How to Generate Multiple Different Characters, Mix Characters, and/or Minimize Color Contamination | Regional Prompt, Adetailer, and Inpaint | My Workflow
3.8k
17.4k
2.9k



How to Generate Multiple Different Characters, Mix Characters, and/or Minimize Color Contamination | Regional Prompt, Adetailer, and Inpaint | My Workflow
Edit: 27.01.25
Hey, it's been a while—more than six months, to be exact. The AI/SD space changes so quickly that it’s hard to keep up with all the possible errors. Everyone uses different WebUIs and versions, so some might work while others don’t.
Sections 1 and 3 of this tutorial focus on the Regional Prompt Extension, which no longer works with the new Forge (i.e., since the import of Flux). Old Forge and Reforge might still support it. If you’re using the new Forge, you may want to install Forge Couple instead.
I’ve now added a fourth section covering SD Forge Couple. Most of the basic concepts are already explained in Sections 1 and 3, so this new section will focus on the usage of Forge Couple. The underlying logic is similar to the Regional Prompt Extension, but there are some differences.
(All images shown in Section 4 were generated on IllustriousXL/PaSanctuary.)
Edit: 30.06.24
I added a brief installation guide on how to install this extension. I will continue this tutorial section (Part 4) shortly after my exams. Things have been pretty busy lately, so I apologize for the inconvenience.
0. Intro
Hello everyone,
here is a little guide that will be updated from time to time. I will add different versions on top of the model page to show you some different images with their metadata, so you can copy and paste into auto1111/forge. I post this in a model page instead of article, because I can showcase images better this way, while also having a better view of comments I get. No need to download the file I attached here.
In this guide, I will go over Regional Prompt, Adetailer, and inpainting. This is also different on XL and 1.5, so the settings are not the same on both versions, but similar.
What do we need?
SD Forge Couple (Section 4)
Checkpoints and LoRA's
Any Character LoRA's, but works with baked-in characters as well.
Models, where I used/needed Regional Prompt:
Here is a small list of models that I published, where you might need or want a regional prompt for optimal results:
For Pony:
For 1.5:
For Illustrious:
Note for 1.5: 1.5 LoRAs require Latent Mode, which is currently not usable in Forge. This tutorial doesn't cover that for now but will do so later. It's a bit more complicated.
0.5 INSTALLATION:
First, we start our WebUI (in this case, Auto1111 or Forge). It's best to use the latest version of either one. After opening the WebUI, go to the Extensions Tab -> Install from URL. Paste the following link under URL for extension's git repository: https://github.com/hako-mikan/sd-webui-regional-prompter. Then, press Install.
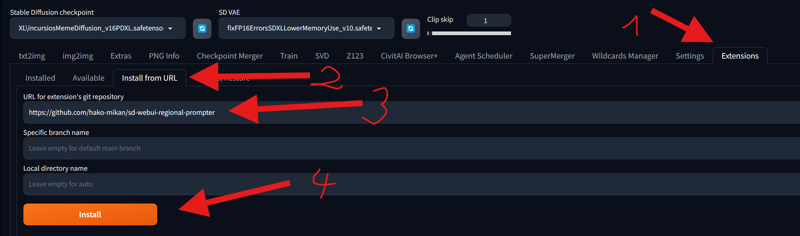 After doing that, restart your WebUI. I recommend closing the WebUI terminal and rerunning it.
After doing that, restart your WebUI. I recommend closing the WebUI terminal and rerunning it.
Note: If you are using Colab or sharing your WebUI with the command-line argument --listen, you might need to add an additional command-line argument: --enable-insecure-extension-access. WARNING: Only use this command if you are the only one using your WebUI. If other people use your WebUI, you need to trust them, or you could lose your data or get hacked.
The file with the command-line arguments can be found in your WebUI folder. It's called webui-user.bat. Right-click and open it with a text editor or Notepad to edit it.
 You don't need to do this step if you don't share your WebUI. It's only necessary when you use
You don't need to do this step if you don't share your WebUI. It's only necessary when you use --listen or when using Google Colab or something similar.
1. REGIONAL PROMPT Basic (Matrix) (Pony XL):
Overall Settings:
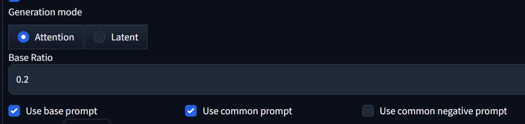
After installing all necesarry Extensions, you will see in your txt2img and img2img the tab "Regional Prompt".
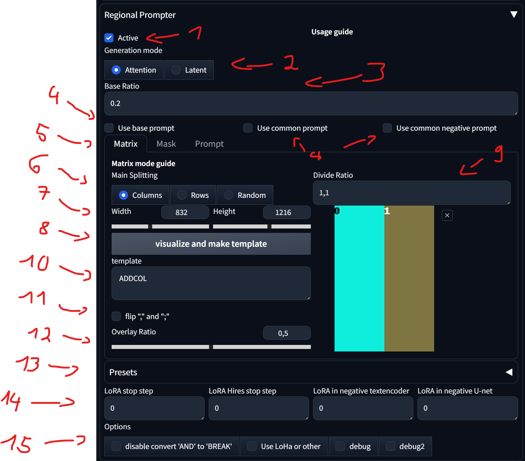
Activate/disable
There are two generation modes. For XL, only the 'Attention' mode is important, with or without LoRAs. The 'Latent' mode doesn't work properly IN FORGE, due to the XL encoder. A separate Tutorial section will be done for 'Latent' mode.
With the base ratio, we can change how strong the base prompt is. If the base value is 0.2, then the weight of the base prompt in the generation is 0.2, and the divided areas are 0.8.
Base, Common, and Negative Prompt:
'Use base prompt' affects the entire image, mostly used for backgrounds and/or characters, impacting all divided areas. I personally don't use it much.
'Use common prompt' copies and pastes all prompts in that section to all regions.
'Use common negative prompt' does the same for the negatives. This is only useful if you want to have a specific negative in a specific divided area. Otherwise, leave it unchecked, as the negatives will affect the entire image anyway.
Section for Matrix, Mask, and Prompt: We will see the differences between them later. For now, we will focus on Matrix.
Main Splitting: This allows you to change how you divide the template. Changing this and pressing 'visualize and make template' will update it to the template.
Changing Width and Height does not affect the image; it's there only for visualizing the template. You can leave it at its default setting.
Pressing 'visualize and make template' will update the template on the right side.
Dividing Ratio:
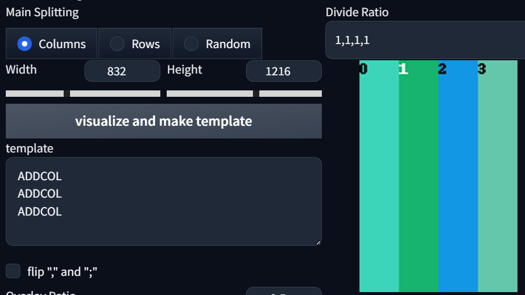
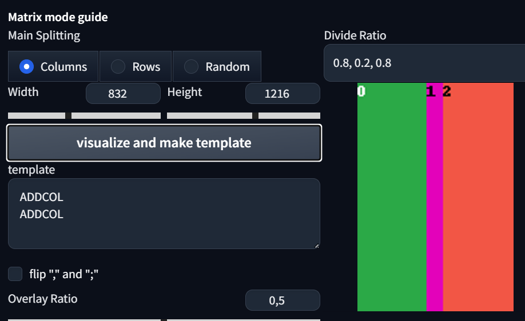
This divides your image into regions. Setting it to 1,1 will give you 2 regions. Setting it to 1,1,1 will give you 3 regions. You can even set different sizes for regions. Here are some examples:
1,1 Columns

1,1,1,1
0.8, 0.2, 0.8
1, 1; 1,1,1
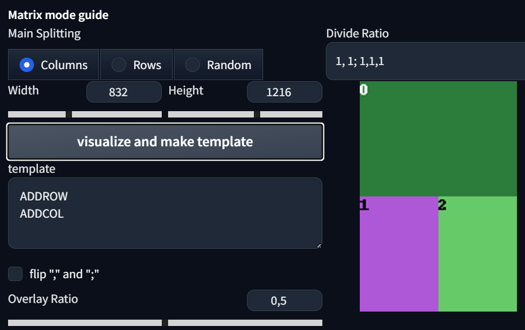
1,1; 2, 3, 3

1, 1, 1; 1, 1, 1
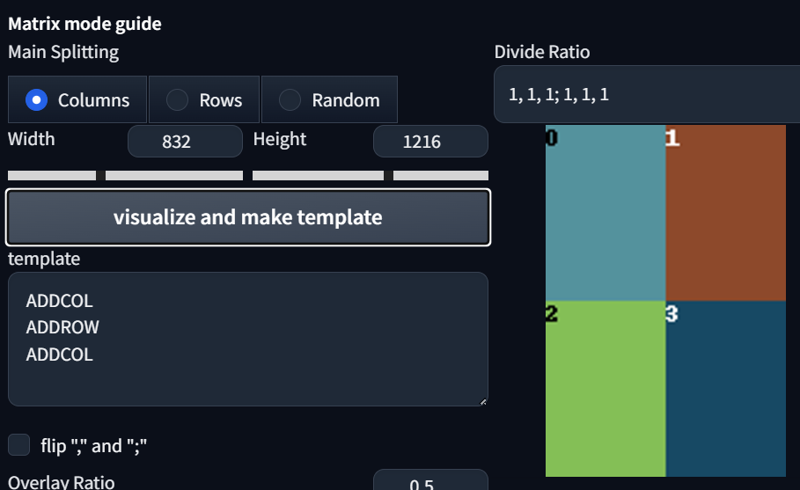
Shows the current template format and the order of regions.
Flips ',' and ';'. Fairly useless.
The overlay ratio might be an important factor in determining how much impact one region with its prompt and overlay has on other regions. If you require precise prompting and don't want much interaction between the regions, lower the ratio. If not, keep it at 0.5.
Your presets
Options for Latent, fairly useless for us in XL.
Options for other things that might be needed for debugging.
Prompting Multiple Characters:
So, how do we use it? Let's start with something basic. First, activate the regional prompt, select the common prompt, divide the ratio to 1,1, create the template, and then set your prompts:
score_9, score_8_up,score_7_up, source_anime, indoors, standing, cowboy shot, 2girls, seductive smile, from above, hoodie, jeans, looking at viewer,
BREAK yae miko,
BREAK raiden shogun,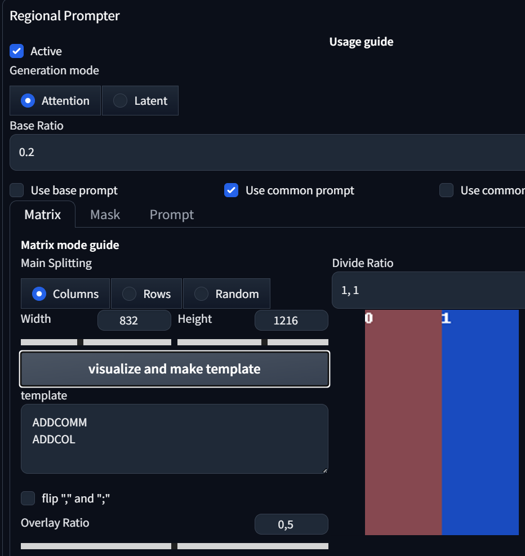


Okay, what do the prompts do here? We selected the Common prompt, which means the first line of the prompt will be applied to all regions. After the use of our first BREAK prompt, we arrive at our first region, Region 0. Here, I typed a baked-in character that is already quite stable without any additional use of LoRA. In this case, Yae Miko. After that, I added another BREAK to move to my second region and typed in another baked character, also known as Raiden Shogun.
See, that was pretty simple, right?
We can also make the prompt a bit longer or more complicated. Let's try the same settings, but with more prompts:
score_9, score_8_up,score_7_up, source_anime, indoors, standing, cowboy shot, 2girls, seductive smile, from above, hoodie, jeans, looking at viewer,
BREAK yae miko, black hoodie, waving,
BREAK raiden shogun, white hoodie, hand on hip
Okay, how about adding another character? Sounds crazy, right? Now, let's incorporate the use of LoRA for "Fubuki from @holostrawberry". Here are the prompts and settings:
score_9, score_8_up,score_7_up, source_anime, indoors, standing, cowboy shot, 3girls, seductive smile, from above, looking at viewer,
BREAK yae miko, black hoodie, hoodie, jeans,
BREAK raiden shogun, white hoodie, hoodie, jeans,
BREAK reaching towards viewer, <lora:fubukiXL:1>, fubukibase, white blouse, detached sleeves, black shorts, blue neckerchief, thigh strap, single thighhigh, white hair, single side braid, ahoge, piercing, fox tail, pentagram,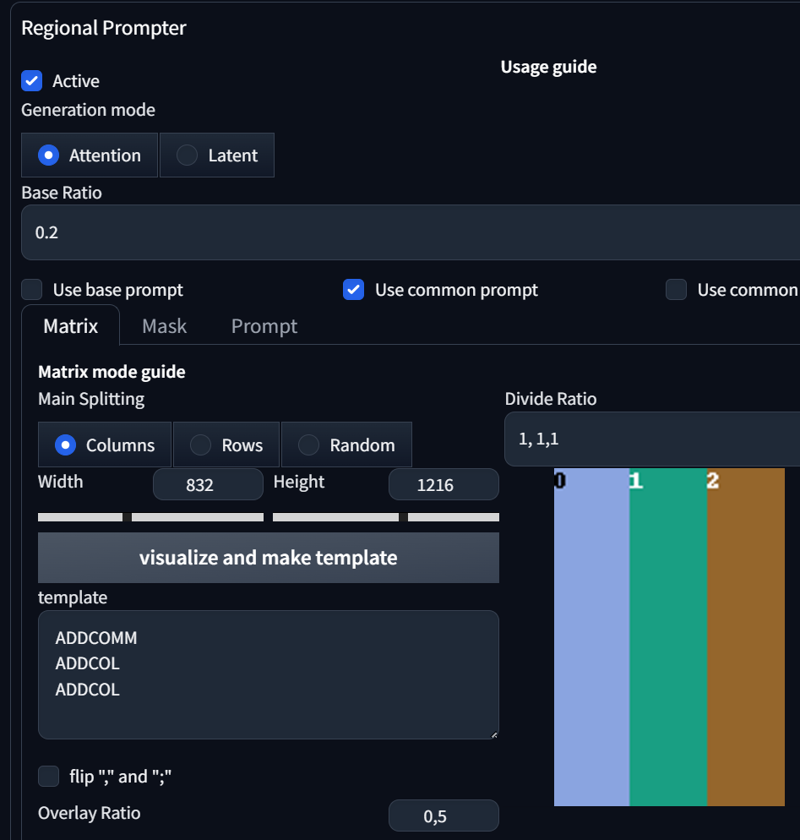

So, what changed? First of all, I tweaked the prompt slightly. I changed "2girls" to "3girls", swapped the positions of hoodie, jeans in the prompt, and added another BREAK to introduce another character. In the Regional Prompt Settings, I simply added another Divide Ratio; in this case, it's 1,1,1.
As you can observe, the results are becoming somewhat unstable. Incorporating elements like Cowboy shot, from above and generating images of 3 people can complicate maintaining the same scenario. However, by removing from above, we achieve this image:

As you can see, our image becomes a bit more stable and follows the prompts more closely. What you prompt is very important; every single prompt can and will induce drastic changes. If something is not going according to plan in Regional Prompt, try to be more precise in your prompts.
Let's prompt some more girls, shall we? Changing to a 1344x768 landscape format and increasing the number of sample steps from 24 to 30. Adding another two LoRAs Frieren and Watame from @ChameleonAI):
score_9, score_8_up, score_7_up, source_anime, 6girls, office, office lady, around table, table, food, beverage, burger, starbucks, shirt,
BREAK yae miko, smirk,
BREAK raiden shogun (genshin impact),
BREAK yoimiya \(genshin impact\),
BREAK FrierenBase, green eyes, white hair, long hair, twintails, earrings, <lora:ChamFrierenPonyXL:1>, eating burger,
BREAK keqing \(genshin impact\),
BREAK <lora:CHAR-TsunomakiWatamePonyXL:1>, TsunomakiWatame, sheep girl, long hair, ahoge, happy, sheep horns, blonde hair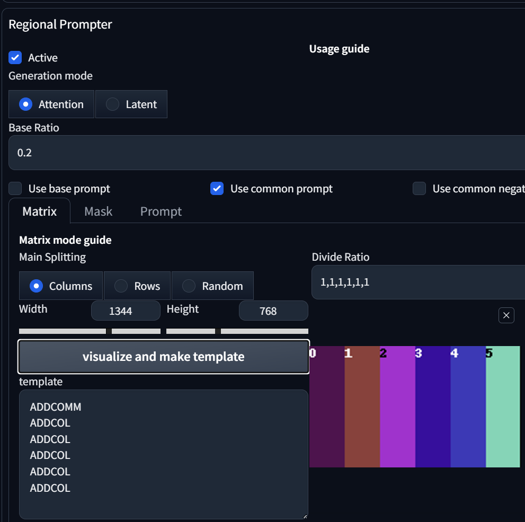

Cool, right? Using two different Character LoRAs while also prompting four baked-in characters in one image. With that many people, there's a high chance that you'll encounter image errors.
Now, let's combine some actions or concepts with multiple characters. As always, let's start with something basic and add "hug":
score_9, score_8_up,score_7_up, source_anime, indoors, standing, cowboy shot, 2girls, seductive smile, looking at viewer, hoodie, jeans, hug,
BREAK yae miko, black hoodie,
BREAK raiden shogun, white hoodie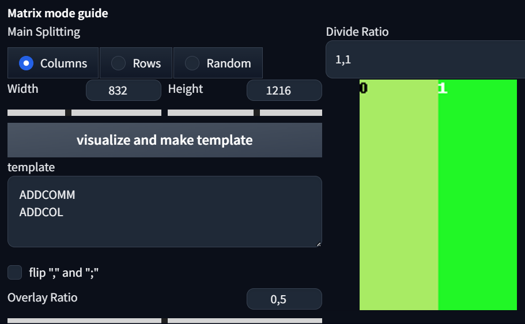

Hugging each other without much problem? Well, that's because our overall overlap ratio is high enough.
Now let's do it with a Concept LoRA called Handshake from @justTNP. Same settings, but with a different aspect ratio (1:1) and a different prompt:
score_9, score_8_up,score_7_up, source_anime, indoors, standing, cowboy shot, 2girls, seductive smile, looking at another, hoodie, jeans, handshake, <lora:concept_handshake_ponyXL:0.5>,
BREAK yae miko, black hoodie,
BREAK raiden shogun, white hoodie,
As you can see, I used that LoRA in the common prompt, but with half of the original weight (1 -> 0.5). Divide by the amount of regions you use, so if you have 2 regions, do half of the original LoRA weight. The reason for this adjustment is that each region takes the value, and the overall image shouldn't exceed a reasonable amount of LoRA weight.
Edit: Keep the batch size low. Max batch size should only be 4.
Also, using multiple characters requires you to adjust your Adetailer, because your Adetailer doesn't get affected by the regional split. It will mix faces and can dominate one eye color.
2. Adetailer
Adetailer is a very useful tool for detecting stuff and automatically inpainting. There are different YOLO models like face, hand, eye, full body, feet, clothing, etc., but we will focus here on the face model. There are two main ways to use Adetailer: one via Txt2Img and the other with Img2Img.
If you generate an image with one person and have your Adetailer on, it works normally. If you generate two people, with or without Regional Prompt, the attributes will most of the time be mixed. Dominant color or attributes from the other character will take over. Here is how to fix that.
Settings:
First, we need to adjust one setting when we install Adetailer. Go to Settings -> Adetailer -> Sort bounding boxes by -> Set it to "Position (left to right)"

That's it for now. Let's move on to image generation.
Adetailer (Txt2Img):
First, let us generate an image without adetailer on:
score_9, score_8_up, source_anime, 2girls, upper body,
BREAK white shirt, red eyes, black hair, long hair, tongue out, mole under eye,
BREAK black shirt, blue eyes, blonde hair, ponytail, smirk,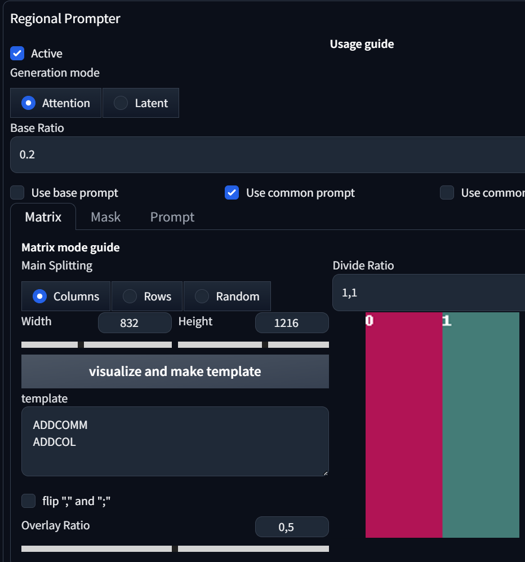

As you can see, the results are quite sharp even without the use of Adetailer. This is because we are using an upper body shot. Most faces will be sharp, but we can also see much more detail when we use Adetailer. Now, let's enable Adetailer.


Both faces were detected by the Adetailer. As you can also observe, features like a mole under the eye, tongue out and smirk are getting mixed here. This is expected. How do we fix that? Easy solution: We use the [SEP] token in our Adetailer positive prompt. Generating this image again yields this result:


This was quite an easy example. Let's try this with a LoRA. Here are Ranni from Elden Ring and Vergil from DMC:
score_9, score_8_up, source_anime, cowboy shot, standing,
BREAK 1girl, <lora:Ranni_XLPD_CAME:1>, IncrsXLRanni, wavy hair, cracked skin, blue skin, colored skin, extra arms, extra faces, doll joints, white dress, witch hat, brown cloak, waving, crying,
BREAK 1boy, <lora:dmc5_vergil_ponyXL:1>, dmc5vergil, black coat, fingerless gloves, pants, smirk,without adetailer

Adetailer detecting Faces:

Adetailer without Prompt:

As you can see here, Vergil got some attributes from Ranni, like one eye closed and her crying. Let's fix that with this Adetailer prompt:
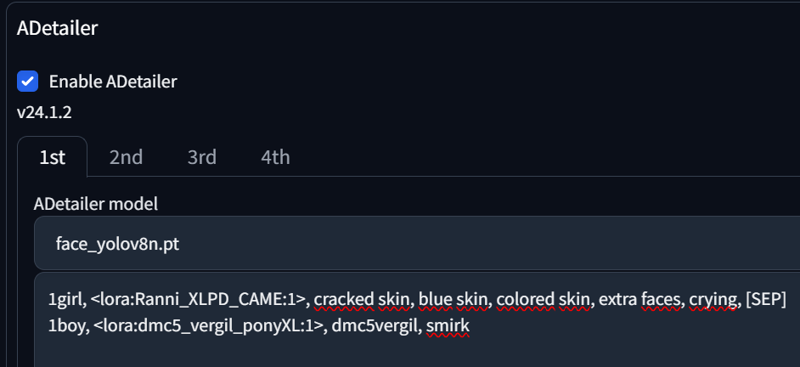

And it's done. Nothing more is needed here.
One final aspect you need to be aware of is that some VAEs leave marks around the faces. I'm currently using flatpieceVAEXL, and it can get quite messy, especially with other color VAEs. Here is one example:
score_9, score_8_up, source_anime, 1girl, solo, looking at viewer, cowboy shot, medieval, grass, flower field, cloudy sky, red eyes, long hair, black hair, shirt, jeans

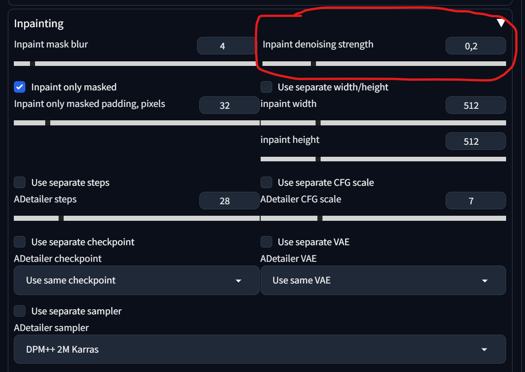
As you can see, it leaves a square, that looks very off. There are 2 ways to fix it.
1) Adetailer -> Inpainting -> Inpaint denois strength from 0.4 to under 0.2
2) Adetailer -> Inpainting -> Use separate VAE -> sdxl_Vae (default) or something more neutral
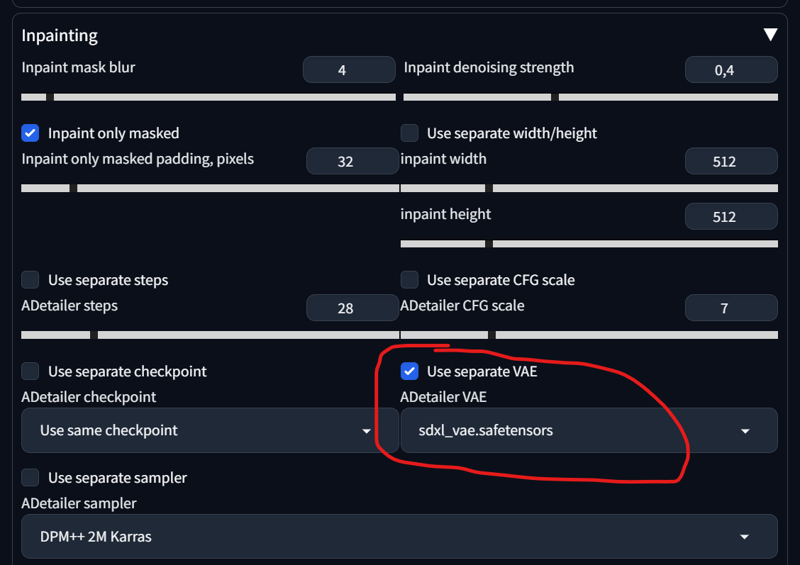
Both are viable. Here is the Result:


Let's move to the next section.
Adetailer (Img2Img):
If you have an image and you don't want to use Adetailer in txt2img (to save VRAM), then you can move that image to the img2img tab. This way, you have more control over the prompts you want to experiment with, without having to regenerate that image over and over again. Our starting image is this:

As you can see, the faces are somewhat off. We'll move that image to img2img now and adjust our settings and prompt:


Important here:
set width and height to 1024x1024 (for XL) or 512x512 (for 1.5)
set denois strength to 0.9 (in img2img)
set your prompt in your adetailer
enable "Skip img2img"
The Result:


Okay, this seems to work quite well with 2 faces. But how about multiple faces? That's also quite straightforward. Let's take the initial image from the Regional Prompt:

Setting prompts:

Adetailer detecing:

Result:

As you can see, Adetailer detected 6 faces. We separated each face with a [SEP] token and adjusted every face accordingly, from left to right. You might wonder what would happen if I just input 2 prompts with one [SEP] token for 6 faces. Well, the first face receives the first prompt, and the other 5 faces receive the second prompt.
If you use only one prompt, you can also create something funny. Here is the DIO's Face LoRA:
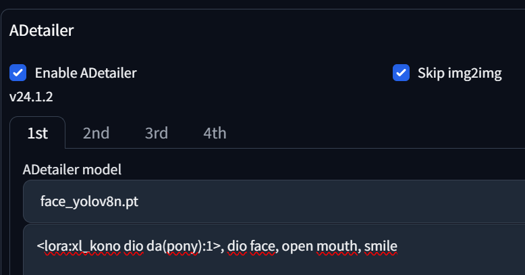

Well, that's everything for this section. The next update will focus more on the Regional Prompt Mask instead of the Matrix.
3. Regional Prompt (Mask)
The mask mode is a very useful tool for directly painting over the region where you want your prompt to apply. It also allows for better control over the regional overlap. @PotatCat is a big fan of the Mask mode, and it's understandable why. Check out his image gallery if you want to try and see what's possible.
Overall Settings and inpainting the Area:
First, let me introduce you to the overall settings for it. It might seem a little complicated at first, but bear with me. Instead of choosing "Matrix" in our Regional Prompt, we are going to choose "Mask" now.
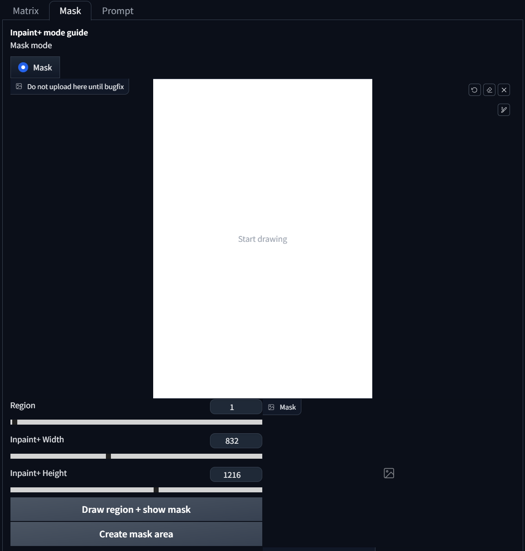 We first want to adjust the width and height to our initial size that we aim to generate. In my case, it's 832x1216. After that, you press "Create mask Area." That's our first step. Now we can start drawing. After drawing our region, we press "Draw region + show mask.
We first want to adjust the width and height to our initial size that we aim to generate. In my case, it's 832x1216. After that, you press "Create mask Area." That's our first step. Now we can start drawing. After drawing our region, we press "Draw region + show mask.
 As you can see, the Region Slider changed from '1' to '2', while also displaying a mask beside it. If you now draw another region and press 'Draw region + show mask' again, it will automatically advance to the next region and update the output mask.
As you can see, the Region Slider changed from '1' to '2', while also displaying a mask beside it. If you now draw another region and press 'Draw region + show mask' again, it will automatically advance to the next region and update the output mask.
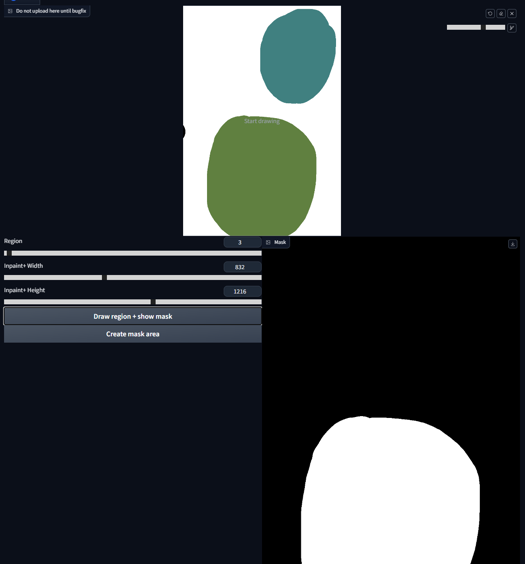 It's possible to add to existing regions by reselecting the same number and drawing as usual. In this case, we choose Region 1, paint it, and press 'Draw region + show mask' again.
It's possible to add to existing regions by reselecting the same number and drawing as usual. In this case, we choose Region 1, paint it, and press 'Draw region + show mask' again.
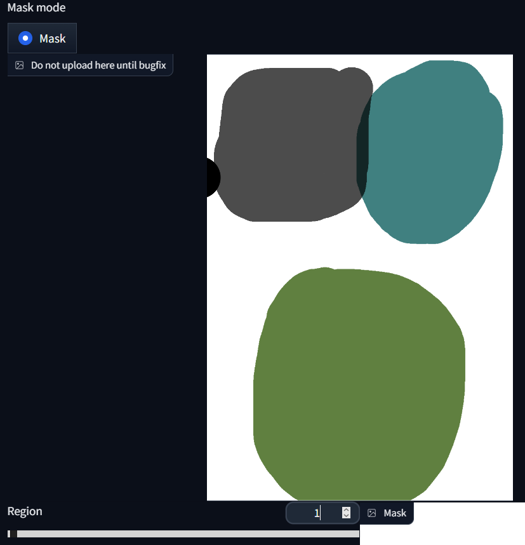
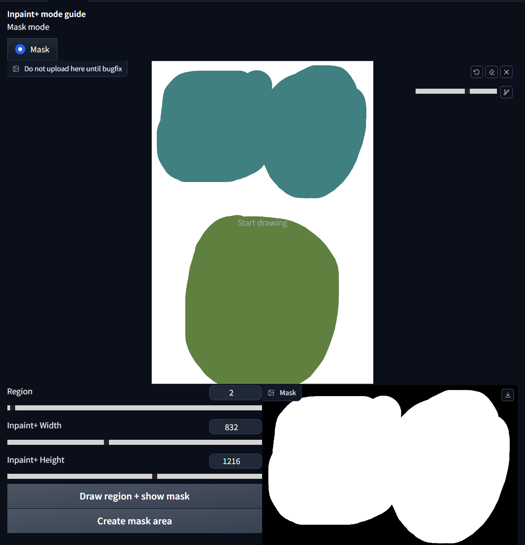 We can also display all the regions in the mask area by selecting -1 on the Region Slider and pressing 'Draw region + show mask'.
We can also display all the regions in the mask area by selecting -1 on the Region Slider and pressing 'Draw region + show mask'.

Special Case for Base Prompt:
Now, let's discuss the Base prompt. Using both Base prompt and Common Prompt in mask mode is advantageous because the Base prompt will fill all the non-masked areas.
 When the base is off, any non-colored regions are added to the first mask (and thus should be filled with the first prompt). When the base is on, any non-colored regions will receive the base prompt in full, while colored regions will receive the usual base weight.
When the base is off, any non-colored regions are added to the first mask (and thus should be filled with the first prompt). When the base is on, any non-colored regions will receive the base prompt in full, while colored regions will receive the usual base weight.
The Base Ratio in this case can be set to 0 if you want to avoid any bleeding between the background and masked area. Alternatively, you can set the weight higher, like a 0.2 ratio. The inpainted area has an impact of a 0.8 ratio in this scenario. I would suggest staying at 0 or 0.2 and not going higher.
Prompting in Mask:
Now that we are using Mask mode with a Base prompt, we need to slightly adjust our prompting approach. Starting small, we activate "base prompt" and "common prompt", mask our area, and prompt:
score_9, score_8_up,score_7_up, source_anime,
BREAK forest, grass,
BREAK yae miko, from behind, sitting, full body, kneeling,
BREAK moon, full moon,
BREAK hill,
 Okay, what happend?
Okay, what happend?
The first prompt: score_9, score_8_up,score_7_up, source_anime will be applied to all regions because it's our common prompt.
The first BREAK describes our base prompt, in this case BREAK forest, grass,.
Our first region begins with light blue mask and prompt yae miko, from behind, sitting, full body, kneeling.
Our second region is green with the prompt BREAK moon, full moon.
Our last region is pruple with the prompt BREAK hill.
Our three regions receive their respective prompts, and our base prompt fills out everything that is not painted.
Let's try something else, shall we? Now with LoRAs:
score_9, score_8_up,score_7_up, source_anime,
BREAK burning kitchen, messy, flames,
BREAK <lora:Doro_X_PDXL_V1:1>, doro, burning, cooking, creature, :3, chibi, pink hair, purple eyes, hair bun, hair bow, no humans, white skin, four legs, solid circle eyes, no pupils,
BREAK <lora:elie-pdxl-nvwls-v1:1>, zeroElie screaming, horrified, arms up, hands behind head, standing, black hairband, hair ribbon, long hair, ascot, uniform, long red sleeves, white dress, pencil skirt, belt, white hair,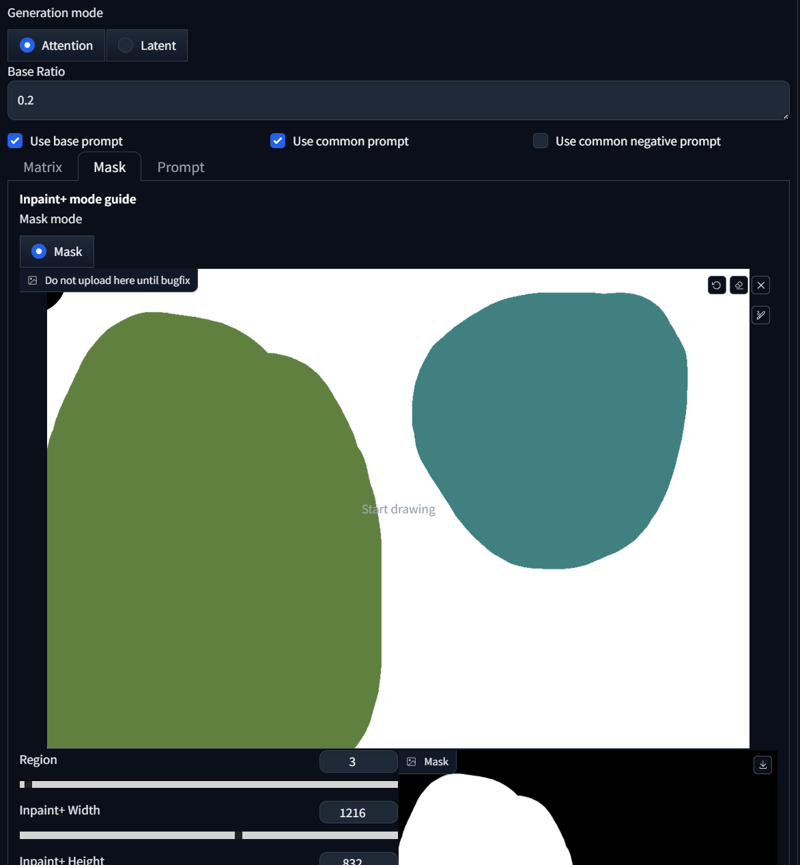
 As you can see, both regions received our dedicated prompt. That was pretty simple. What else can we do? We can create crossover regions. Here's an example:
As you can see, both regions received our dedicated prompt. That was pretty simple. What else can we do? We can create crossover regions. Here's an example:
score_9, score_8_up, score_7_up, source_anime, 2girls, princess carry,
BREAK cherry blossoms, outdoors, day,
BREAK raiden shogun, expressionless, holding person, black shirt, jeans,
BREAK yae miko, happy, black pantyhose, pencil skirt, white shirt, office lady, 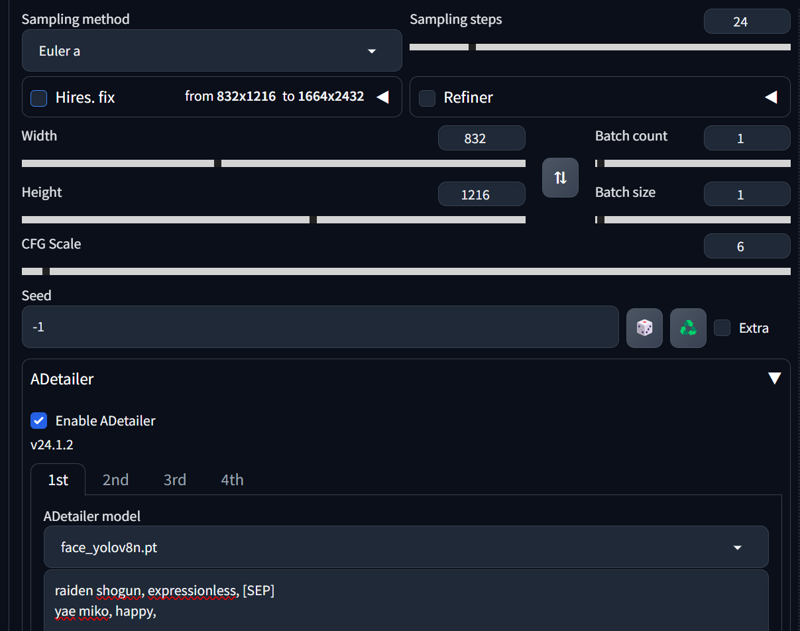

 We also have to adjust Adetailer, as we learned before. As you can see, we can overlap two regions if the interaction extends across a region. Unfortunately, such things don't work in Matrix mode, but Mask mode facilitates this.
We also have to adjust Adetailer, as we learned before. As you can see, we can overlap two regions if the interaction extends across a region. Unfortunately, such things don't work in Matrix mode, but Mask mode facilitates this.
It's not only about overlapping; elements can also coexist within a single inner region. Here's another example:
score_9, score_8_up,score_7_up, source_anime,
BREAK cherry blossom,
BREAK 1girl, red eyes, black hair, white shirt, long hair, seductive smile, holding creature, holding pikachu,
BREAK pikachu, pokemon (species), smile, open mouth,
BREAK bird, flying bird
 This makes holding animals or objects rather easy. But sometimes, you want to capture the imprint of the object, and SD doesn't quite catch it. You can also accomplish this in Mask mode.
This makes holding animals or objects rather easy. But sometimes, you want to capture the imprint of the object, and SD doesn't quite catch it. You can also accomplish this in Mask mode.
If we prompt without Regional Prompt
score_9, score_8_up, score_7_up, source_anime, 1girl, cherry blossoms, shirt, watermelon, watermelon print, jeans, yae miko, it tends to give us this Result:
 If we prompt without Regional Prompt, it tends to generate the object while holding it, despite prompting for a
If we prompt without Regional Prompt, it tends to generate the object while holding it, despite prompting for a print. If we include Regional Prompt, that changes:
score_9, score_8_up, score_7_up, source_anime, 1girl,
BREAK cherry blossoms,
BREAK shirt, watermelon, watermelon print,
BREAK jeans,
BREAK yae miko, 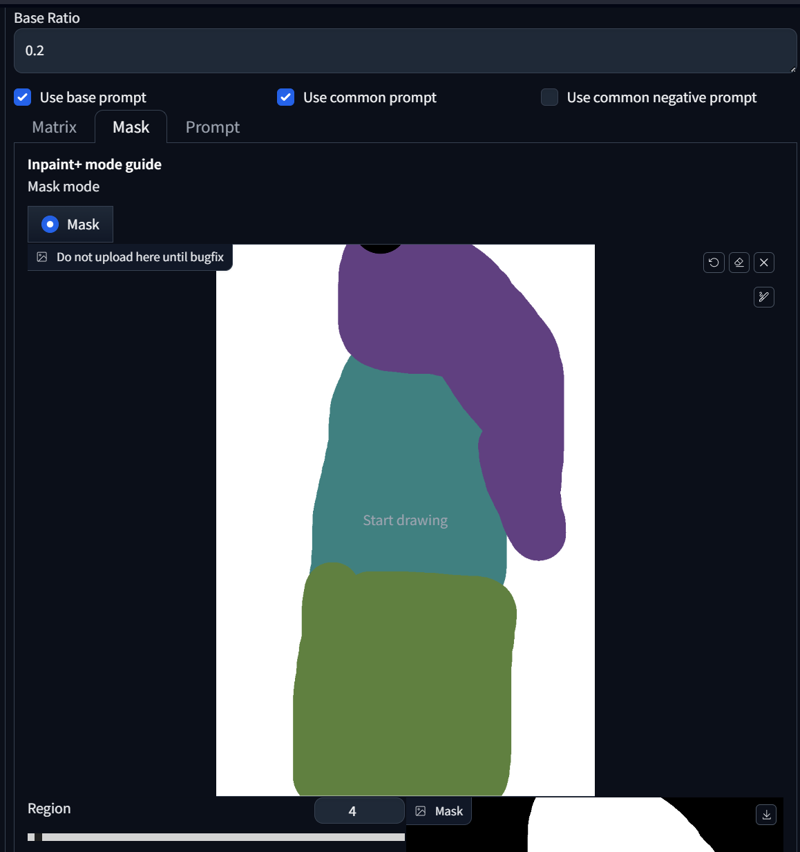
 That's it. This part was rather quick because most of it was already explained before. I will be away for 3 weeks now, so the next update might take a while. The next part will include the Inpaint section on how to correct mistakes and reduce blur.
That's it. This part was rather quick because most of it was already explained before. I will be away for 3 weeks now, so the next update might take a while. The next part will include the Inpaint section on how to correct mistakes and reduce blur.
4. Forge Couple - Advanced
(Forge Couple works in ComfyUI. See here: Link1 & Link2)
Overall Settings:
After installing all necessary extensions, you’ll see a “Forge Couple” tab in both your txt2img and img2img interfaces.
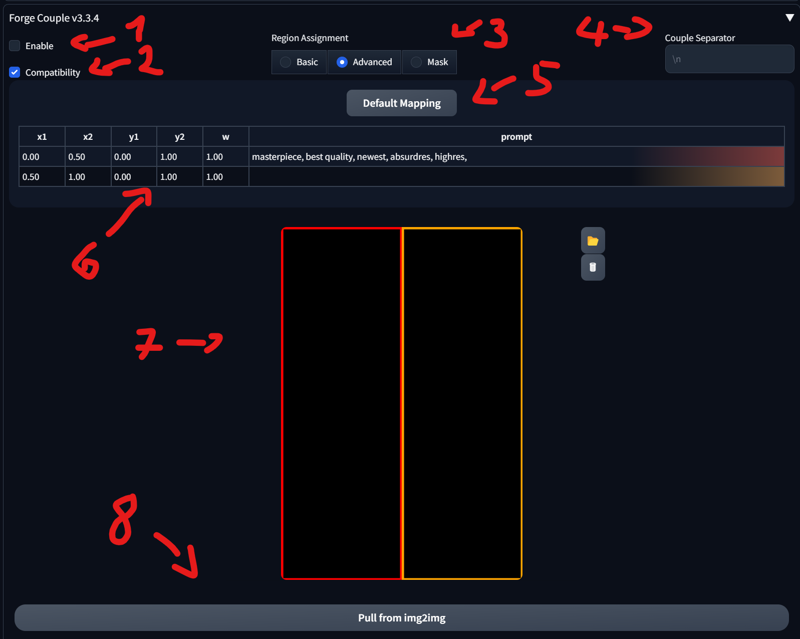
Enable/Disable
When the option is enabled: The extension will not function during the Hires Fix pass, to improve compatibility with other extensions..
Basic, Advanced, and Mask:
Basic: Divides the image into multiple tiles. You can configure the direction on this tab. I don’t use it much, so it won’t be covered here.
Advanced: Lets you specify each region manually.
Mask: Similar to Section 3 of this tutorial, where you can mask specific areas instead of using a matrix.
Couple Separator: When left empty, it defaults to “\n” (i.e., pressing Enter creates a new line). It’s best to leave it as is.
Default Mapping: Resets the current matrix.
Main Splitting: Allows you to change how the template is divided. Changing this updates the template accordingly.
Template: Shows a visual representation of the current splitting and mapping.
Pull image from img2img: Imports the image from img2img.
Presets: Lets you select or save your own presets.
Common Prompts: Lets you choose the syntax for common prompts.
Debug: Enables debugging.
SD Forge Couple - Advanced:
The mapping might seem overwhelming at first. Let’s start with the default configuration:
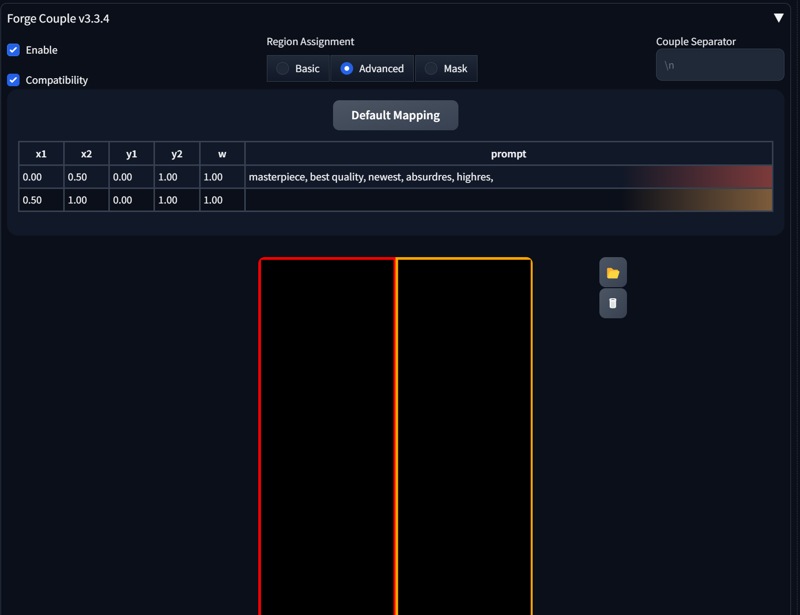 Enable Forge Couple and go to the Advanced section. The first line already contains a prompt; this is the prompt you use in your generation tab:
Enable Forge Couple and go to the Advanced section. The first line already contains a prompt; this is the prompt you use in your generation tab:
 When you add a new line, it appears as the second line. You can also edit the prompt directly in Forge Couple—whichever way you prefer.
When you add a new line, it appears as the second line. You can also edit the prompt directly in Forge Couple—whichever way you prefer.
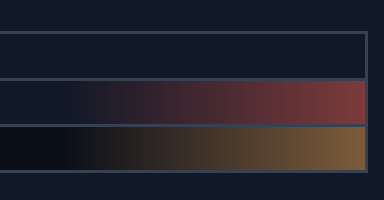
 On the right, you’ll see colors indicating which region each prompt applies to. Clicking on a prompt will highlight the corresponding area in the template.
On the right, you’ll see colors indicating which region each prompt applies to. Clicking on a prompt will highlight the corresponding area in the template.
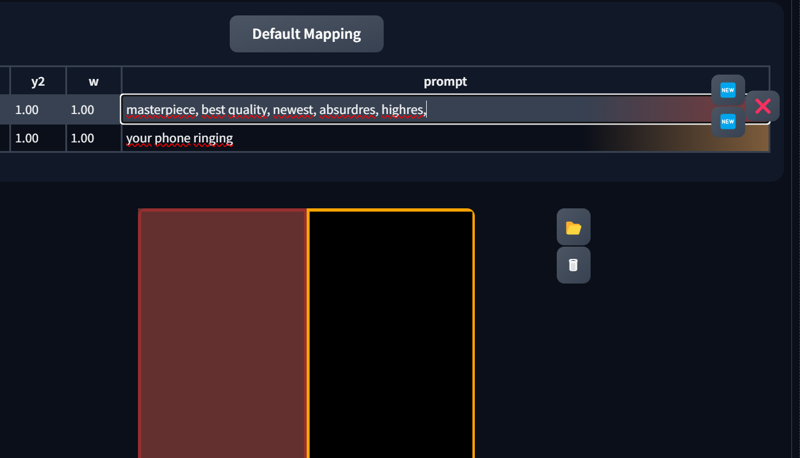
You can change the region size with x1, x2, y1, y2.
“w” sets the weight (leaving this at 1 is perfectly fine).
The horizontal axis is X, and the vertical axis is Y, with values ranging from 0 to 1.
Make sure not to leave gaps, or the generation may fail.
 When you click on a prompt, you’ll see two or three new buttons:
When you click on a prompt, you’ll see two or three new buttons:
New: Creates another region.
X: Deletes the currently selected region.
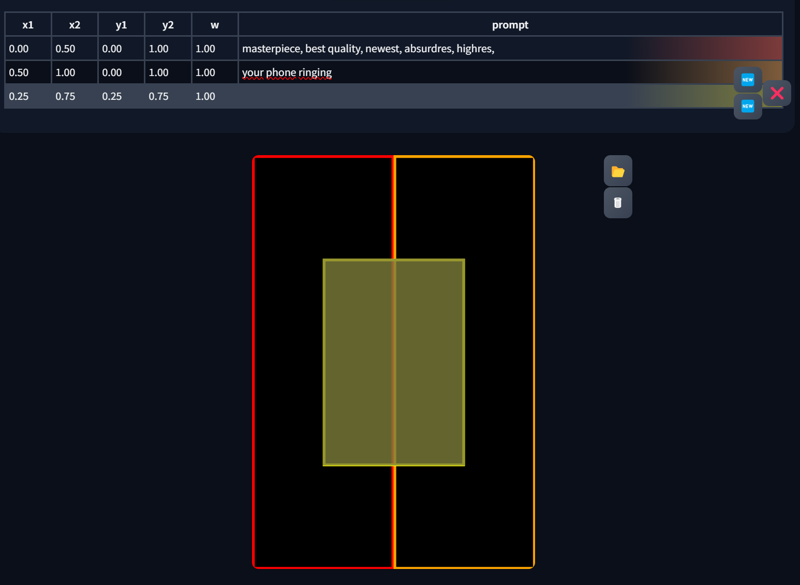 Adjusting the X and Y values will also change the template. Here are some examples:
Adjusting the X and Y values will also change the template. Here are some examples: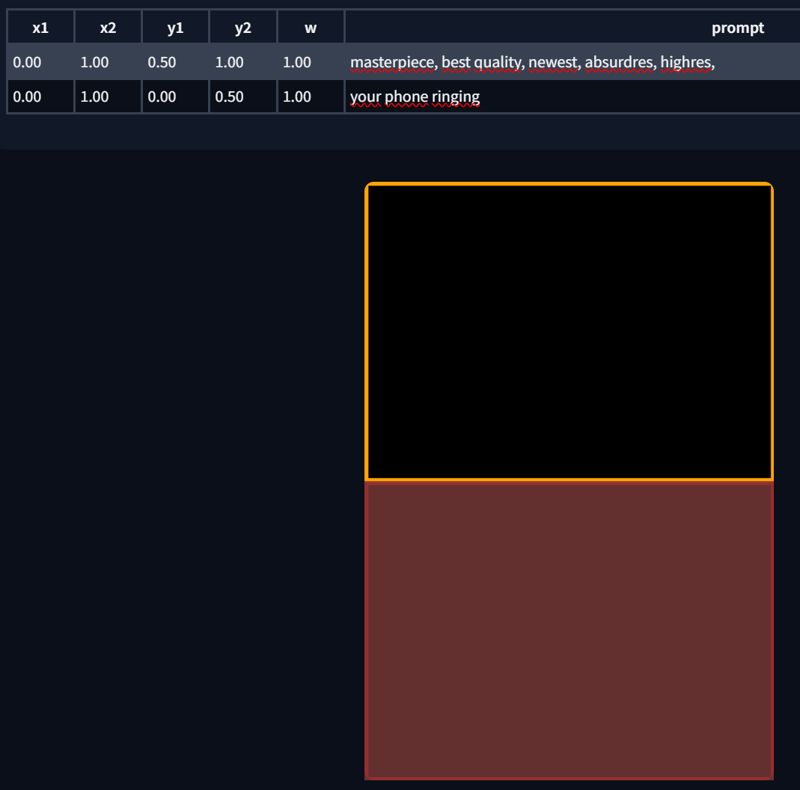
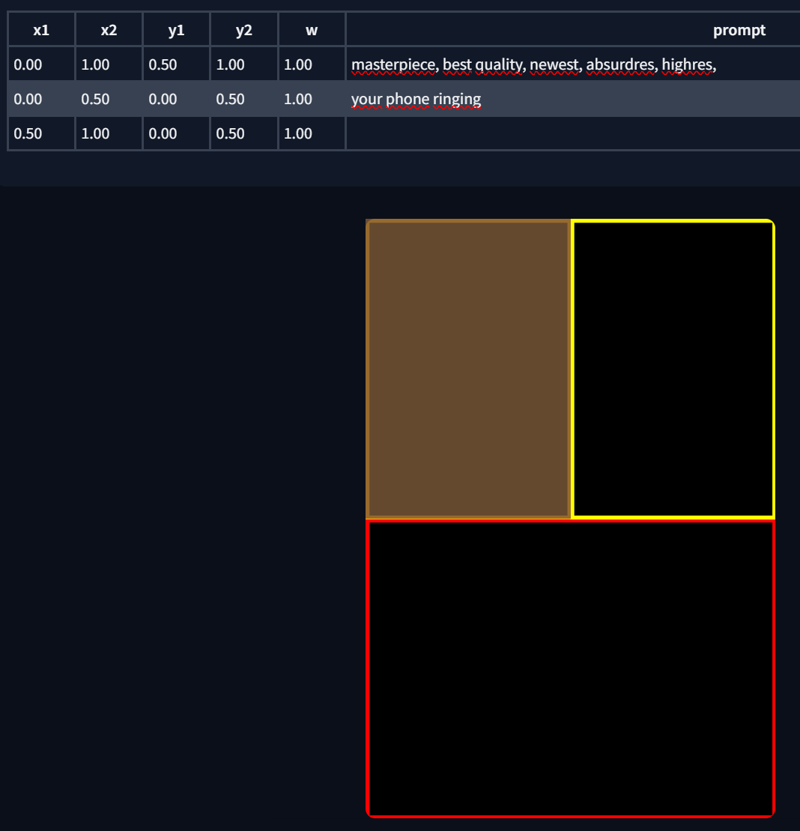
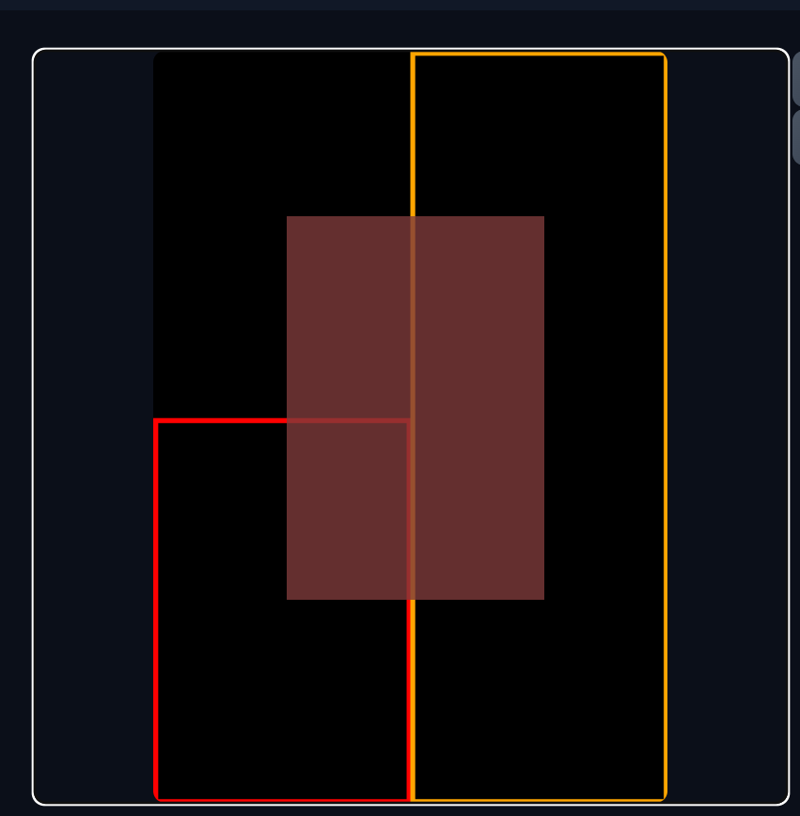
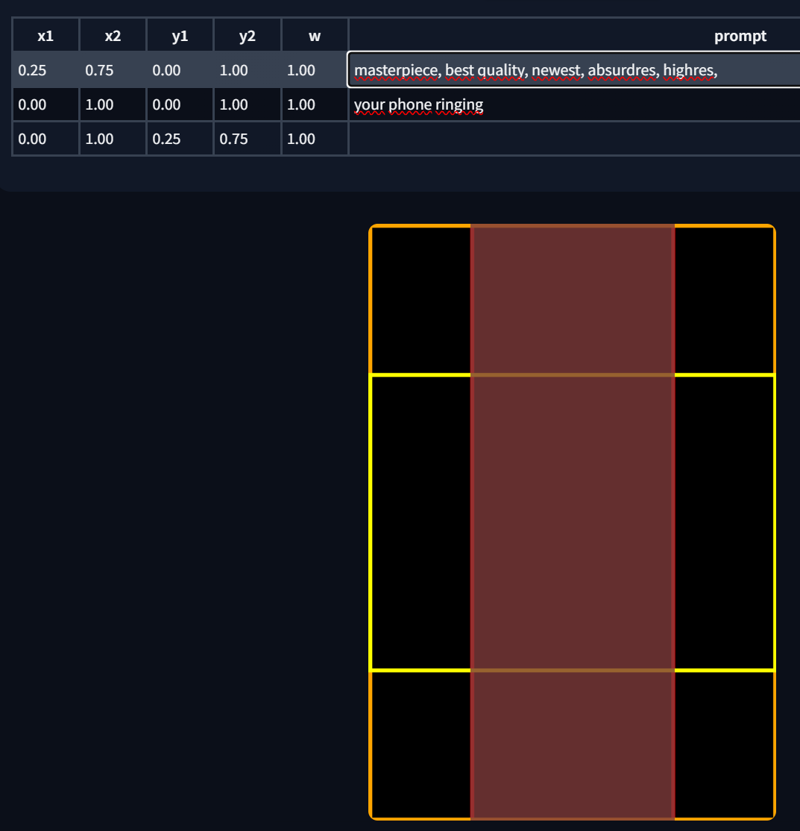 You can also edit the region directly from the template. Just highlight the corresponding region in the prompt list and make your edits. PS. Regions can also overlap.
You can also edit the region directly from the template. Just highlight the corresponding region in the prompt list and make your edits. PS. Regions can also overlap.


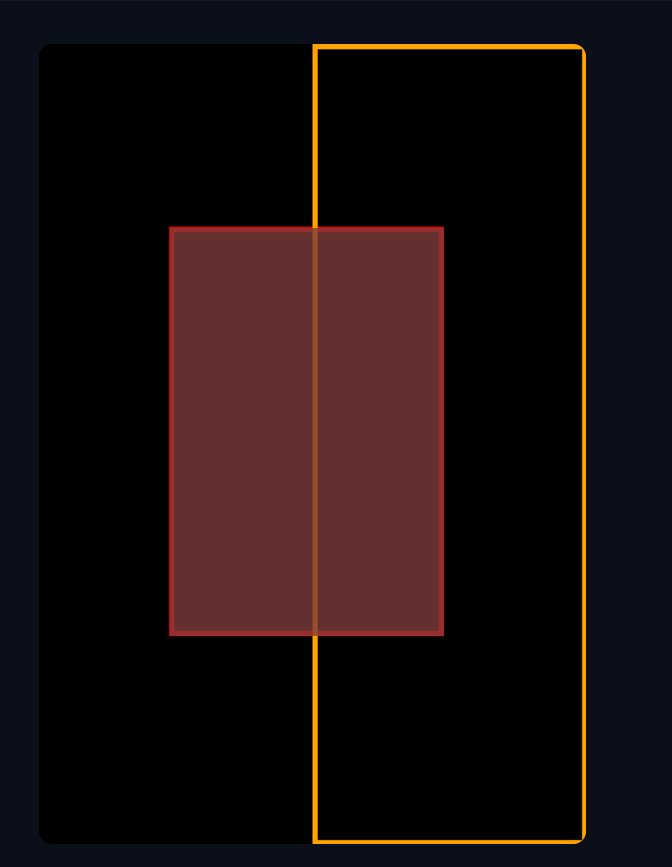
 That covers the basics of the “matrix” part. Below are some example images with their corresponding regions and metadata:
That covers the basics of the “matrix” part. Below are some example images with their corresponding regions and metadata:
masterpiece, best quality, newest, absurdres, highres, 1girl, yae miko, back-to-back, anime,
masterpiece, best quality, newest, absurdres, highres, 1girl, raiden shogun, back-to-back, realistic,
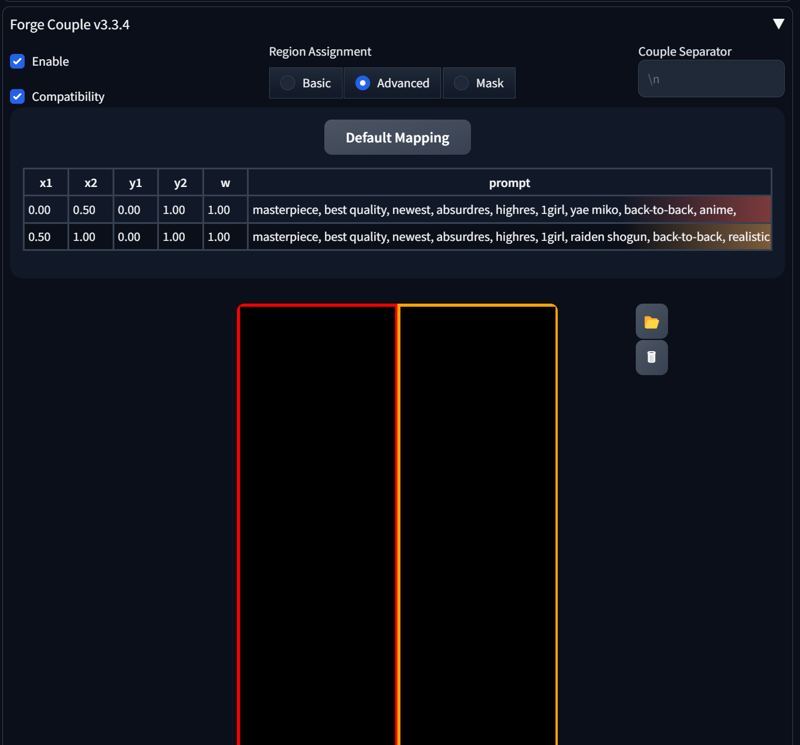
 A neat feature in Forge Couple is using LATENT, which allows you to separate styles for each region—something that wasn’t possible with the Regional Prompt Extension. Here’s an example:
A neat feature in Forge Couple is using LATENT, which allows you to separate styles for each region—something that wasn’t possible with the Regional Prompt Extension. Here’s an example:
masterpiece, best quality, newest, absurdres, highres, indoors, 1girl, SplitScreen, split screen, upper body, <lora:SplitScreen_illusXL_Incrs_v1:1>, pa-san, purple colored inner hair, ear piercing, hime cut, choker, black dress, long dress, shoulder cutout, seductive smile, green eyes, <lora:FEGBA-PortraitsV2-illus_Fp:1> portrait, pixel art,
masterpiece, best quality, newest, absurdres, highres, indoors, 1girl, SplitScreen, split screen, upper body, <lora:SplitScreen_illusXL_Incrs_v1:1>, pa-san, purple colored inner hair, ear piercing, hime cut, choker, black dress, long dress, shoulder cutout, <lora:MinimalismStyle-Illustrious-V2:1> flat color, limited palette, no lineart, no eyes,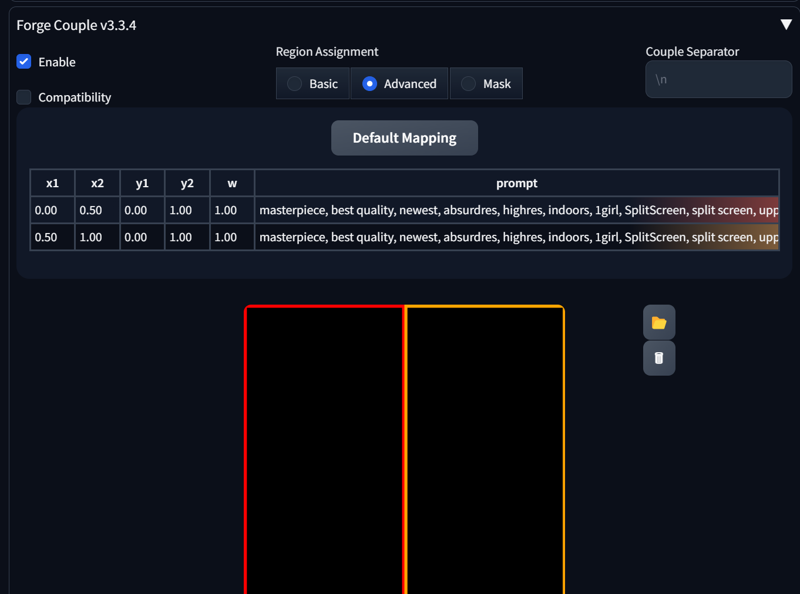
 And here’s a more complex setup:
And here’s a more complex setup:
masterpiece, best quality, newest, absurdres, highres, color wheel challenge, multiple girls, yae miko, close-up,
masterpiece, best quality, newest, absurdres, highres, color wheel challenge, multiple girls, raiden shogun, close-up,
masterpiece, best quality, newest, absurdres, highres, color wheel challenge, multiple girls, yoimiya \(genshin impact\), close-up,
masterpiece, best quality, newest, absurdres, highres, color wheel challenge, multiple girls, yelan \(genshin impact\), close-up,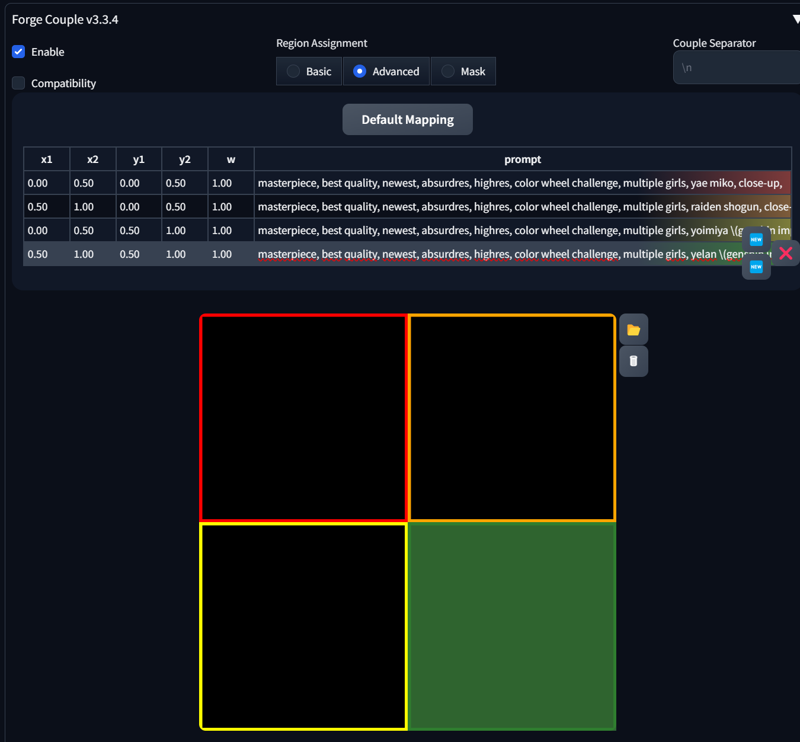
 That’s it for now. In the next section, we’ll focus on the Mask part of Forge Couple.
That’s it for now. In the next section, we’ll focus on the Mask part of Forge Couple.