
这里建议先看我的视频版,里面会结合操作讲,更容易理解。
youtube:stable diffusion繫統教學繫列
想每次第一时间收到推送文章,欢迎订阅我的newsletter aigc手记:
开场
今天我们来分享的是,如何在ai领域里伪装成为专业的摄影师,让ai帮你生成的图片比别人多一分高级感,这次我把关于光的提示词做了一遍整理和测试。帮大家把在ai绘画上并不好用的剔除掉,浓缩成接下来给大家分享的案例。相关资源在文后,需要下载的自取。
本次分享内容比较长,肝了不少时间,建议先收藏起来,空出时间再看。
内容分成两部分:
上:如何用简单的光影提示词做出高级感,以例子讲解这些提示词组合后会产生什么神奇的变化。
下:以两种不同的controlnet方式让ai为你做出定制的光影效果,例如最近很火的这种光影字,目前都没人讲明白怎么做,学习者一做就废,根本出不来效果。这次把方法和解题思路都详细讲解给你。之后你就可以依靠自己的创意随意创作,而不需要只是搬运别人的提示词和参数。

1.如何用简单的光影提示词做出高级感
我们先来看下两组参数生成的图片。主要的提示词都很简单 时尚美女参数
fashion photography,a woman,
Negative prompt: disfigured,ugly,bad,immature,3d,painting,b&w,nsfw,Steps: 30, Sampler: Euler a, CFG scale: 7, Seed: 1304648387, Size: 512x768, Model hash: b76cc78ad9, Model: dreamshaper_6BakedVae,
时尚摄影,女人,

神里绫华小姐姐的cos参数,这里用到了AyakaKendo的lora,第一行是lora的触发词。第二行是凌华小姐姐剑道服的一些正向特征提示词。
<lora:AyakaKendo:0.6>,ayaka_KendoUniform,
1 sweet girl,white long hair,ponytail,pink hair ribbon,bangs,white shirt,blue long hakama skirt,upper body,pretty face,
Negative prompt: EasyNegative,((bad-hands-5)),watermark,
Steps: 30, Sampler: Euler a, CFG scale: 7, Seed: 1304648390, Size: 512x768, Model hash: b76cc78ad9, Model: dreamshaper_6BakedVae, Lora hashes: "AyakaKendo: 5288eca02697",
1位甜美女孩,白色长发,马尾辫,粉色发带,刘海,白衬衫,蓝色长袴裙,上半身,漂亮脸蛋,

我没加光效,生成出来的这两张图片,可以看到正面光线是充足的,美感也不错,就是看起来有点乏味,缺少点艺术感。缺少的这种感觉,我们就可以用光之魔法找补回来。
光的方向:
我们先来看看光的方向:back lighting(逆光),front lighting(正面光),oblique light(斜光),side lighting(侧光),semi-backlit(半逆光)
front lighting,oblique light,side lighting,semi-backlit

图片加载中

逆光:能使使主体与背景分离,从而使画面产生立体感、空间感。逆光构图很重要的一条是使画面产生深色背景,否则轮廓线就不醒目。
正面光:开篇的两位就是,常用作把主体照亮,只有正面光,照片会比较平淡。在ai绘图里一般不太会加这个提示词。让他自己发挥吧。
斜光:这是最常用的光位,45度前侧光照射下来,主要作用是使人物富有生气和立体感。
侧光:90度侧方照射,侧光下被拍摄人物呈阴阳效果,是一种富于戏剧性效果的主光位置,它能突出明、暗的强烈对比。
半逆光:来自人物的侧后方,能使人物的一侧产生轮廓线条,特别能突出立体感
我们来小结一下:
加入不同的光源方向后,我们能让人物表达不同的艺术感。像正面光,斜光这种方向一般我们不太需要特别用提示词去提醒ai,让他自己发挥就好。至于侧光,逆光和半逆光,我们则可以根据自己的需求选择。有时候尝试一下,会给到你不小的惊喜。
这里第二组图,我权重开到了1.5倍,效果会更明显,不过也容易脸崩,各位同学玩的时候需要根据模型调整权重。其实直播间给人物和物品打光也是类似的。左前,右前斜光,一主一辅,目的是打亮主体。然后侧后再补一个半逆光把轮廓凸显出来。人看上去就会很立体。如果要播玉石金银之类反光效果好的,就会加一个顶光。对着物品。但顶光千万别直接打在人头上,否则就...

光的效果
接下来我们讲讲复杂一些的光效。由于aigc生成图片光源构成的不稳定性,我们用综合的光效提示词去提示它,更容易出效果。
volumetric(体积光照)
体积光照,主要用于渲染场景氛围。光线照射到遮蔽物体时,在物体透光部分泄露出的光柱来烘托氛围。大家感受一下这两组图片。我就不多说了。


Rim lighting (边缘光)
为拍摄对象增添了明亮的轮廓。但它可能会使拍摄对象变暗,我们用的时候需要注意这点。是不是跟上面光的方向里提到的半逆光很像?没错,他俩都是用来提轮廓的。只是说法不一样,但我总感觉这个提示词比“半逆光”这词,ai理解更深一些。


dimly lit 暗光
添加昏暗的灯光,在街道上衬托效果会更优异。怎样快速把场景切到夜晚啊?方法有很多种,但最简单的方法就是加上一个“暗光”提示词,瞬间搞定。


Crepuscular rays(黄昏光线,神光)增加穿透云层的光线。它可以创造yahaha的视觉效果。非常棒。


sunlight(阳光)
日光是最能还原物品色彩的。想出一些自然背景不妨加入这个词试试。


reflection of light(反射光)
很容易出水面和镜面的反射,效果非常漂亮,不过如果出现大面积的水面反光的话,你的画布分辨率不够,脸部分配分辨率过少就容易坏脸,要做好手动修复脸部的准备。


stunningly long shadows(长阴影)
长阴影可以为照片增添戏剧性和艺术感。用来突出主题或场景的形状和纹理。不过从图片可以看出,这个lora用到这个效果时并不明显。时尚照片会更容易出效果,不过这个效果也慎用,里面的阴影有些是错误的,需要多抽卡。


下面我们来试试几个组合用法:
逆光搭配暗光
<lora:AyakaKendo:0.6>,ayaka_KendoUniform,
1 sweet girl,white long hair,ponytail,pink hair ribbon,bangs,white shirt,blue long hakama skirt,upper body,pretty face,
(back lighting:1.2),(dimly lit:1.3),
逆光搭配光反射
<lora:AyakaKendo:0.6>,ayaka_KendoUniform,
1 sweet girl,white long hair,ponytail,pink hair ribbon,bangs,white shirt,blue long hakama skirt,upper body,pretty face,
(back lighting:1.2),(reflection of light:1.3),

逆光+阳光
<lora:AyakaKendo:0.6>,ayaka_KendoUniform,
1 sweet girl,white long hair,ponytail,pink hair ribbon,bangs,white shirt,blue long hakama skirt,upper body,pretty face,
(back lighting:1.2),(sunlight),
逆光+阳光+反射光
<lora:AyakaKendo:0.6>,ayaka_KendoUniform,
1 sweet girl,white long hair,ponytail,pink hair ribbon,bangs,white shirt,blue long hakama skirt,upper body,pretty face,
(back lighting:1.2),(sunlight),(reflection of light:1.2),

前面提到,逆光最重要的一条就是产生暗色背景,这里搭配阳光和暗光,ai都很聪明的帮我们调配了场景。出来的效果都很出色。 不过值得注意的是,任何光效都要有光源支持,所以我们在提示词上可以加入适合的光源描述来达到更好的效果,比如下面的例子,我们加入街道巷子和路灯,配合暗光和边缘光的提示词,就能出来更有氛围感的夜景照片。
<lora:AyakaKendo:0.6>,ayaka_KendoUniform,
1 sweet girl,white long hair,ponytail,pink hair ribbon,bangs,white shirt,blue long hakama skirt,upper body,pretty face,
street light,streets and alleys,(dimly lit:1.3),Rim lighting,
fashion photography,a woman,upper body,pretty face,
(dimly lit:1.3),Rim lighting,street light,streets and alleys

有时候ai也会给你哭笑不得的结果我在听歌神的《望月》
狼在叫 雪正飘 月似镜子天上照 路正长 酒樽摇 任那孤单心里烧
想将这两句歌词表达一下。看看诗意一些的表达他能不能get到。我让我训练后的chatgpt帮我优化成了下面的提示词^ ^
((best quality)),((masterpiece)),(detailed),(realistic),(howling wolf),poetic imagery,winter night,snowfall,moon as a mirror,reflecting in the sky,breakwinding road,solitary traveler,bottle of wine,swaying in hand,introspective mood,crackling fire,flickering shadows,emotions of solitude,burning in the heart,melancholic atmosphere,(dimly lit:1.3),Rim lighting,
(最佳质量),(杰作),详细,逼真,(嚎叫的狼),诗意的意象,冬夜,飘雪,月亮如镜,映照在天空中,break蜿蜒的道路,孤独的旅行者,手中摇晃着一瓶酒,内省的情绪,噼啪作响的火焰,摇曳的阴影,孤独的情感,在心中燃烧,忧郁的氛围,暗光,边缘光

结果还"真"给我把气氛烘托到位了。至于主体嘛,红裙子的狼人,真行。所以遇到复杂的场景表现,ai是不容易画好的,或许分区描绘在一定程度能解决,不过意境可能又会分离。这个有经验后再给大家分享。
关于有用的提示词光照效果就到这里,下面是小提示:
如果看不到效果,请增加提示词的权重。
这些光魔法提示词并不总有效。建议使用时多抽卡。
部分模型光影效果不好,跟模型训练有关系,尤其是专属的动漫模型。
任何光效果,都需要有光源,加入光源物体的提示词效果会更好。
进阶魔法:控光+光影字艺术
除了提示词告诉AI你要什么光之外,还有两种controlnet方法分别做到用光束图精准控光。下面我们来详细讲讲怎么应用。
场景1:在生图前就准备控制光源
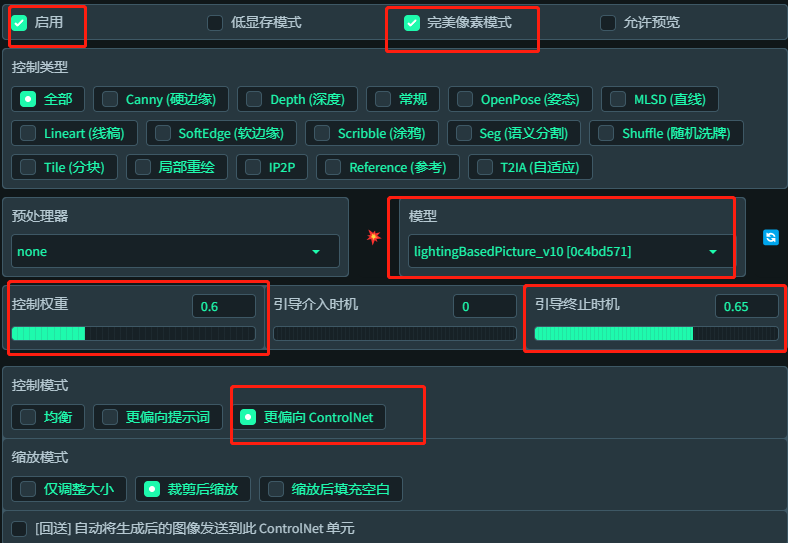
用controlnet 新出的光模型Lighting based picture control 可以实现,路径放在\extensions\sd-webui-controlnet\models,作者Isle_of_Chaos,很牛,国人之光。很想认识下,有认识的可以引荐下给我。不过这个模型还没完全做完,预处理器还没做,但不影响使用。期待后面的优化。
做光影字,使写的字和图片融为一体。
我们先来说光影字。我们以两个案例来讲,鉴赏完图片后我会讲解如何实现。
一,风景
landscape,a monk in front of candijateng at dawn,epic,fog,temple stone,ornament,ornate,details,forest,mountain,<lora:ARWCandiJateng:1>,
Negative prompt: EasyNegative,watermark, Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 3013263059, Size: 512x768, Model hash: ed989d673d, Model: dreamshaper_7, Clip skip: 2, ControlNet 0: "preprocessor: none, model: lightingBasedPicture_v10 [0c4bd571], weight: 0.6, starting/ending: (0, 0.75), resize mode: Crop and Resize, pixel perfect: False, control mode: Balanced, preprocessor params: (-1, -1, -1)", Lora hashes: "ARWCandiJateng: 7f2308d602ed",
风景,黎明时分 candijateng 前面的一个僧侣,史诗,雾,寺庙石头,装饰,华丽,细节,森林,山。注:candijateng是这个lora的触发词


我们先看两张风景,一个是近景,一个是远景,分别表现一实一虚。近景以硬光打在同一个建筑上。所以字体间会比较接近。远景,一天一地,虚实结合,两个字之间距离会放得很远。这两张图用的其实是同一套提示词,只是模型不一样,用的字体图位置不一样。大家可以自己再发散到城市等场景。风景是比较好做的,因为元素多,ai推理起来更容易找到巧妙的结合,云,山,空气,景物,道路,绿植,高楼,灯光等都可以为他组合。而且展示出来的巧妙让你叹为观止。

二,人物
一般我们画人物都是用半身画,因为SD画全身人像,头容易崩,原理也不复杂,就是你画布的分辨率不大,画全身的话,分给头部的像素太少,ai画不了那么细,所以就崩了。而半身作画,要在他们身上写字,局限范围就比较多了。所以在人物上,要写光影字,就需要对光源位置做到精准控制,比如结合光束图,这里先不展开。而ai所能用到的方式无非是以光影,衣服皱褶+光影或者配饰+衣服图案+光影,当然也可以结合景物,只要你给的画布足够大。在人物上,同样有虚实两种方式,虚的就是通过柔光照射出来的光影呈现。实的就是通过纹路或者图案直接呈现。他们的效果各有利弊,大家可以自己动手尝试去感悟。方法也不难只需要控制好两个参数就能实现。以下是图鉴,自己看咯。提示词不长,可以仔细看看,正向提示词(绿色)除开效果词,真正描述词就那么几个。非常好理解。
<lora:kenshinRK10:0.8> kenshin rk,<lora:flat2:-0.5>,<lora:LowRa:0.3>,absurdres,(best quality),(masterpiece),(ultra-detailed:1.2),photorealistic,ultra high res,upper body,1boy,japanese style,Alley,,long hair,ponytail,kimono,japanese clothes,scar,holding katana,silhouette,moon,(night:1.1),(blood splatter:1.1),blood on body,(light and shadow:1.5),dark theme
Negative prompt: negative_hand-neg,(worst quality:2),(blush:1.3),nsfw,flower, Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 518868466, Size: 512x768, Model hash: 364a13041d, Model: breakdomain_M2150, Clip skip: 2, ControlNet 0: "preprocessor: none, model: lightingBasedPicture_v10 [0c4bd571], weight: 0.55, starting/ending: (0, 0.75), resize mode: Crop and Resize, pixel perfect: False, control mode: Balanced, preprocessor params: (-1, -1, -1)", Lora hashes: "kenshinRK10: cdb32621d2aa, flat2: 80f764dfb478, LowRa: 0dfc93870ba3",
(最佳质量),(杰作),(超详细:1.2),照片般逼真,超高分辨率,上半身,1位男孩,日本风格,小巷,长发,马尾辫,和服,日本服饰,疤痕,握着武士刀,月亮,(夜晚:1.1),(血迹喷溅:1.1),身上有血迹,(光与影:1.5),黑暗主题。


给图片打上精准光束
这次我们以狼/月为主题运用前面学习的光影提示词,和光束图配合,看看能出来什么效果。
((best quality)),((masterpiece)),(detailed:1.1),(realistic),wolf,moonlit night,howling,wild creature,primal instincts,haunting melody,midnight forest,silver moonbeams,fierce expression,lupine silhouette,mystic atmosphere,ethereal glow,nature's symphony,shivers down the spine,
Negative prompt: EasyNegative,((bad-hands-5)),watermark, Steps: 30, Sampler: Euler a, CFG scale: 7, Seed: 1423243214, Size: 512x768, Model hash: 4199bcdd14, Model: revAnimated_v122, Clip skip: 2, ControlNet 0: "preprocessor: none, model: lightingBasedPicture_v10 [0c4bd571], weight: 0.6, starting/ending: (0, 0.65), resize mode: Crop and Resize, pixel perfect: True, control mode: ControlNet is more important, preprocessor params: (-1, -1, -1)",
((最佳质量)),((杰作)),(详细:1.1),(逼真),狼,月光下的夜晚,嚎叫,野生生物,原始本能,令人不安的旋律,午夜森林,银色月光,凶猛表情,狼形轮廓,神秘氛围,超凡光芒,大自然的交响乐,使人毛骨悚然的颤栗,


(reflection of light:1.3),(volumetric:1.5), 反射光,体积光


(Crepuscular rays:1.3),(volumetric:1.5),神光,体积光
volumetric体积光在烘托氛围感上是很好的,加上固定光源发挥的效果,以及Crepuscular rays(神光)的烘托效果就立体了。reflection of light(反射光)把水面引出来,倒影搭配月球的奇幻色彩,神秘感就相当可以。


(Crepuscular rays:1.3),Rim lighting,神光配合这张光源图契合度就很高,狼威武的向天宣泄,用边缘光突出主体。感受力量的呼应。


(dimly lit:1.3),Rim lighting,用底部光光源图希望从下往上打光体现威严感,添加了暗光和边缘光突出主体和力量,上1,上2都生成得很好。上1壮硕的狼身,上2有面见狼神的感觉。这两张都是AI给我们的惊喜。
工作流:
这里建议先看我的视频版,里面会结合操作讲,更容易理解。
youtube:https://www.youtube.com/watch?v=LGrD_jW7xHY&list=PLre94Fo0ReBLL54JspYADLT30ACQCHRnU
b站:https://www.bilibili.com/video/BV1Lj411R7ue/?spm_id_from=333.999.0.0
光束图工作流(也是通用工作流)
文生图填好其他参数和提示词后
下载controlnet新光影模型:Lighting based picture control 模型放入\extensions\sd-webui-controlnet\models
打开controlnet,
放入光束图(注意:光束图一定要黑白的)
调整参数,选择模型 lighting based picture 预处理器不用选择
控制权重(就是引导图会对原图影响多大,数字越大融合得就越生硬)建议0.4-0.6之间,0.6我用的最多,如果0.6无效,可以到0.9,只是越高可能越容易出现不好的结果。
引导终止时机(就是迭代到多少步后controlnet不再控制,这里0.65就是65%),建议在0.5-0.8之间。这个值越接近1,说明留给ai融合的步数越少。也就是越生硬(变成直接叠光影图上去)
生成
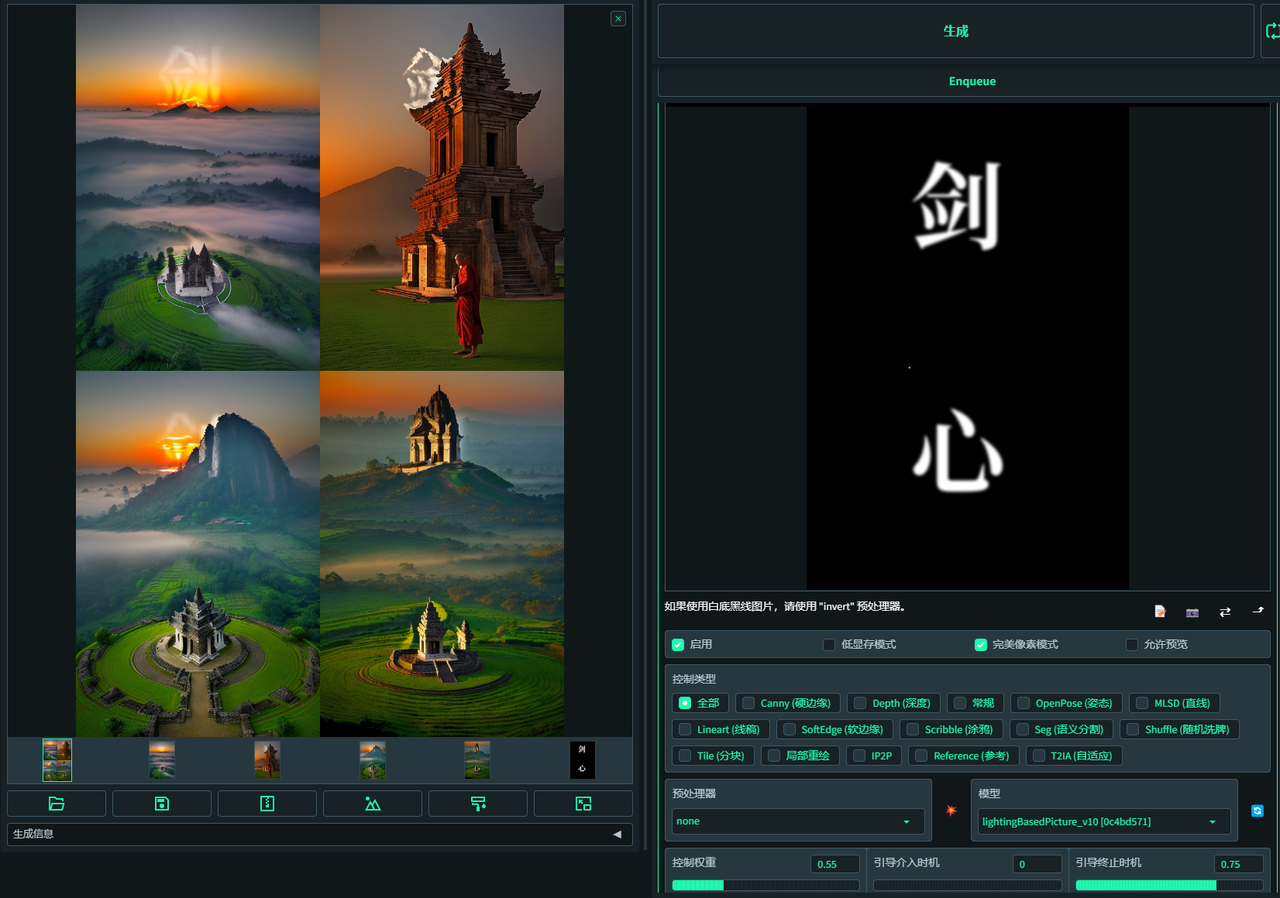
光影字工作流:(补充一些注意点)
先正常生成图,用默认20步迭代步数跑(测试起来快,性价比高。默认就是这个值)
选定一张需要加光影的图,记住seed
查看这张图的光源和高亮的地方。
通过ps或者你熟悉的p图工具(figma,canva,美图秀秀,甚至word 都可以,只要你确信你用word能控制好文字的位置。)做一张黑底白字的图,有高斯模糊的话可以给字加个高斯模糊,这样出光的效果会好一些。有图层信息的软件可以把选定的图放在做背景参照位置,把字的大小和位置尽量按照高光和光源方向设计摆放。这点也是决定你成败的关键步骤之一。原则是,字体大小不要太小(太小会被忽略),文字不要过多(2-3个字为宜),位置要有美感并且尽量放在高光和光源路上,尽量不要挡脸。
保持选定图的提示词和参数,seed改成你选的图的seed
把文字图放入controlnet,同上边光速的通用流程
认真听,考点来了。控制权重:根据字显现情况调整。如果太实就降低数值(每次0.05的降),如果太虚就加大数值,啥都看不到也是加大数值。一般这里在0.5-0.7之间是用得较多的。 引导终止时机:0.75是我用得最多的。我一般会固定引导终止时机这个变量,来调整控制权重,这样容易找问题。一般0.6-0.75之间。这个值越大越生硬,取一个平衡值最重要。这里找数值比较快速的方法就是用xyz脚本跑网格图。视频版里会讲。这里不啰嗦。类似这样的图
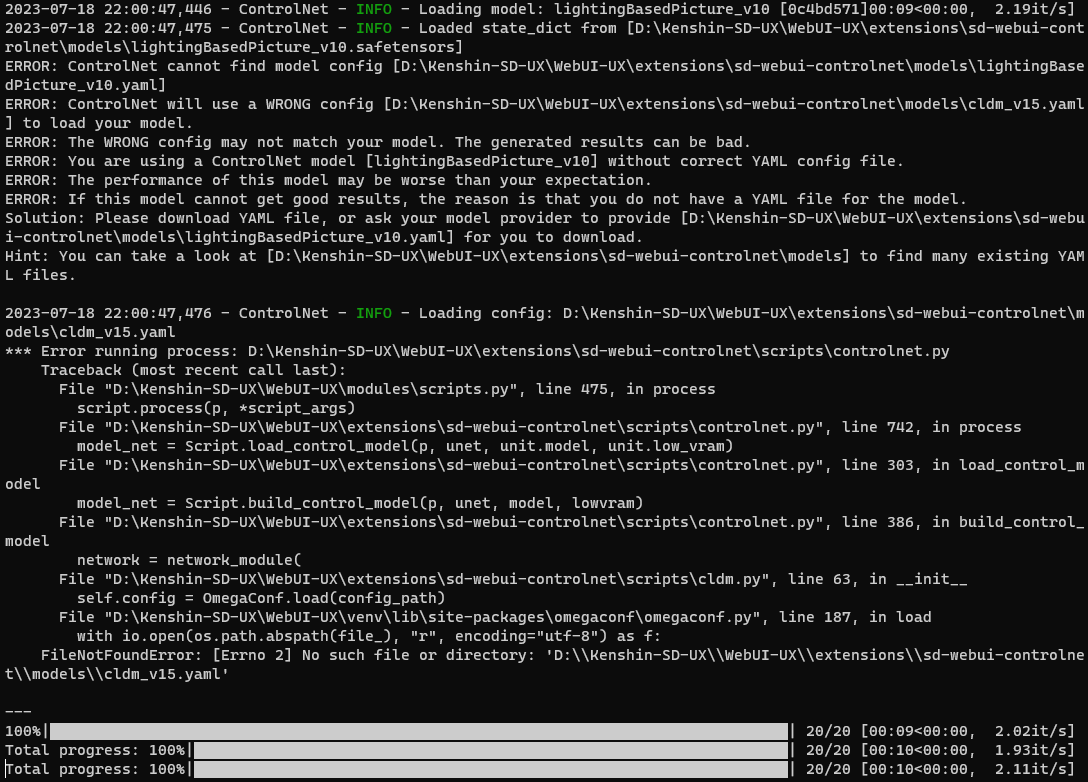
lighting based picture这个模型还没做预处理器,所以controlnet会报错并提醒你下载预处理器(在控制台,不在webui),你不理会,他会继续执行帮你做图。如果在做光束图那没有太大关系,效果还是能出来的。如果是做光影字,在这个过程他会先帮你用cldm_v15.yaml 这个预处理文件载入解决,如果你没有这个文件,就会彻底垫图失效,导致光影字的图无效。这也是很多新手不看控制台报错,以为自己没理解怎么操作,一直学不会的主要原因之一。这个问题怎么解决呢?我们先啰嗦几句,其实这个文件是远古1.0的文件,在1.1的模型库里你是下不到的,导致很多人不是从1.0过来的,会没有这个文件。你可以到这里下载。下载后放入\extensions\sd-webui-controlnet\models 如果你下载了这个文件还报错,那就复制一份这个文件,把文件名改成和你下的模型名字一样,lightingBasedPicture_v10。
学废的同学可以把你的创意图发我邮箱 [email protected] 我会在下期周刊里放出。

(XYZ网格图)
(报错图)
场景2:已有图添加光源
这种场景是,你已经生成了一张图片,但不满意灯光,可以将这张图推送到图生图。做光源补充。不过这种方法的弊端是,会有些小细节被修改。毕竟是重绘。需要自己抽抽卡,不过控光是很精准。下面是对比图,大家先感受下。

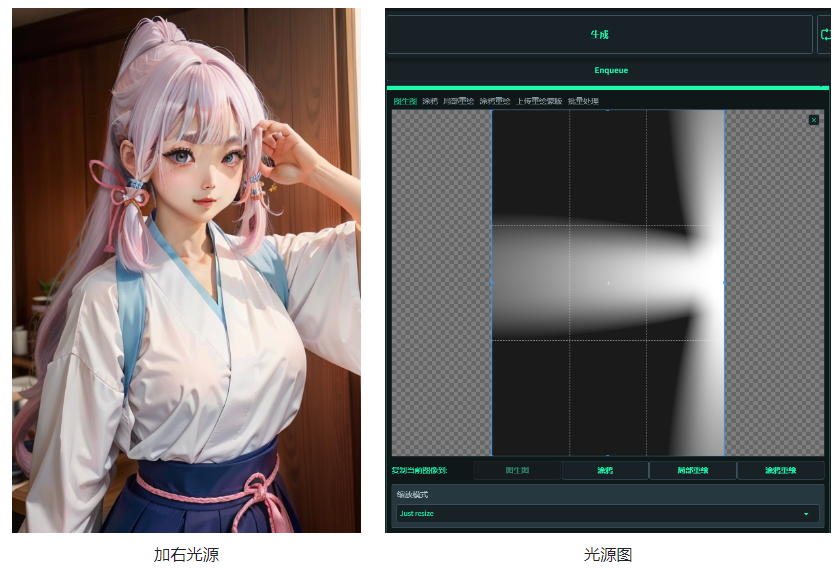
接下来我们来讲讲怎么实现的
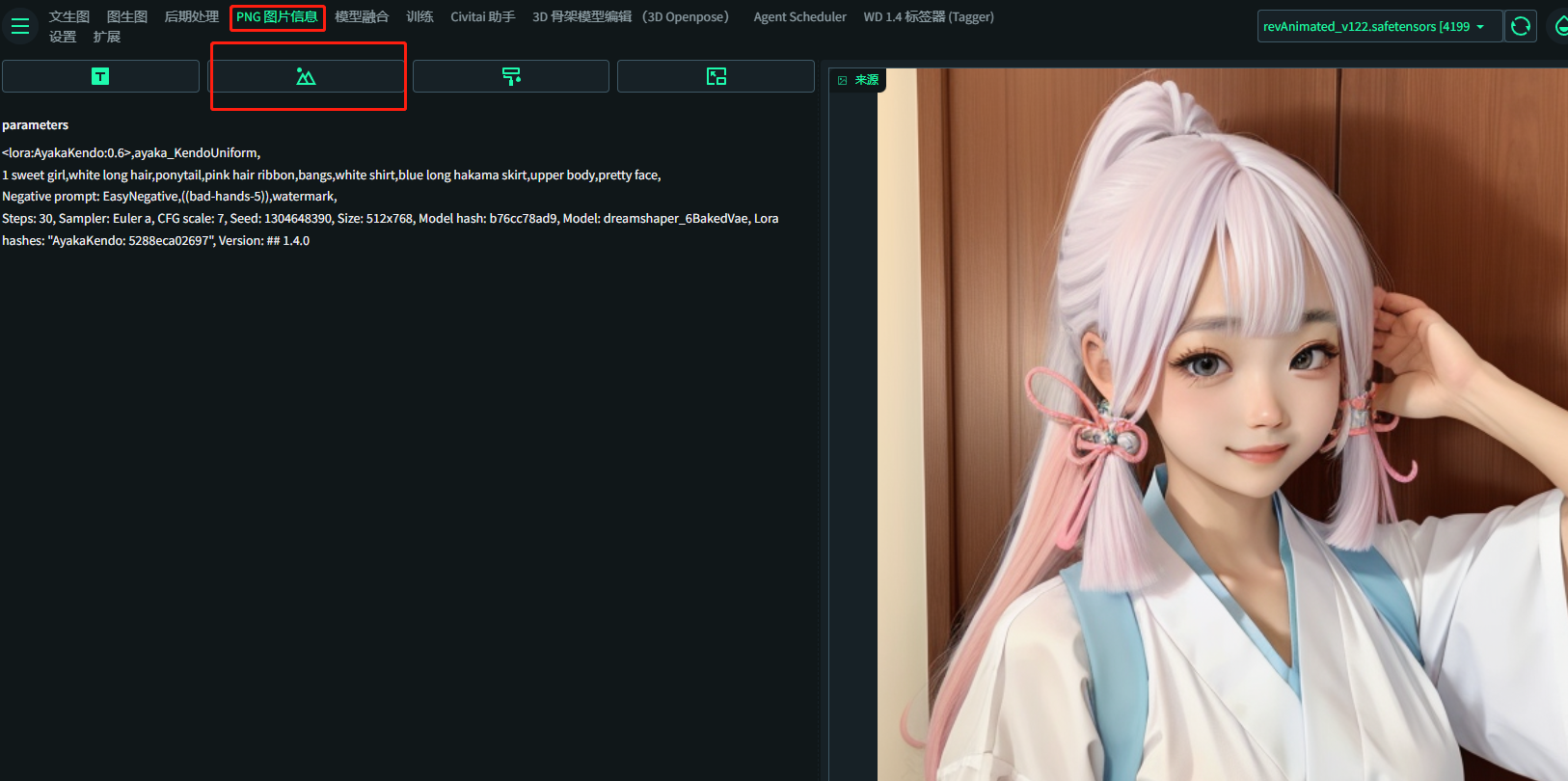
正常用文生图生成图片->
点击发送图到图生图,把提示词和参数全部带过去。
或,以前生成的带有png信息的图拖动到png图片信息里
点击发送图到图生图
图生图里
x掉刚发送过来的图,传光束图上去
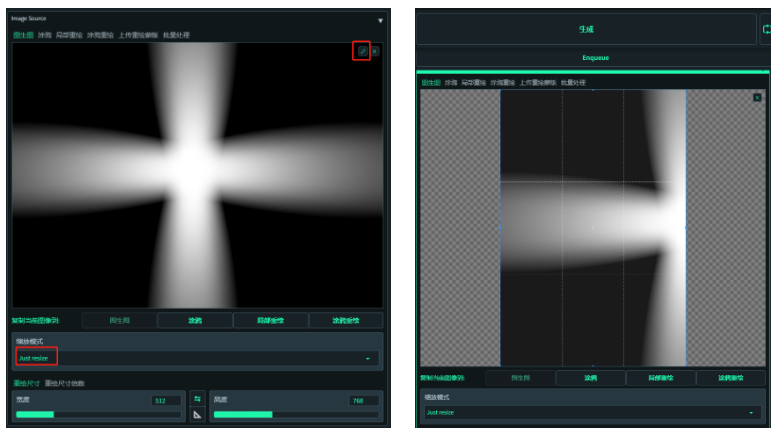
如果光源有多余部分,可以点击“笔”图标编辑,注意:这里裁剪需要重复多一次动作才能拖动成功,应该是SD的bug。
缩放模式选择仅调整大小
重绘幅度:0.95
打开controlnet,传想打光的图上去。
红色框是需要修改的地方,其他默认
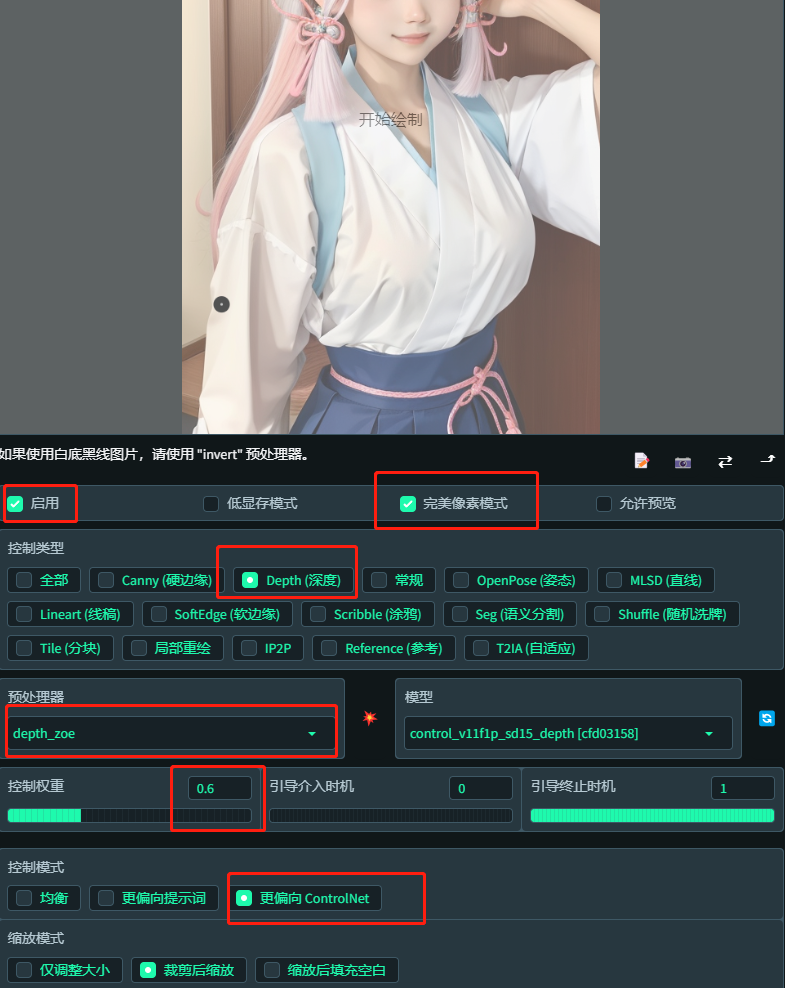
点击生成。
其实步骤很简单,关键在于你要根据自己想法选择到合适的光束图,文后我会提供我用过的光束图打包。
光束图获取途径:
你的设计师朋友们
网上搜索光束图自己收集
自己看到好的照片,自己制作
PS制作方法:(很简单)举例:
网上看到这样一张图,

我们打开ps跟着做,几步就可以变成你要用的黑白
去色(ctrl+shift+u)
滤镜-模糊-高斯模糊
图像-调整-亮度/对比度
对比度拉到最大,亮度根据情况调整
保存
看到这里,相信你已进阶Ai光之魔法师了,赶快实践起来吧。
相关资源:
大模型地址:
dreamshaper:https://civitai.com/models/4384/dreamshaper
ReV Animated:https://civitai.com/models/7371?modelVersionId=46846
Lora地址:
Candihindu :https://civitai.com/models/101185?modelVersionId=108339
controlnet模型地址:
controlnet新光影模型:Lighting based picture control cldm_15.yaml:https://huggingface.co/webui/ControlNet-modules-safetensors/tree/main
光束包:https://www.123pan.com/s/BzxiVv-g2QUv.html
不知道模型路径放哪里的可以看我第一篇文章:https://kenshin.zhubai.love/posts/2282191601176842240
想每次第一时间收到推送文章,欢迎订阅我的newsletter https://xiaobot.net/p/Kenshin