Download
1 variant available
fp16 SafeTensor
ExperienceXL-v4.fp16.safetensors
Half precision, best balance • 6.46 GB
Verified: 2 years ago

3.8K
42.8K


Read Description
BETA version of Experience for SDXL.
"Now with 16x the space booty" - Todd Howard
Important Note: For ExperienceXL_v2_BETA, I recommend using the fp16 version. The full model was only uploaded so the model hash matched the sample images.
Questions/Feedback/Updates
Visit my thread on the Unstable Diffusion Discord
Buy me a coffee ❤
https://ko-fi.com/ndimensional
All donations will be used to fund the creation of new Stable Diffusion fine-tunes and open-source AI tools.
About
This is not the full release of Experience for SDXL. The full model is still in training with a projected completion sometime in May.
The BETA version is one of the latest Epochs of the fine-tune — merged lightly with an Anime model to fill in areas the early epoch lacks.
Differences between Experience SDXL (BETA) and Experience SD1.5
Not Photorealistic: This is the primary difference between the two architectures and the reason the full release still being a ways off. The SDXL (BETA) version is more akin to the early releases of Experience for SD1.5. Where 'photorealism' looks more like a real-time render than photography/cinematography. You will have a hard time getting the same level of skin detail and texturing with the SDXL (BETA) model. The full SDXL model will capable of photography and cinematography.
Update: Versions Main and later are capable of Photorealism.
Less is More: With the SDXL (BETA) version, you do not need to write a short novel when prompting the model. Try including simple adjectives to modify tokens. Such as 'A breathtaking landscape', 'An otherworldly monolithic structure.'
Use Your Preferred Prompt Style: One of the big advantages with SDXL is it's beefy text-encoders which allow for natural language prompting. All captions for base model were created by my MLLM captioning system (more info on my discord thread) in a natural language format. However, you can also use the comma-delimited keyword method of SD1.5 and Booru tags. Or, simply describe the image you want like you would to a person.
Prompt Adherence: The SDXL (BETA) version has a higher probability of returning an image that aligns more closely to what you prompted.
Styles and Mediums: Aside from the aforementioned issue with photography and cinematography — overall the SDXL (BETA) version is capable of generating images in more styles and mediums than the SD1.5 version. The best practice is to include the medium or style at the start of the prompt. For prompts with both medium and style tokens, include the medium at the beginning of the prompt and the style token towards the end.
Higher Resolution: By Nature of being SDXL.
Usage
Note: Requires VAE, found here. Or download from this page.
VAE Path (Automatic1111-Webui):
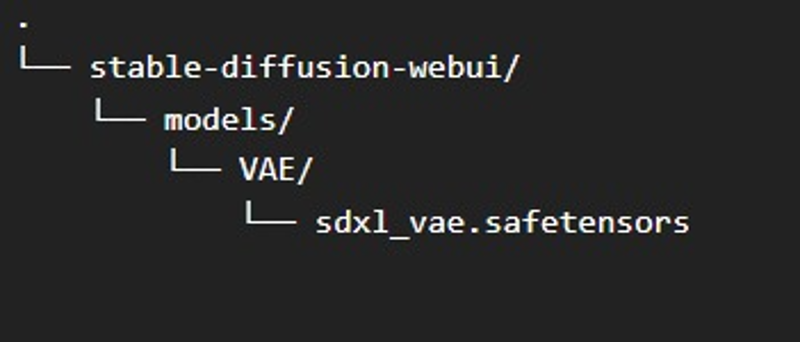
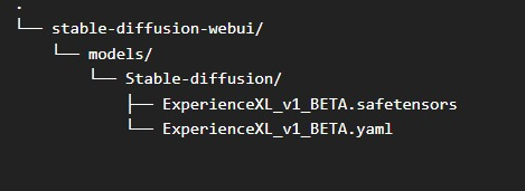
Config Path (Automatic1111-Webui):
Update: No longer needed for versions >= Main
Recommended Generation Parameters
[Sampler|Steps|CFG]
Euler a | Steps: 30 | CFG: 7
DPM++ 2M SDE Karras | Steps: 30+ | CFG: 7 - 8
Hires Fix
Untested - I personally didn't use hires fix during inference, outside a few instances where I accidently turned it on.
Extensions
ADetailer: More info on GitHub
These are just my recommendations. Use your preferred values or experiment with new values.
Changelog
4/27/24 Experience_v4 (Main):
Major improvements to photorealism.
Prompting Advice: Put the medium you wish to generate within the first five tokens.
Model no longer requires custom config.
Spring Cleaning 🧹
Latest model version labeled "Main" to improve readability of files after Civitai renames them. Latest version will always be named "Main".
"BETA" Removed from the model page title.
Note: The model is still being trained. This is not the final version.
To-Do:
Add brief descriptions for the model versions.
Update main page to reflect state of latest version.
————————————————————————————————————————
4/22/24 Experience_v2_BETA:
Slight, very slight improvements to the photorealism.
The model is still in no-way Photorealistic.
Adding
Cinematic Still Frameto the begging of the prompt, along with film/photo related tags towards the end of the prompt, and using natural language.
Tinkering with Text-encoders, nothing significant. More info soon.
Attempted improvements to the models prompting bias.
i.e., less of a chance for a booru tag inside a prompt for 3D renders to favor anime styling simply due to using booru_style_prompting.
Far from perfect, further research into the Text-encoder(s) architecture and influence on the final output is needed.
Improvements to prompt adherence (How close the models output is to your prompt).
Overall fidelity improvements.
Checkout my other models
SDXL
LoRA SDXL
Custodes (40k series) - https://civitai.com/models/411620/custodes-warhammer-40k-sdxl
Necron (40k series) - https://civitai.com/models/376124/necron-warhammer-40k-sdxl
Skaven (Warhammer Fantasy) - https://civitai.com/models/372405/skaven-warhammer-fantasy-sdxl
Drukhari (40k series) - https://civitai.com/models/372433/drukhari-warhammer-40k-sdxl
Astartes (40k series) - https://civitai.com/models/363602/space-marine-astartes-warhammer-40k-sdxl
Sisters of Battle (40k series) - https://civitai.com/models/331253/sisters-of-battle-warhammer-40k-sdxl
Death Korps XL (40k series) - https://civitai.com/models/331161/death-korps-warhammer-40k-sdxl
T'au Empire XL (40k series) - https://civitai.com/models/315640/tau-empire-warhammer-40k-sdxl
Aeldari XL (40k series) - https://civitai.com/models/282039/aeldari-xl
Oldhammer XL (40k series) - https://civitai.com/models/281371/oldhammer-xl
Mechanicum XL (40k series) - https://civitai.com/models/258266/mechanicum-xl
SD1.5
Ishimura - https://civitai.com/models/299614/ishimura
SciStyle - https://civitai.com/models/204351/scistyle
Doomer Boomer - https://civitai.com/models/118247/doomer-boomer
Lomostyle - https://civitai.com/models/109923/lomostyle
Another Damn Art Model (ADAM) - https://civitai.com/models/104898/another-damn-art-model-adam
Based Model - https://civitai.com/models/83991?modelVersionId=89262
Electric Eden - https://civitai.com/models/64355/electric-eden
Cine Diffusion - https://civitai.com/models/50000/cine-diffusion
ProjectAIO - https://civitai.com/models/18428/project-aio
WonderMix - https://civitai.com/models/15666/wondermix
Refined - https://civitai.com/models/8392/refined
Experience - https://civitai.com/models/5952/experience
Elegance - https://civitai.com/models/5564/elegance
Clarity - https://civitai.com/models/5062/clarity
VisionGen - Realism Reborn -https://civitai.com/models/4834/visiongen-realism
LoRA SD1.5
Pant Pull Down - https://civitai.com/models/11126/pant-pull-down-lora