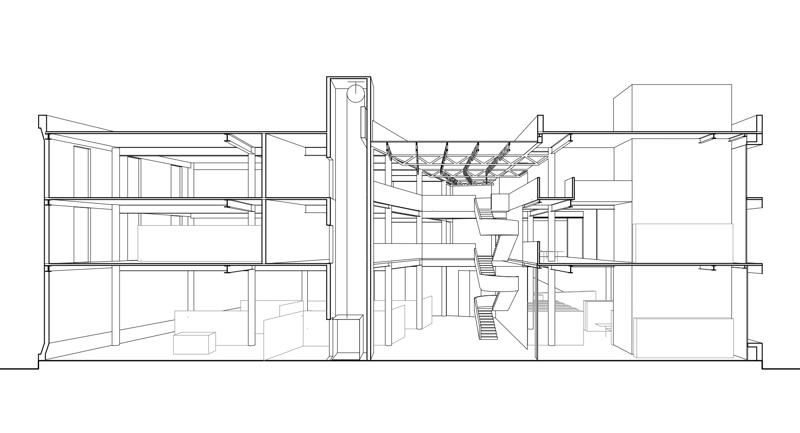
 例2 输入controlnet的图片:
例2 输入controlnet的图片:
Eg2: Input image for ControlNet:
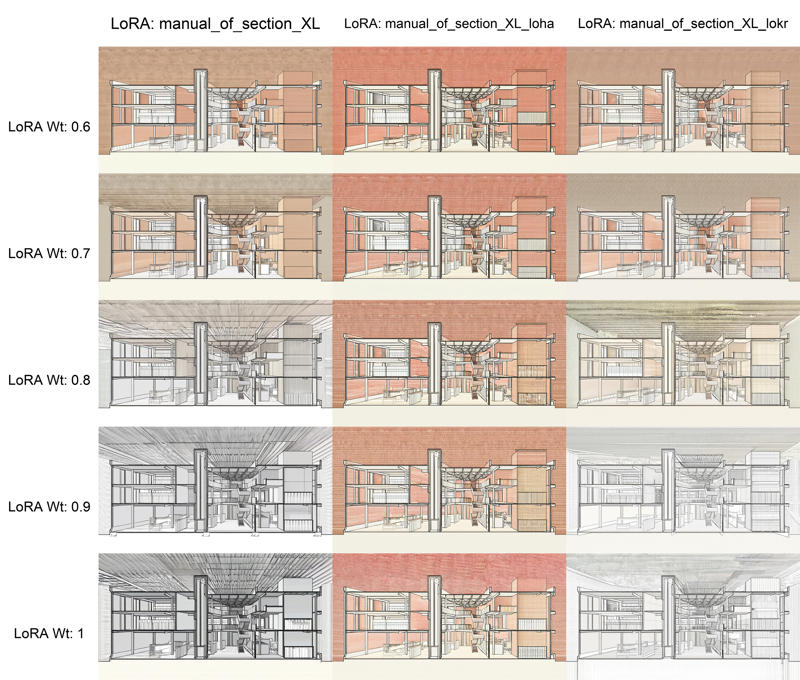
 输出:
输出:
Output:
 例3 输入controlnet的图片:
例3 输入controlnet的图片:
Eg3: Input image for ControlNet:
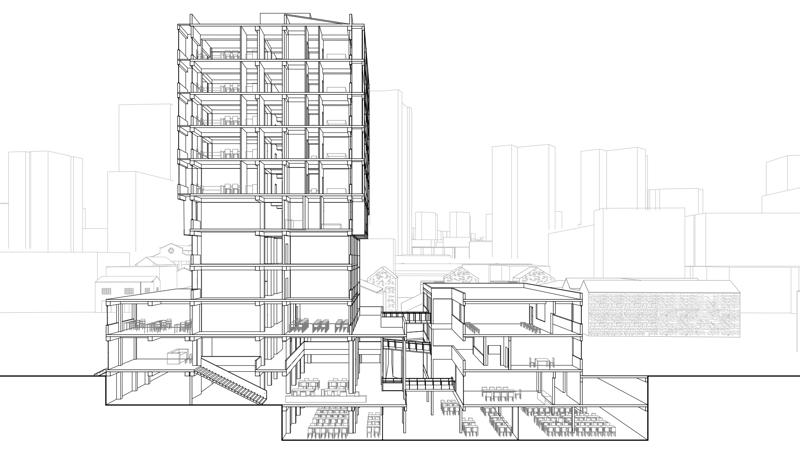 输出:
输出:
Output:

这个模型的缺点是,对提示词不敏感,很难通过提示词生成相应的家具配景。应该是打标的时候没打全的原因,《剖面手册》里的图比较抽象,难以打标。
The shortcoming of this model is its lack of sensitivity to prompts, making it difficult to generate corresponding furnitures and background elements based on the prompts. This is likely due to incomplete labeling during training, as the drawings in the Manual of Section are quite abstract, making labeling challenging.
v2版本更新,共三个模型(Kohaku版、Pony版、Juggernaut版):
v2 update introduces three models (Kohaku Version, Pony Version, Juggernaut Version):
主要的更改是,更新了训练集,用joycaption重新打标,尝试了其他的底模。另外,现在已经不需要触发词了。
The main updates include: Refreshed the training set with JoyCaption relabeling, explored alternative base models, and trigger words are now deprecated.
最推荐使用的是Juggernaut版本。我之前以为,线稿风剖透视的风格更接近二次元风格,因而使用了二次元大模型作底模。但现在看来,写实风格的大模型似乎更适合作底模,很有可能是因为二次元模型被训练地过于风格化了,反而不合适。
The Juggernaut version is currently the most recommended. Initially, I assumed that the line-art sectional perspective style aligned more closely with anime aesthetics, hence using an anime-style base model. However, it now appears that realistic-style base models are better suited for this purpose. This is likely because anime models are overly stylized during training, making them less compatible for this specific application.
注意:这个版本更换了底模,用了juggernaut进行训练。所以生图的时候也要用juggernaut,不能用kohaku了。
Note: This version has switched the base model and was trained using Juggernaut. Therefore, when generating images, you must use Juggernaut instead of Kohaku.
更新了训练集,解决了人物、家具糊成像素点的问题。(现在依然会糊,但是现在是分辨率不足的那种糊,而不是像之前一条连续的线变成一堆离散的像素点那样糊)
总之,可以获取更好的表现了。
Updated the training set to address the issue where people/furniture appeared as pixelated blobs. (Some blurring may still occur, but it now manifests as resolution-dependent softness rather than the previous artifact where continuous lines broke into scattered pixel dots.)
Overall, the model now delivers improved performance.
Kohaku版:
Kohaku Version:
更新了训练集后重新在KohakuXL Zeta上训练,改善了生图效果。不过,实际上它的生图准确性不如juggernaut版那么好。
The training set has been updated and the model was retrained on KohakuXL Zeta, resulting in improved image generation quality. However, in practice, its generartion accuracy isn't as high as the Juggernaut version.
Pony版:
Pony Version:
更新了训练集后重新在PonyXL上训练。此版本生成的图片倾向于方方正正的剖面,准确性较好,但是提示词服从度不好,创造力不如kohaku版和juggernaut版。
The model was retrained on PonyXL with an updated training set. This version tends to produce clean, regular and geometric sections with good accuracy, but exhibits lower prompt adherence and lacks the creative flexibility compared to the Kohaku and Juggernaut versions.